本文主要是介绍python机器学习之降维算法PCA(高维数据的可视化,鸢尾花案例),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
高维数据的可视化
n_components是我们降维后需要的维度,即降维后需要保留的特征数量,降维流程中第二步里需要确认的k值,一般输入[0, min(X.shape)]范围中的整数。
调用库和模块
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
提取数据集
iris = load_iris()
x = iris.data
y = iris.targetx.shape#作为数据表或特征矩阵,x是几维
import pandas as pd
pd.DataFrame(x)
建模 调用PCA
pca = PCA(n_components=2)#实例化
pca = pca.fit(x)#拟合模型
x_dr = pca.transform(x)#获取新矩阵
#也可以一步到位
#x_dr = PCA(2).fit_transform(x)
x_dr
可视化
x_dr[y ==0,0]#采用布尔索引#画出分类图
plt.figure()#创建一个画布
plt.scatter(x_dr[y==0,0],x_dr[y==0,1],c="red",label = iris.target_names[0])
plt.scatter(x_dr[y==1,0],x_dr[y==1,1],c = "black",label = iris.target_names[1])
plt.scatter(x_dr[y==2,0],x_dr[y==2,1],c="orange",label = iris.target_names[2])
plt.legend()#显示图例
plt.title("PCA of IRIS dataset")#显示标题
plt.show()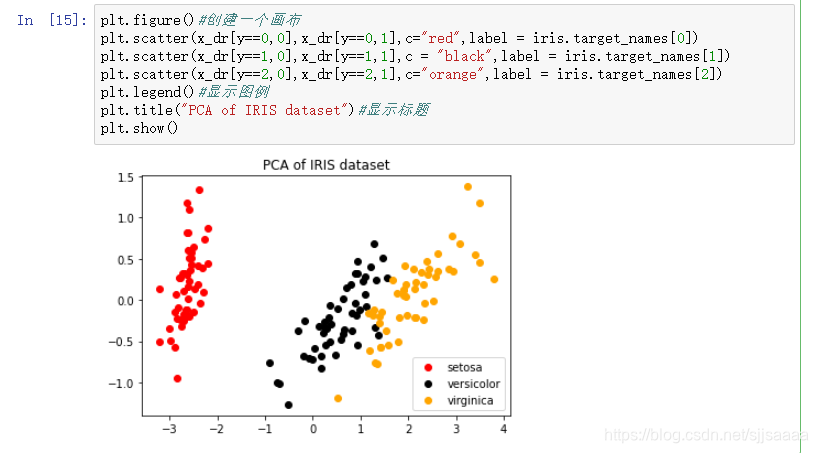
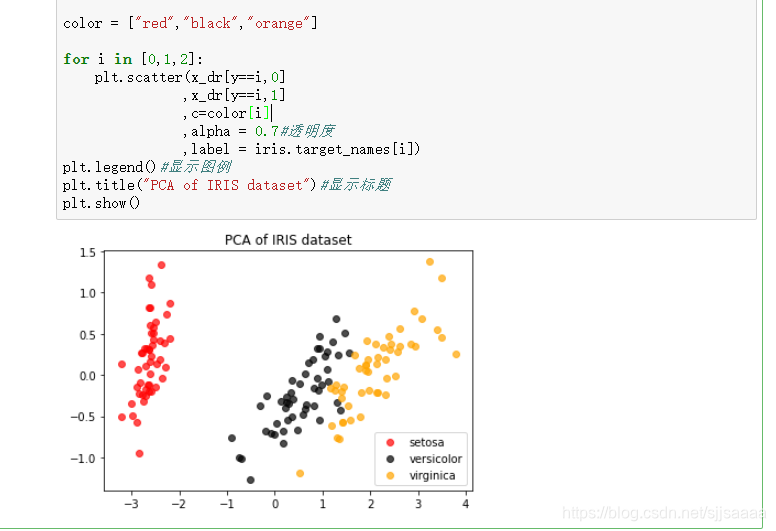
也可以调用循环.
color = ["red","black","orange"]for i in [0,1,2]:plt.scatter(x_dr[y==i,0],x_dr[y==i,1],c=color[i],alpha = 0.7#透明度,label = iris.target_names[i])
plt.legend()#显示图例
plt.title("PCA of IRIS dataset")#显示标题
plt.show()
探索降维后的数据
pca.explained_variance_# 查看降维后每个新特征向量上所带的信息量大小(方差大小)
pca.explained_variance_ratio_#查看降维后每个新特征向量所占的信息量占原始数据总信息量的百分比
pca.explained_variance_ratio_.sum()#总占比

