高维专题

Eigen::Tensor使用,定义高维矩阵
在实际项目中,需要存储大于等于三维的矩阵,而平常中我们使用Eigen::MatrixXd二维数据,这里我们使用Eigen::Tensor来定义 1.Using the Tensor module #include <unsupported/Eigen/CXX11/Tensor> 2.定义矩阵 2.一般矩阵 官方文档 // 定义一个2x3x4大小的矩阵Eigen::Tensor<f

发表在SIGMOD 2024上的高维向量检索/向量数据库/ANNS相关论文
前言 SIGMOD 2024会议最近刚在智利圣地亚哥结束,有关高维向量检索/向量数据库/ANNS的论文主要有5篇,涉及混合查询(带属性或范围过滤的向量检索)优化、severless向量数据库优化、量化编码优化、磁盘图索引优化。此外,也有一些其它相关论文,比如FedKNN: Secure Federated k-Nearest Neighbor Search。 下面对这些论文进行一个简单汇总介绍
[LightOJ 1364] Expected Cards (高维期望DP)
LightOJ - 1364 一副扑克牌,不断地从中抽牌 要求四种花色都至少要有给定的张数 其中如果抽到了王牌,可以将其变为任意花色 求满足条件时,抽出的期望张数 刚开始想错了,两张王牌并非在一开始就给定了 而是在游戏中可以视当前情况选择着变的 这两种方式是不一样的 由于牌数其实并不会很多, 复杂度乘一乘发现才 107 10^7级别的,所以直接暴力DP 将两张王牌当
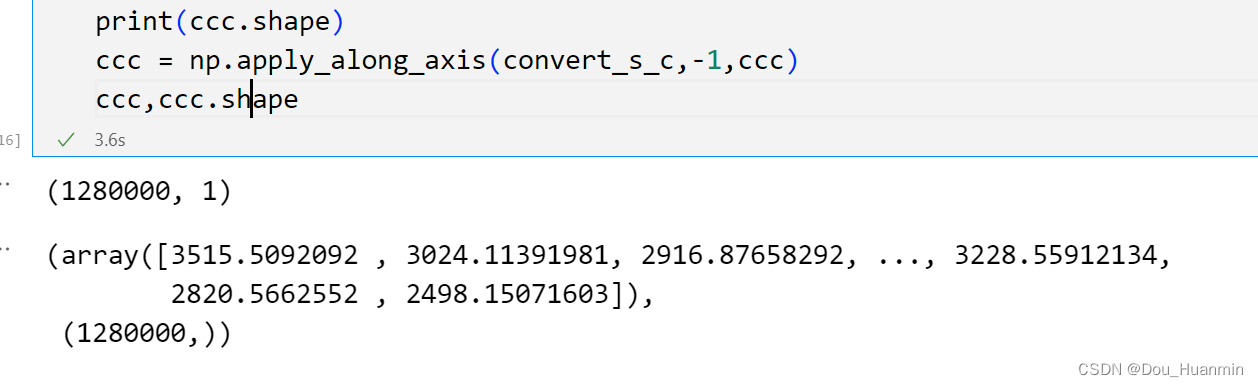
避免使用for循环操作高维数组:numpy.apply_along_axis用法
文章目录 场景实际操作编写相关函数np.apply_along_axis 场景 设想我有一列高维向量,读取之后的数据都是字符串变量,我需要把这些字符串数据转换为复数之后求绝对值 实际操作 在使用pd.read_csv()读取数据之后,将这一列数据转换为numpy数组 data = pd.read_csv(path,header=3).to_numpy() # heade

【U-Net验证】逐元素乘积将特征投射到极高维隐式特征空间的能力
写在前面:本博客仅作记录学习之用,部分图片来自网络,如需使用请注明出处,同时如有侵犯您的权益,请联系删除! 文章目录 前言网络结构编码结构解码结构代码 实验实验设置w/o-ReLU的性能比较with-ReLU的性能比较 总结致谢参考 前言 在深度学习领域,网络架构的创新和性能的提升一直是研究的热点。在传统的神经网络设计中,激活函数扮演着至关重要的角色,它们为网络引入了

