本文主要是介绍Kettle:千亿数据仓库整合大数据平台[不学白不学]!!!保证你收益匪浅,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Kettle整合大数据平台
Kettle整合Hadoop:
- Hadoop环境准备
- 查看hadoop的文件系统
- 通过浏览器访问
http://node1:50070/ - 通过终端访问
hadoop fs -ls / # 查看文件
- 在hadoop文件系统中创建/hadoop/test目录
hadoop fs -mkdir -p /hadoop/test
- 在本地创建1.txt
vim 1.txt
id,name
1,itheima
2,itcast
- 上传1.txt到hadoop文件系统的/hadoop/test目录
hadoop fs -put 1.txt /hadoop/test
kettle与hahoop环境整合
1、确保Hadoop的环境变量设置好HADOOP_USER_NAME为root
2、从hadoop下载核心配置文件
sz /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/hdfs-site.xml
sz /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/core-site.xml
文件会被下载到windows的下载目录
3、把hadoop核心配置文件放入kettle目录
data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\cdh514
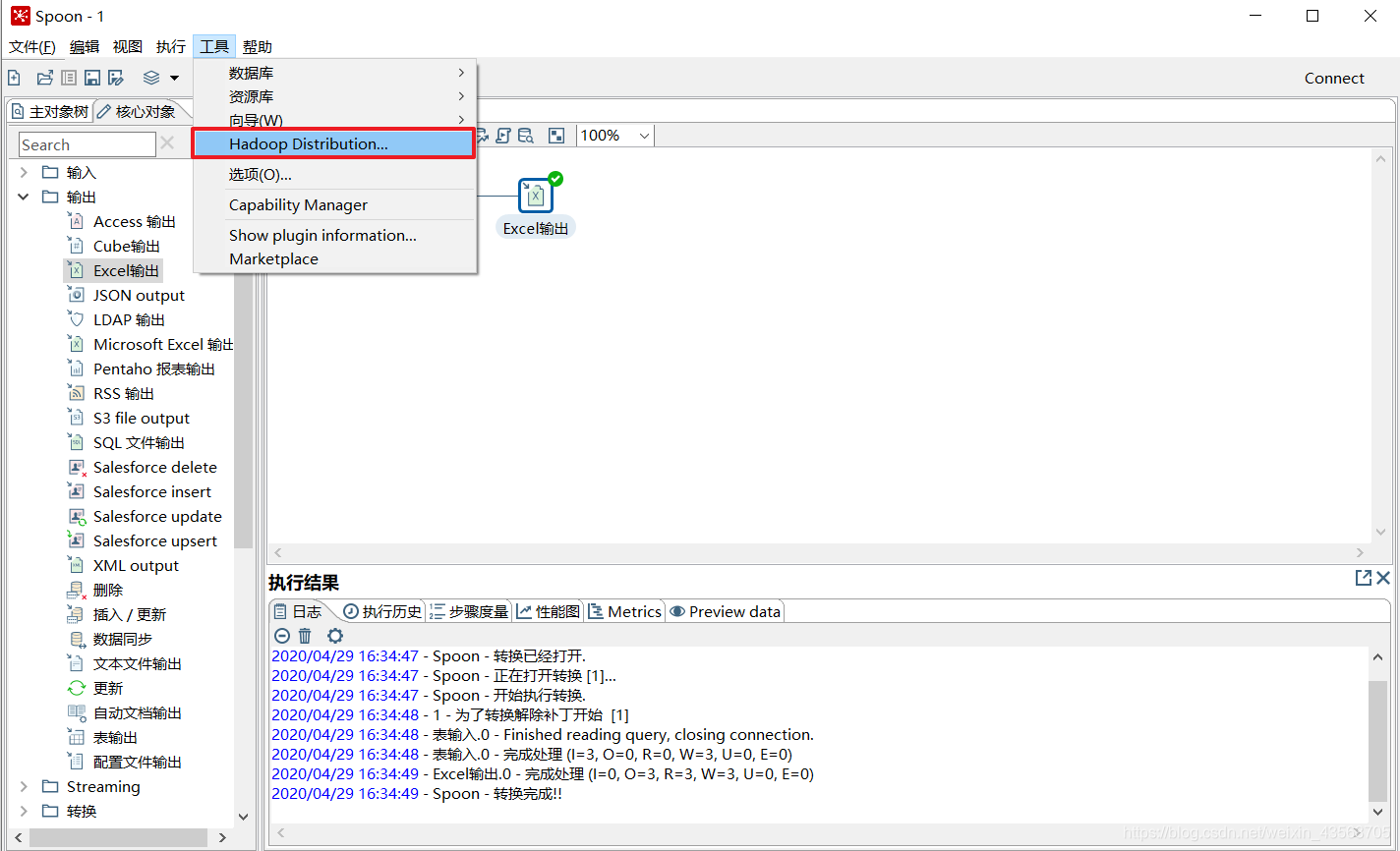
4、修改 data-integration\plugins\pentaho-big-data-plugin\plugin.properties文件
