本文主要是介绍Mnist模型识别自己手写数字正确率低的原因,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
做老板的助教,大三学生问的比较多的问题,记录一下。
问题背景:
有的同学用官方的训练数据mnist训练好自己的模型后,自己制作数字图片给训练好的模型识别,结果正确率只有40%多,甚至用原来训练的数据集识别正确率都低于50%.
解决方法:
可以从下面几个方面入手,把自己手写的数字识别率提高到80%不难:
原因1:西方手写体和东方手写体造成的样本差异
具体操作:我们把训练集的ubyte文件转成图片可以看到如下图

我们训练的时候用到的是 外国人写的数字,你可以看到 2 ,4 ,6 和中国人写的区别很大。找了一个图方便对比:

很明显,我们自己写出来的一些数字和原来用于训练的数字差别太大,导致识别率低,可以模仿西方数字书写提高一点识别率。
原因2:做了不恰当的图片预处理操作
如果有的同学用训练集去测试原来的模型识别率也低,那你应该是图像预处理模块出了问题。
举个例子:
我有一张训练模型时候用到的图,叫做test_0.jpg, 如下图:
 ,这里我们用7做测试,然后我把图片读进来测试模型的识别率,第一次我把图像做一次归一化,第二次我不做归一化,分别送给模型去识别。两次结果如下图:
,这里我们用7做测试,然后我把图片读进来测试模型的识别率,第一次我把图像做一次归一化,第二次我不做归一化,分别送给模型去识别。两次结果如下图:
做了归一化结果:

可以看到把训练数据的7识别成了8
未做归一化结果:

可以看到我们把归一化那一行注释掉了之后,就识别正确了,很多训练集识别率都出了问题的,都是自己加了错误的预处理造成的,为什么?
因为:我们把图片 读到matlab中,此时未做归一化处理,结果如下图
读到matlab中,此时未做归一化处理,结果如下图

,很明显,这是一个 数字 7 的轮廓。现在我把它进行归一化,这里我使用其中一个同学的归一化代码演示,代码如下
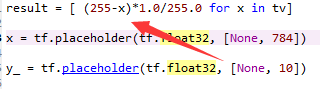
他是用255减去每个像素值/(max(pixel)-min(pixel)) 的方式进行归一化。
归一化之数据和图形如下:

用imshow() 显示为 ,归一化之后变成了白底黑字,为什么?因为如果原来是黑色,假如像素值为0, (255-0)/255,变成了1, 然后0~1之间1最大,所以颜色反转了,你用这个7去给模型识别,自然而然识别不出来,识别结果如下:
,归一化之后变成了白底黑字,为什么?因为如果原来是黑色,假如像素值为0, (255-0)/255,变成了1, 然后0~1之间1最大,所以颜色反转了,你用这个7去给模型识别,自然而然识别不出来,识别结果如下:
把7认成了8

这个例子不是说不能做图片预处理,是说要进行正确的预处理。
建议用photoshop的柔性画笔制作自己的样本,我测了,识别率很高。
总结:
1、尽量模仿西方数字的书写,书写的位置尽量位与28*28的中央,建议用photoshop的柔性画笔书写。
2、小心你的图片预处理过程,这可能是你识别率低的罪魁祸首
3、你可以把所有的训练图片处理成2值图,然后给模型训练,测试图片也用2值图,就是只有0和1,没有0~1之间的任何数,避免了图片预处理导致的识别率下降,识别率会极大提升。
这篇关于Mnist模型识别自己手写数字正确率低的原因的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