一种面向高维数据的继承聚类算法
一种面向高维数据的集成聚类算法 聚类集成已经成为机器学习的研究热点,它对原始数据集的多个聚类结果进行学习和集成,得到一个能较好地反映数据集内在结构的数据划分。很多学者的研究证明聚类集成能有效地提高聚类结果的准确性、鲁棒性和稳定性。本文提出了一种面向高维数据的聚类集成算法。该方法针对高维数据的特点,先用分层抽样的方法结合信息增益对每个特征簇选择合适数量比较重要的特征的生成新的具代表意义的

TensorBoard-PROJECTOR-高维向量可视化
TensorBoard-PROJECTOR-高维向量可视化 PROJECTOR用于将高维向量进行可视化,通过PCA,T-SNE等方法将高维向量投影到三维坐标系。 具体操作和解释见代码和注释: import tensorflow as tfimport mnist_inferenceimport osfrom tensorflow.contrib.tensorboard.plugin
嵌入(embeddings)将离散的标记(tokens)转换为高维向量表示
在序列转换模型中,嵌入(embeddings)是一种将离散的标记(tokens)转换为连续的、高维向量表示的方法。这些向量通常具有维度 ,这个维度是模型的一个超参数,可以根据模型的复杂性和任务的需求进行调整。以下是这一过程的详细说明: 标记化(Tokenization): 将输入文本分割成单词、子词或字符等标记。 词汇表映射(Vocabulary Mapping): 将每个标记映

Machine Learning机器学习之高维数据降维(主成分分析PCA、线性判别分析、自编码器超级无敌详细讲解)
目录 前言 一、常见数据降维方法简介 1、降维方法分类情况 二、常见数据降维分析之主成分分析 2.1背景介绍 2.2思想原理 2.3数学公式 2.4PCA算法实现(Python完整代码) 2.5应用场景 三、常见数据降维分析之线性判别分析 3.1背景分析 3.2思想原理 3.4LDA算法实现 3.5应用场景 四、常见数据降维分析之t-分布邻近嵌入 4.1背景介绍 4.2思想原理 4.3t