- 修改plugin.properties
active.hadoop.configuration=cdh514
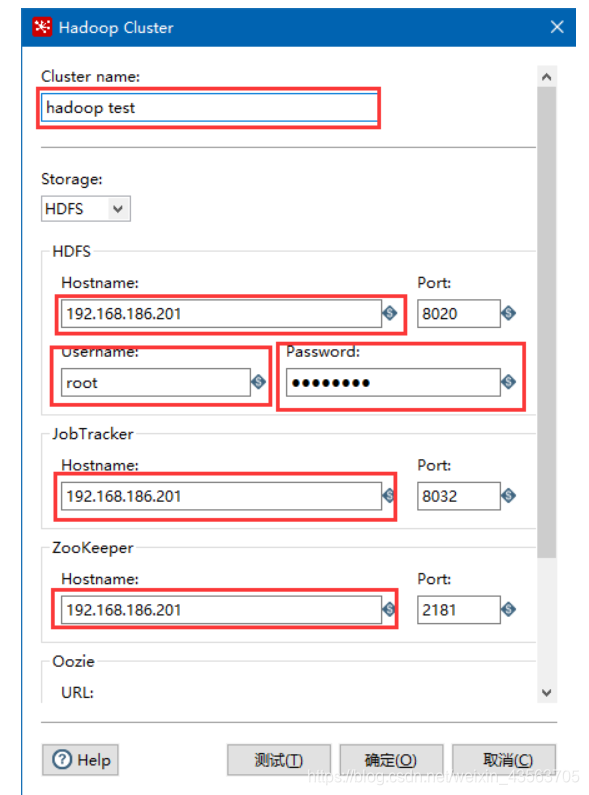
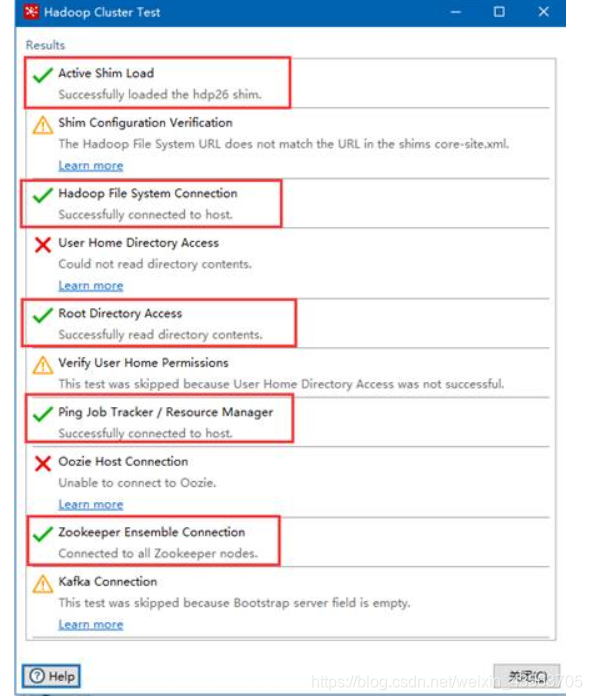
5、 创建Hadoop clusters
Hadoop file input组件
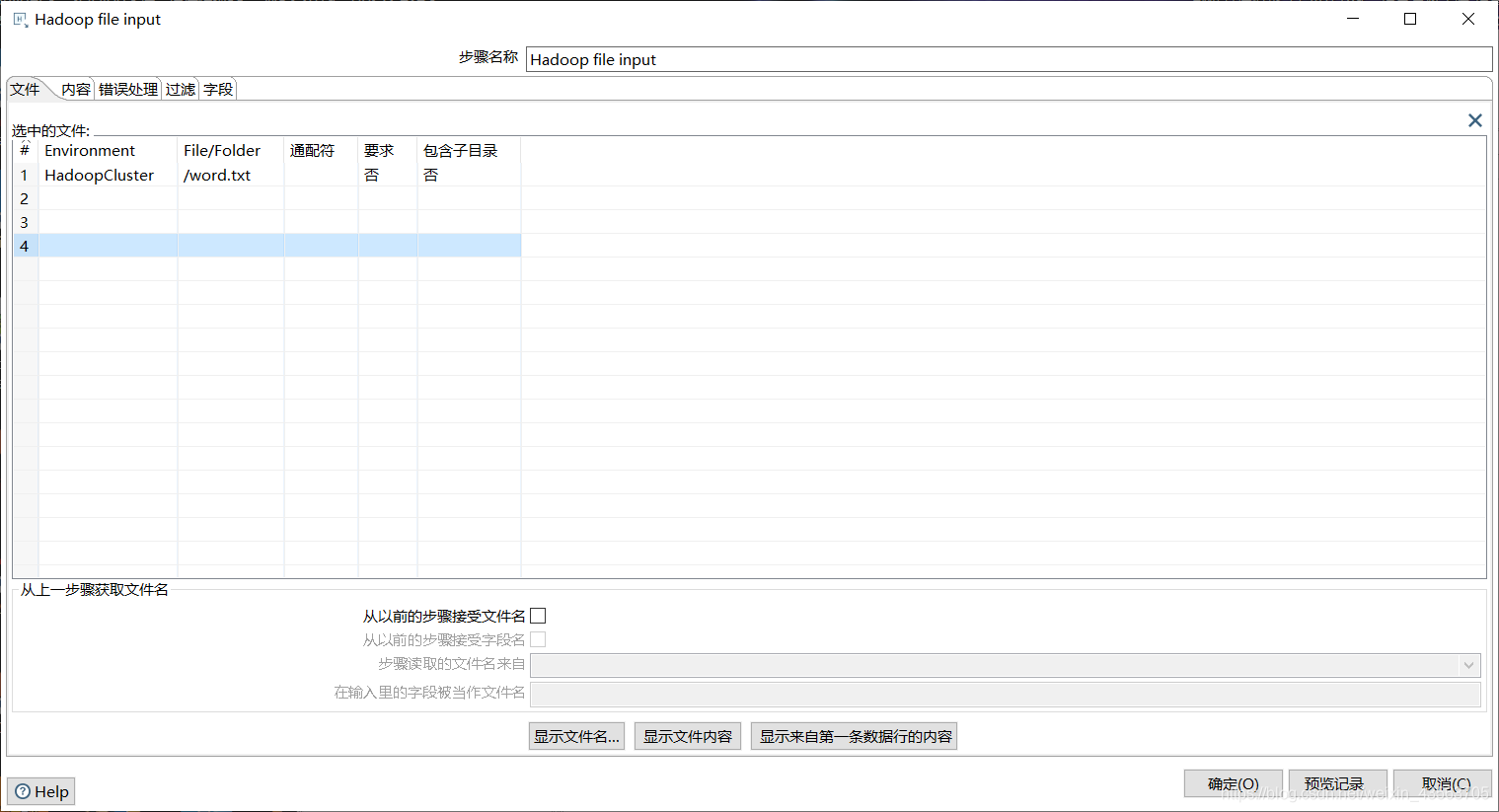
Kettle在Big data分类中提供了一个Hadoop file input 组件用来从hdfs文件系统中读取数据。

需求:
- 从Hadoop文件系统读取/hadoop/test/1.txt文件,把数据输入到Excel中。
实现步骤:
1、拖入以下组件

2、配置Hadoop File Input组件
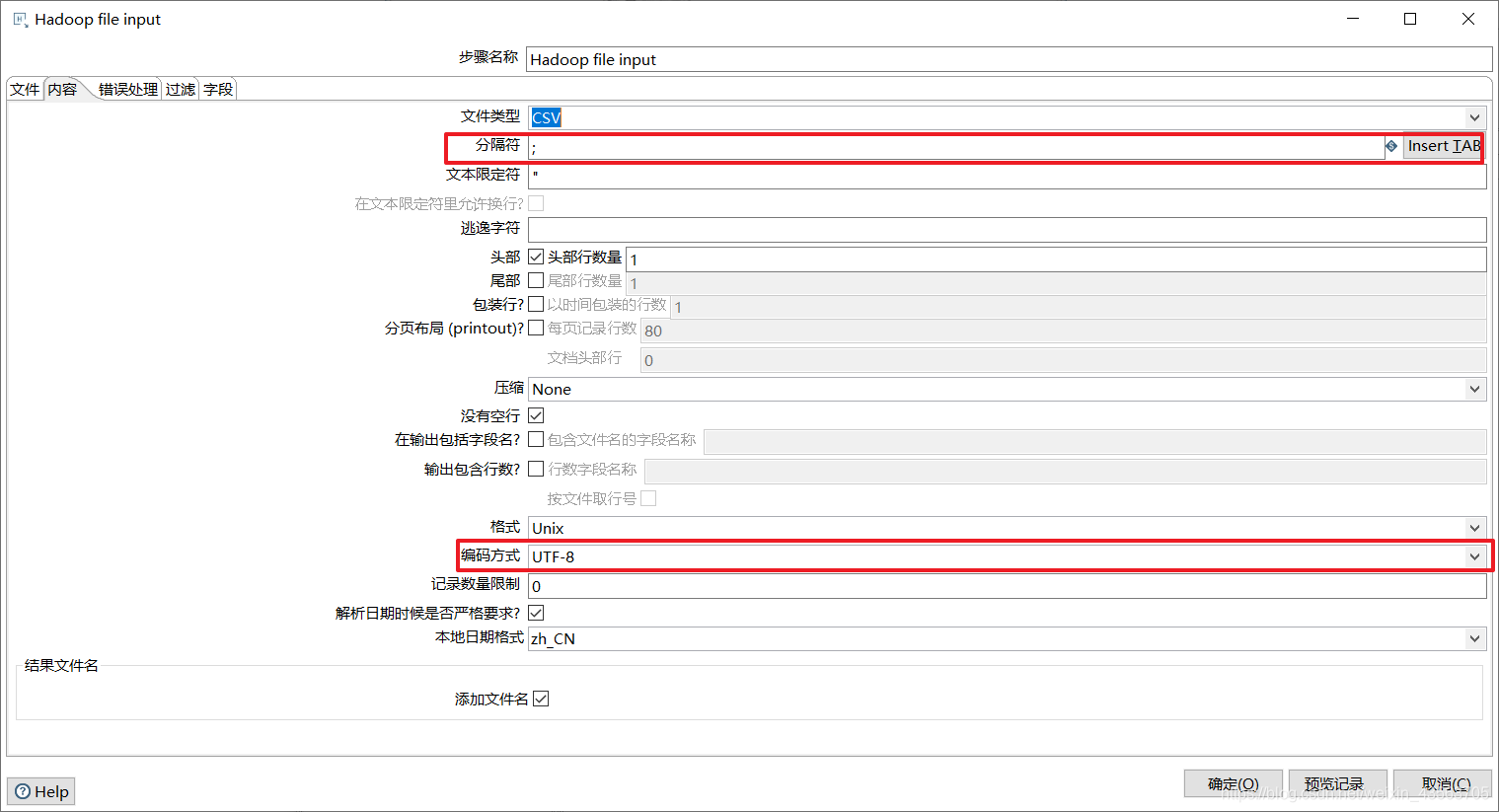