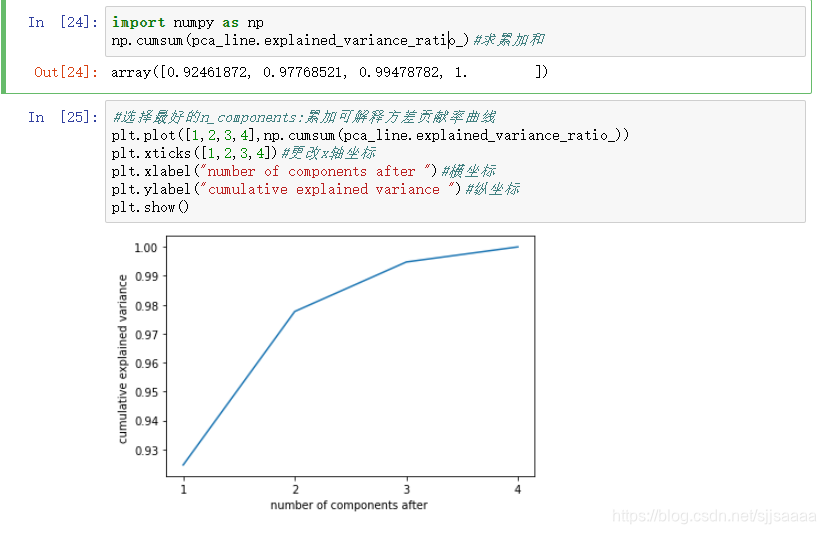
选择最好的n_components:累积可解释方差贡献率曲线
当参数components中不填写任何值,则默认返回min(X.shape)个特征,一般来说,样本量都会大于特征数目,所以什么都不填就相当于转换了新特征空间,但没有减少特征的个数。一般来说,不会使用这种输入方式。但我们却可以使用这种输入方式来画出累计可解释方差贡献率曲线,以此选择最好的n_components的整数取值。
累积可解释方差贡献率曲线是一条以降维后保留的特征个数为横坐标,降维后新特征矩阵捕捉到的可解释方差贡献率为纵坐标的曲线,能够帮助我们决定n_components最好的取值。
import numpy as np
np.cumsum(pca_line.explained_variance_ratio_)#求累加和#选择最好的n_components:累加可解释方差贡献率曲线
plt.plot([1,2,3,4],np.cumsum(pca_line.explained_variance_ratio_))
plt.xticks([1,2,3,4])#更改x轴坐标
plt.xlabel("number of components after ")#横坐标
plt.ylabel("cumulative explained variance ")#纵坐标
plt.show()
最大似然估计自选超参数
#最大似然估计自选超参数
pca_mle = PCA(n_components="mle")
pca_mle = pca_mle.fit(x)
x_mle = pca_mle.transform(x)
x_mle#系统帮我们自动选择了3个特征pca_mle.explained_variance_ratio_.sum()#查看降维后每个新特征向量所占的信息量占原始数据总信息量的百

按信息量占比选超参数
pca_f = PCA(n_components=0.97,svd_solver="full")
pca_f = pca_f.fit(x)#拟合模型
x_f = pca_f.transform(x)#导出结果
x_f #二维pca_f.explained_variance_ratio_

这篇关于python机器学习之降维算法PCA(高维数据的可视化,鸢尾花案例)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