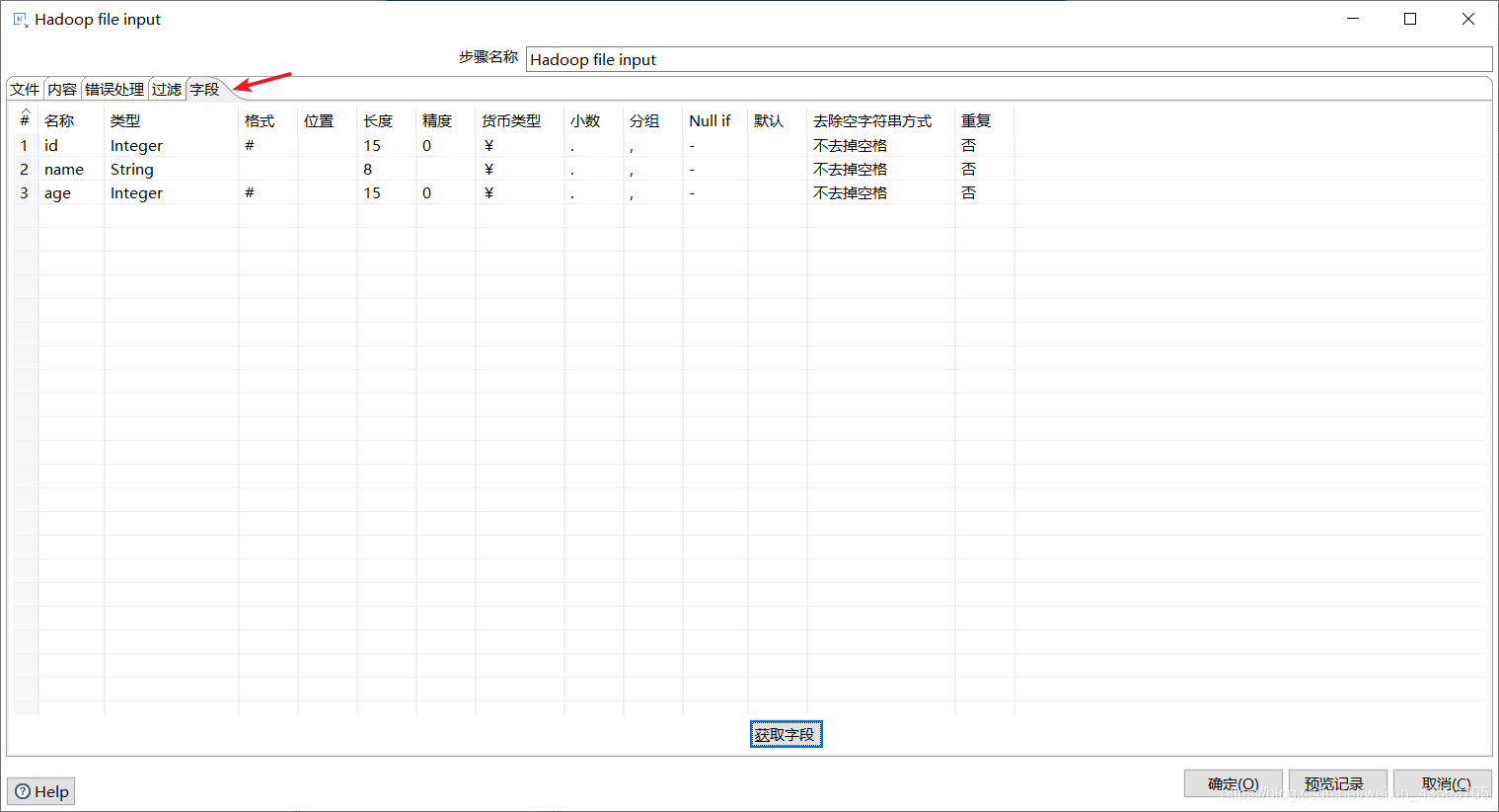
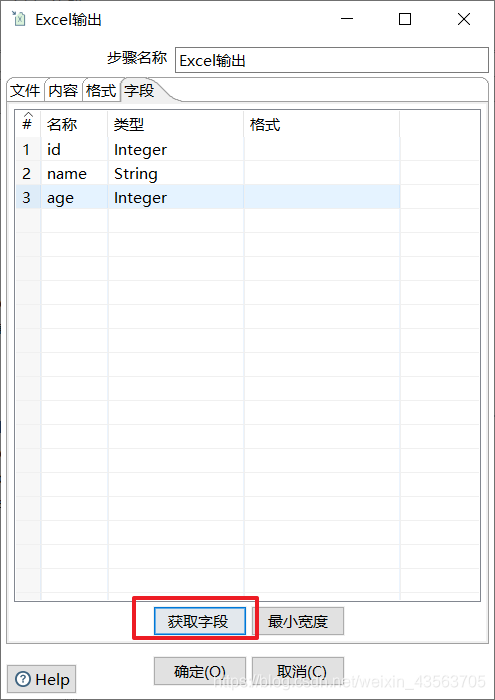
Hadoop file output组件
Kettle在Big data分类中提供了一个Hadoop file output 组件用来向hdfs文件系统中保存数据

需求:
- 读取 user.json 把数据写入到hdfs文件系统的的/hadoop/test/2.txt中。
实现步骤:
1、拖入以下组件

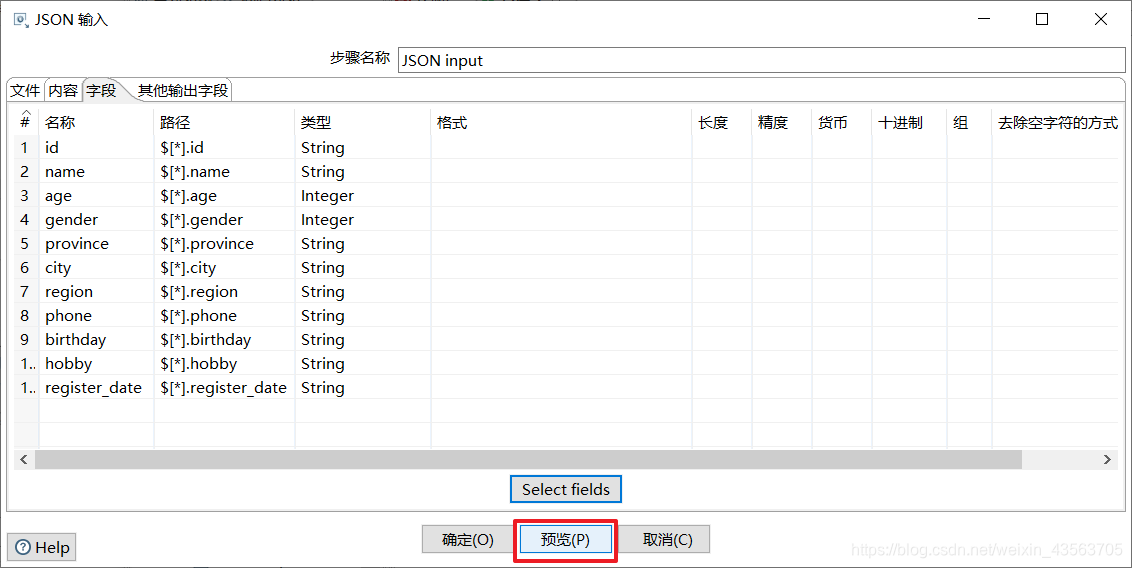
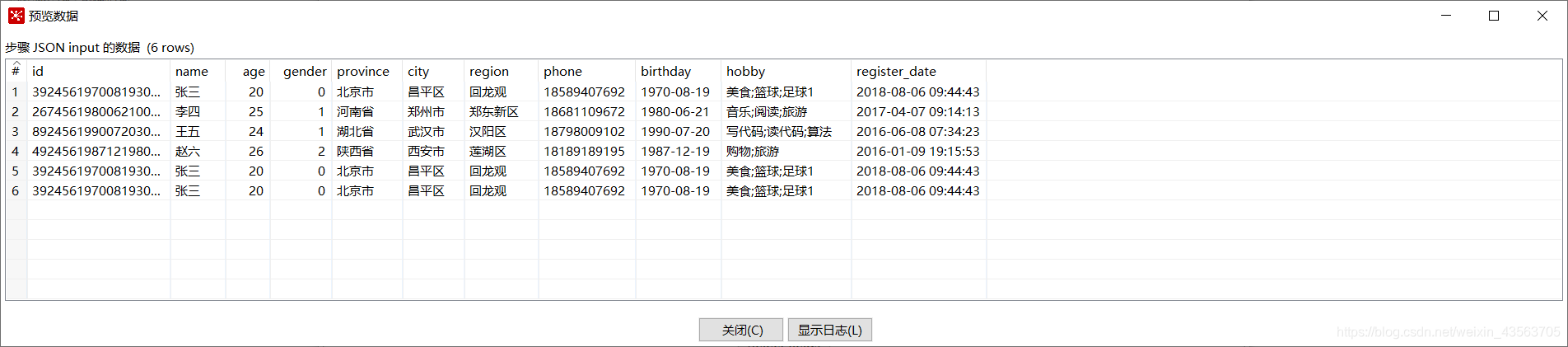
2、配置 JSON 输入组件
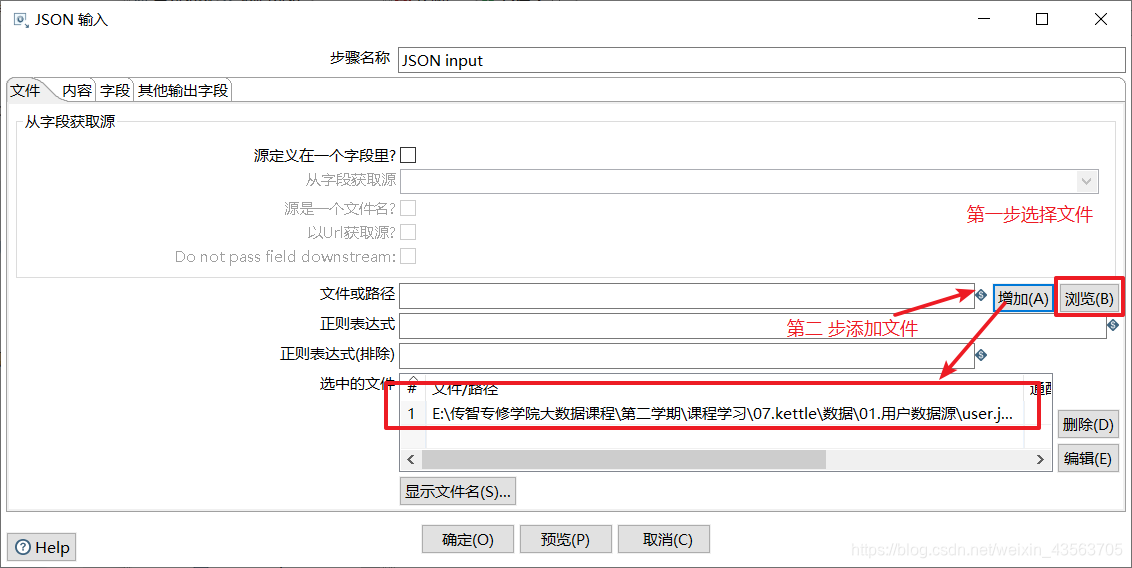
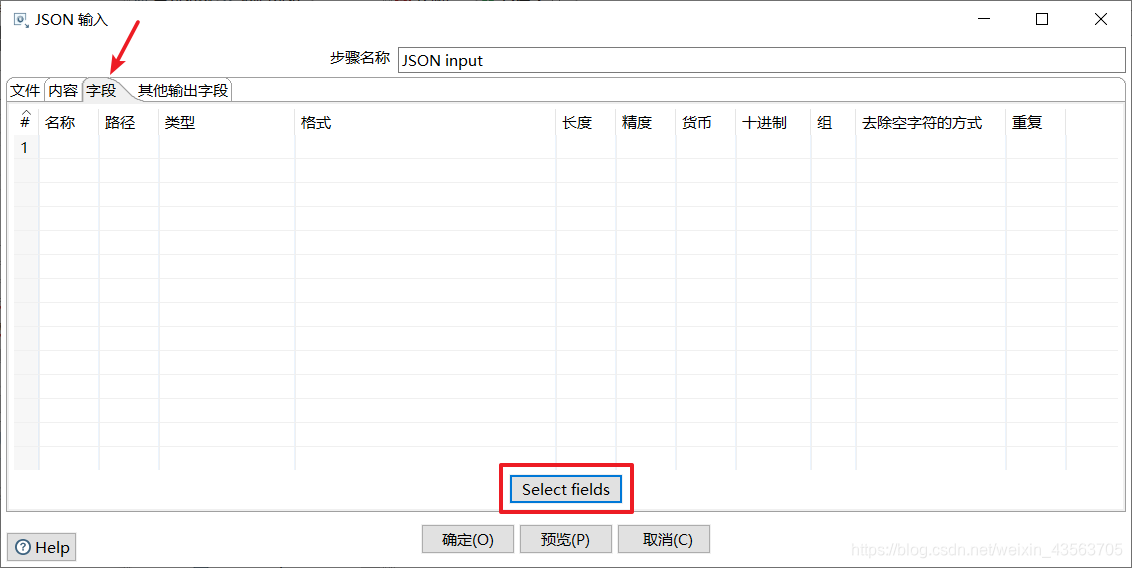
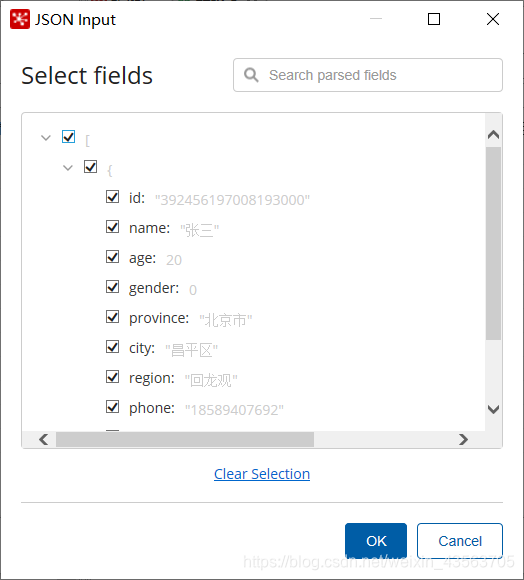
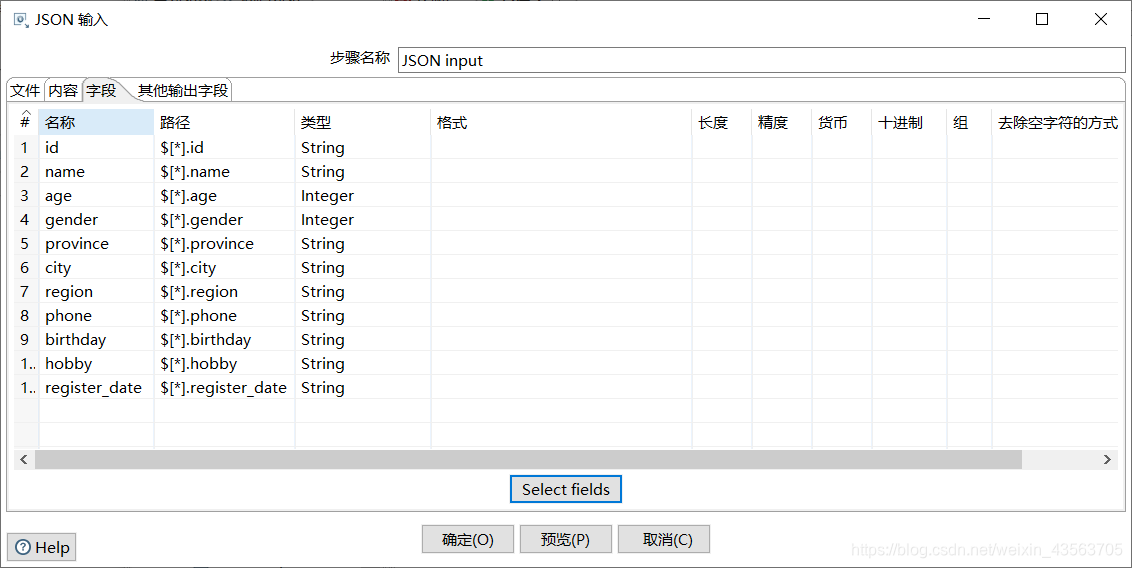
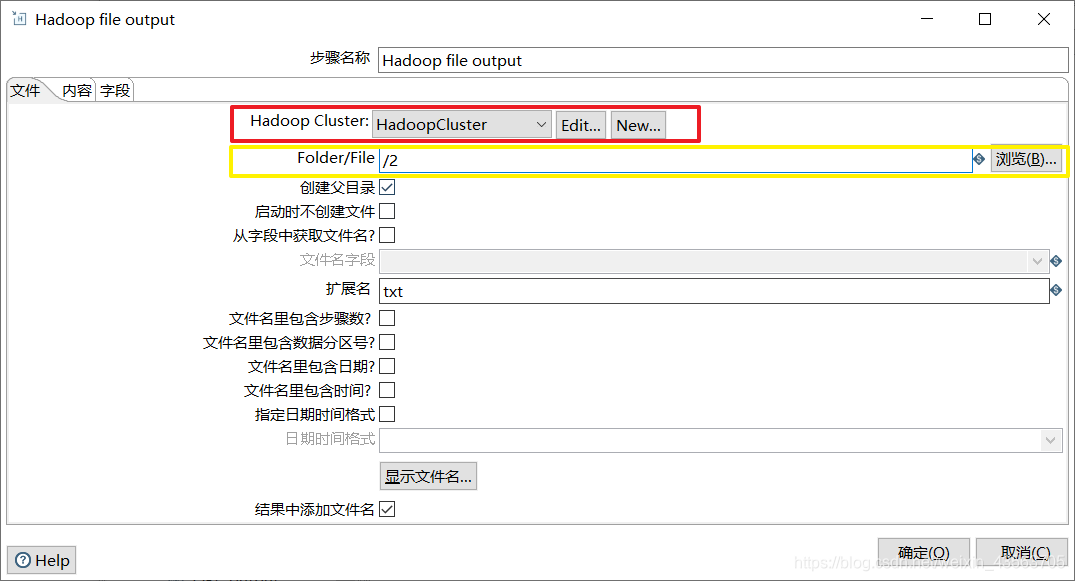
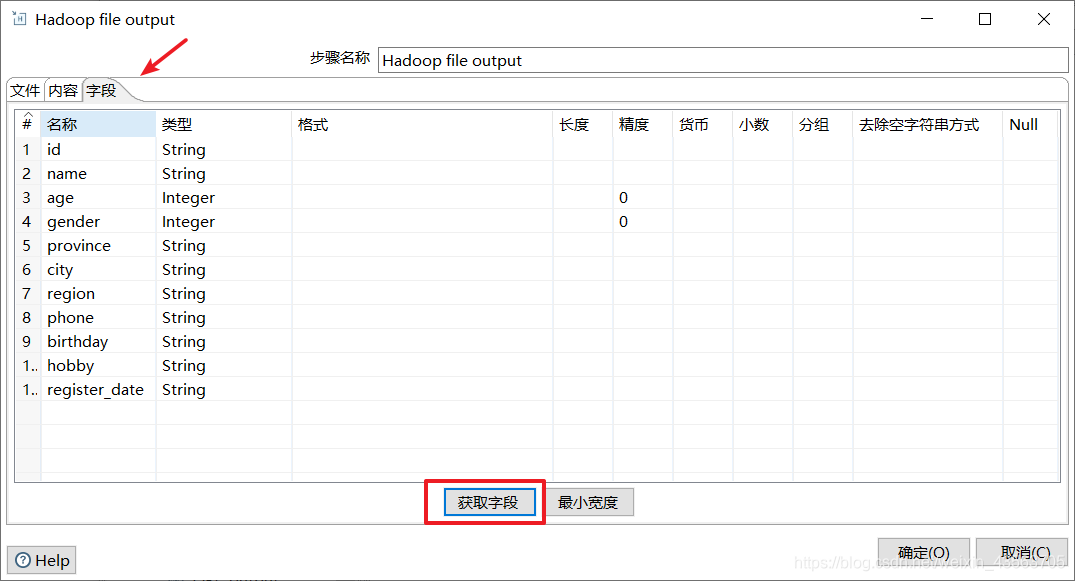
3、配置Hadoop file output组件

Kettle整合Hive
启动hive:
hive --service hiveserver2 &
hive --service metastore &
初始化数据
-
连接hive
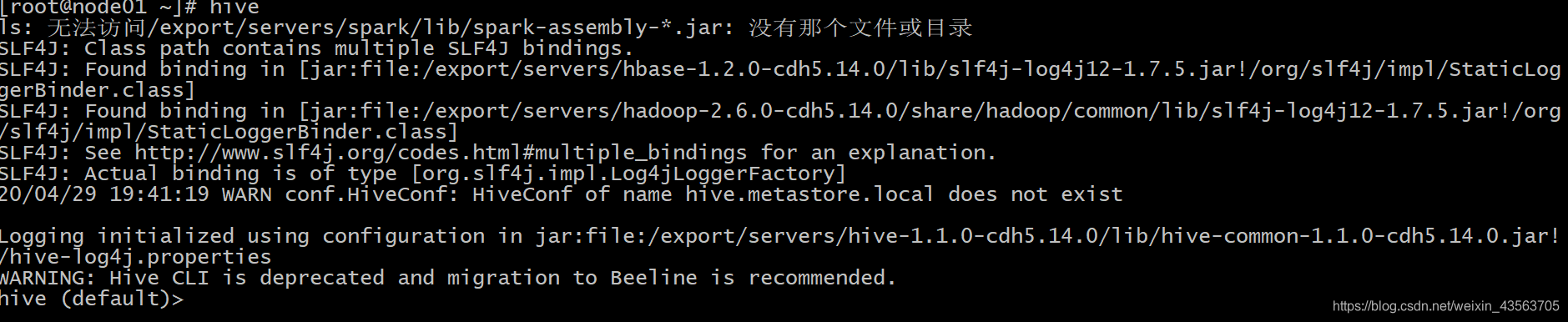
-
创建并切换数据库
create database test;
use test;
- 创建表
create table a(a int,b int
)
row format delimited fields terminated by ',' stored as TEXTFILE;
show tables;
- 创建数据文件
vim a.txt
1,11
2,22
3,33
- 从文件加载数据到表
load data local inpath '/root/a.txt' into table a;
- 查询表
select * from a;
kettle与Hive整合
1、从虚拟机下载Hadoop的jar包
sz /export/servers/hadoop-2.6.0-cdh5.14.0/share/hadoop/common/hadoop-common-2.6.0-cdh5.14.0.jar
2、把jar包放置在\data-integration\lib目录下
3、重启kettle,重新加载生效
从hive中读取数据
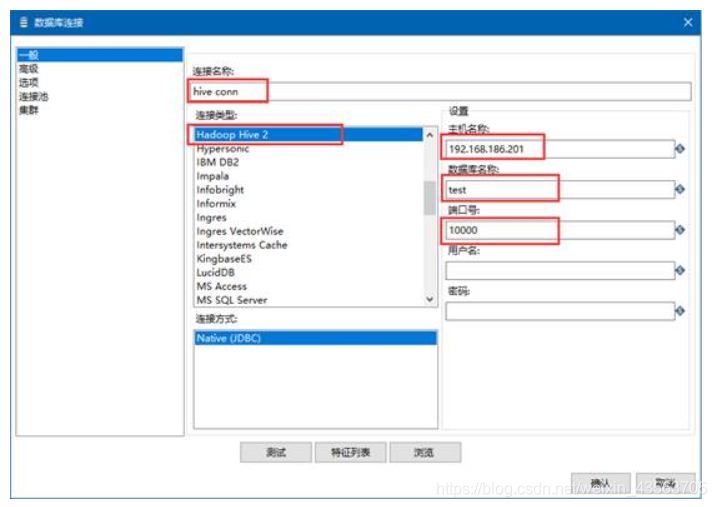
- hive数据库是通过jdbc来进行连接,可以通过表输入控件来获取数据。
需求: - 从hive数据库的test库的a表中获取数据,并把数据保存到Excel中。
实现步骤:
1、设计一下kettle组件结构

2、配置表输入组件
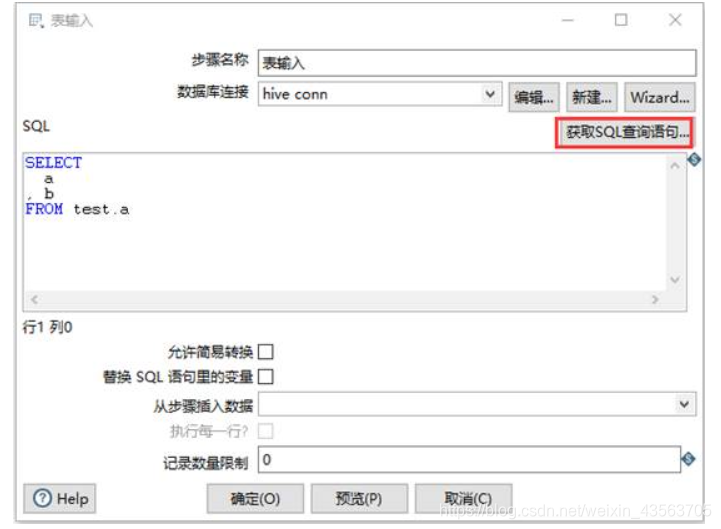
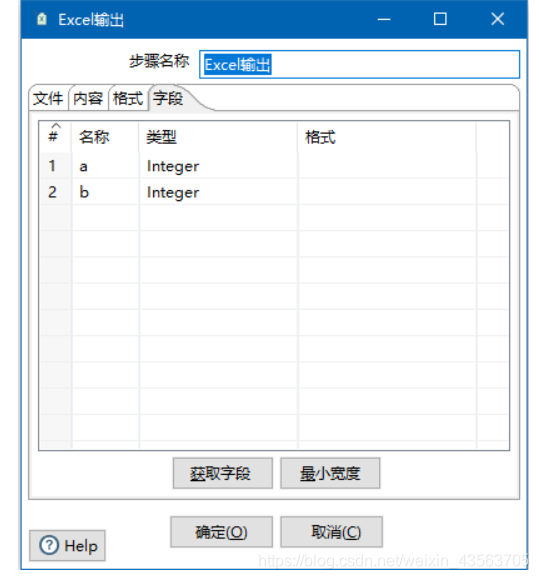
把数据保存到hive数据库
hive数据库是通过jdbc来进行连接,可以通过表输出控件来保存数据。
需求:
- 从Excel中读取数据,把数据保存在hive数据库的test数据库的a表。
实现步骤:
1、设计如下kettle组件结构

2、配置 Excel输入组件
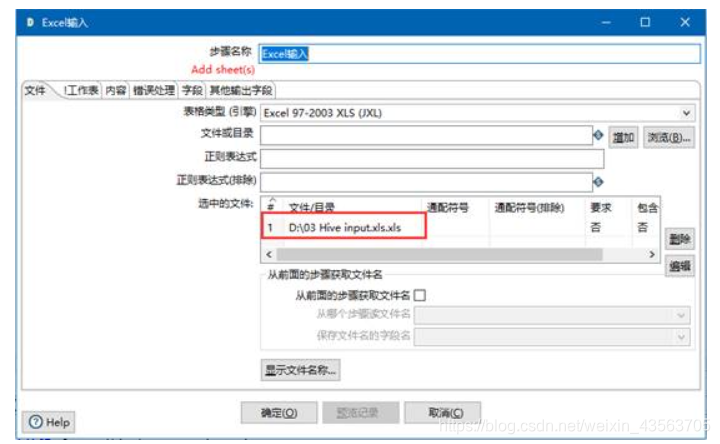
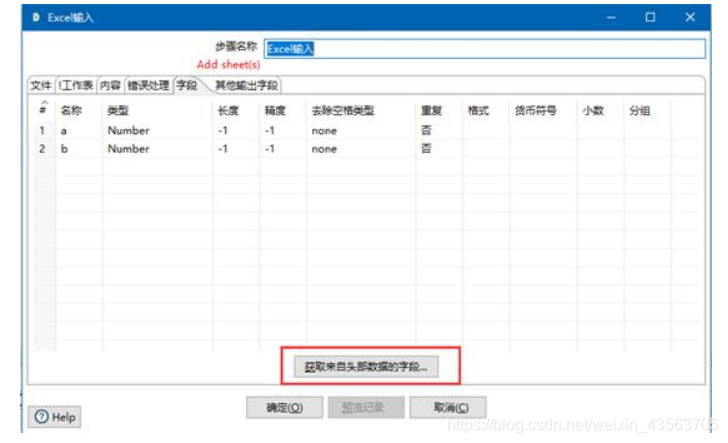
2、配置表输出组件
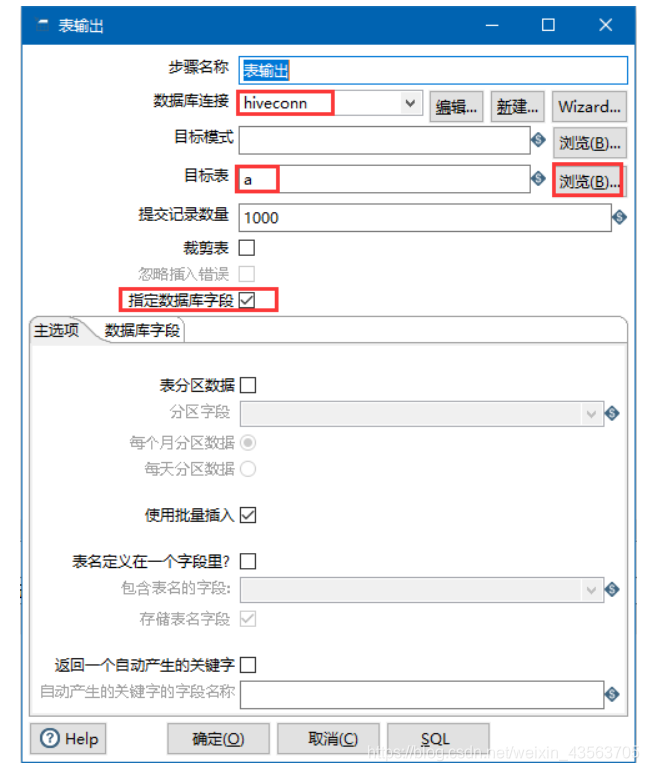
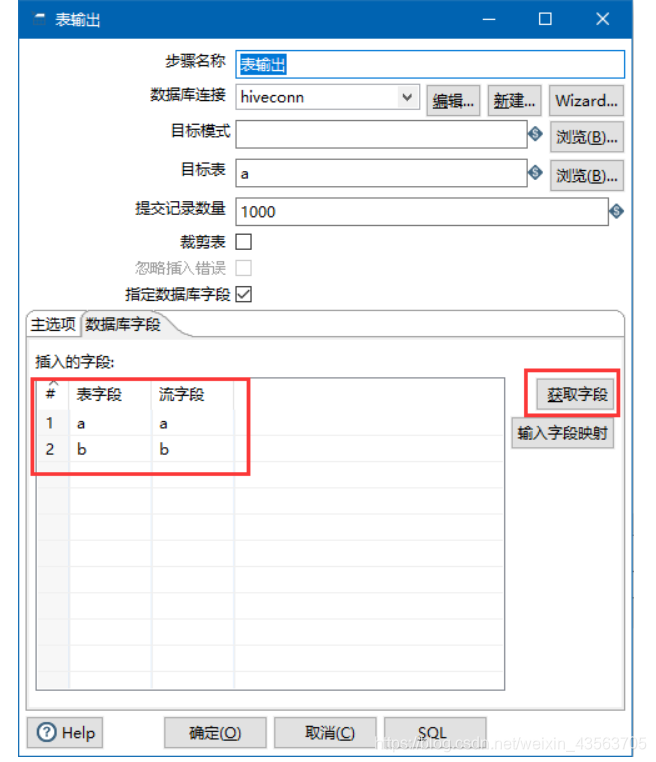
验证:

执行Hive的HiveSQL语句:
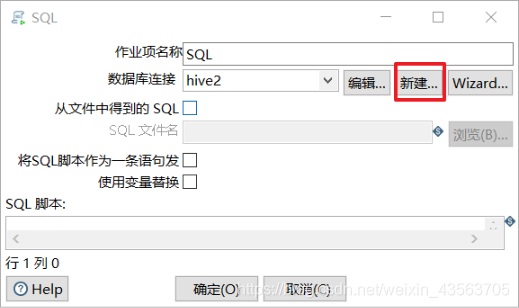
Kettle中可以执行Hive的HiveSQL语句,使用作业的SQL脚本。
需求:
- 聚合查询a表表中a字段大于1的数据,同时建立一个新表new_a保存查询数据。
实现步骤:
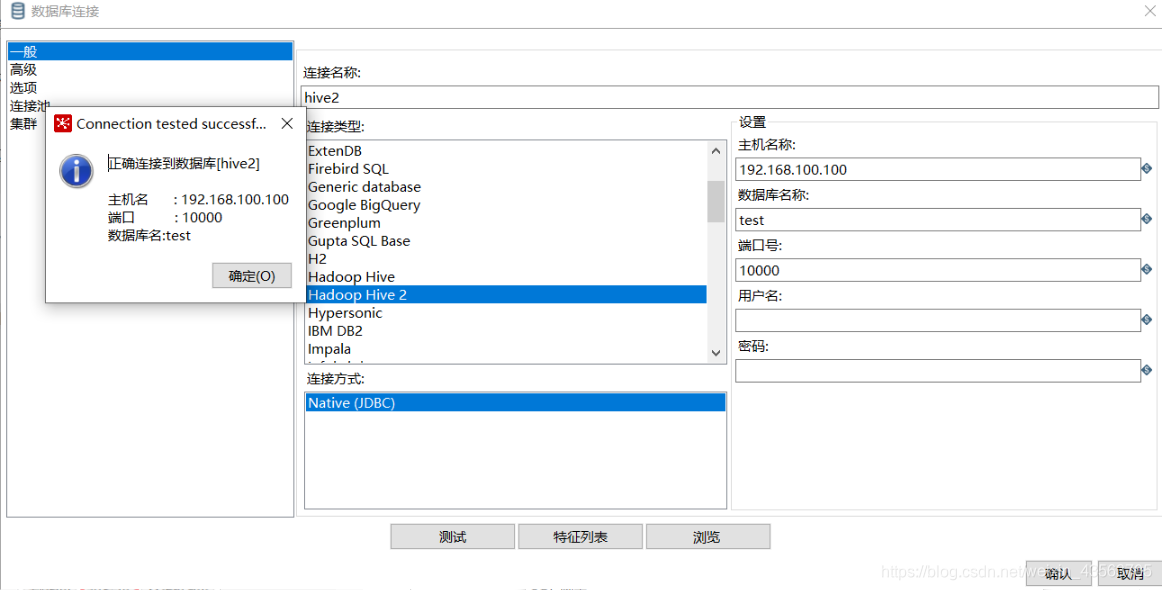
1、设计如下作业组件结构

这篇关于Kettle:千亿数据仓库整合大数据平台[不学白不学]!!!保证你收益匪浅的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