ElasticSearch搜索进阶之路之高维数据的BKD树结构
ElasticSearch中高维数据的BKD树结构 KD树与BKD树简介 BKD树,全称为b-树形kd树(bushy kd-trees),是一种用于高维数据搜索的数据结构。它是基于kd树(k-dimensional tree)的改进版本。 KD树结构: kd树是一种二叉树结构,将数据按特征空间划分区域,支持快速最近邻搜索。每个节点代表一个k维点,通过特征轴划分形成二叉树。搜索最近邻时,
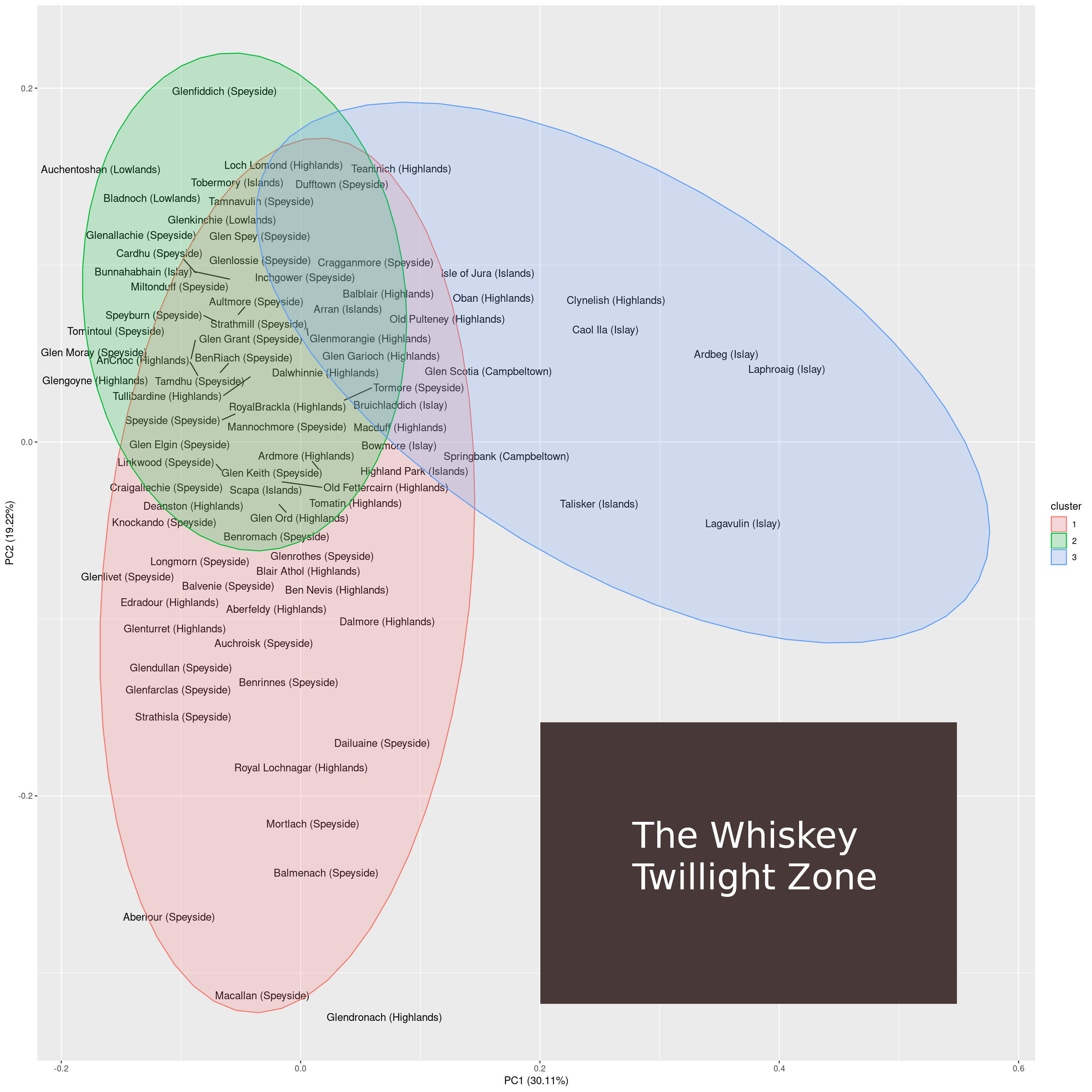
R语言高维数据的pca、 t-SNE算法降维与可视化分析案例报告
维度降低有两个主要用例:数据探索和机器学习。它对于数据探索很有用,因为维数减少到几个维度(例如2或3维)允许可视化样本。然后可以使用这种可视化来从数据获得见解(例如,检测聚类并识别异常值)。对于机器学习,降维是有用的,因为在拟合过程中使用较少的特征时,模型通常会更好地概括。 在这篇文章中,我们将研究三维降维技术: 主成分分析(PCA):最流行的降维方法内核PCA:PCA的一种变体,允许非线性t

高维全局优化 —— CBCC3
一、问题背景介绍 在高维优化问题中,通常采用分治法,对维度进行分组之后分别演化,最后合并得出结果。在协同演化之类的算法中,会对每一个分组进行循环演化。实际情况中,每个分组的权重不尽相同,当对某些权重很低的分组进行演化后,对于结果的改进会不如人意,因此,需要采用一种方案,识别分组后的各个分组的贡献度,然后对具有高贡献的分组给予更多的评估次数。借此提高全局优化的结果。 Contribution-B
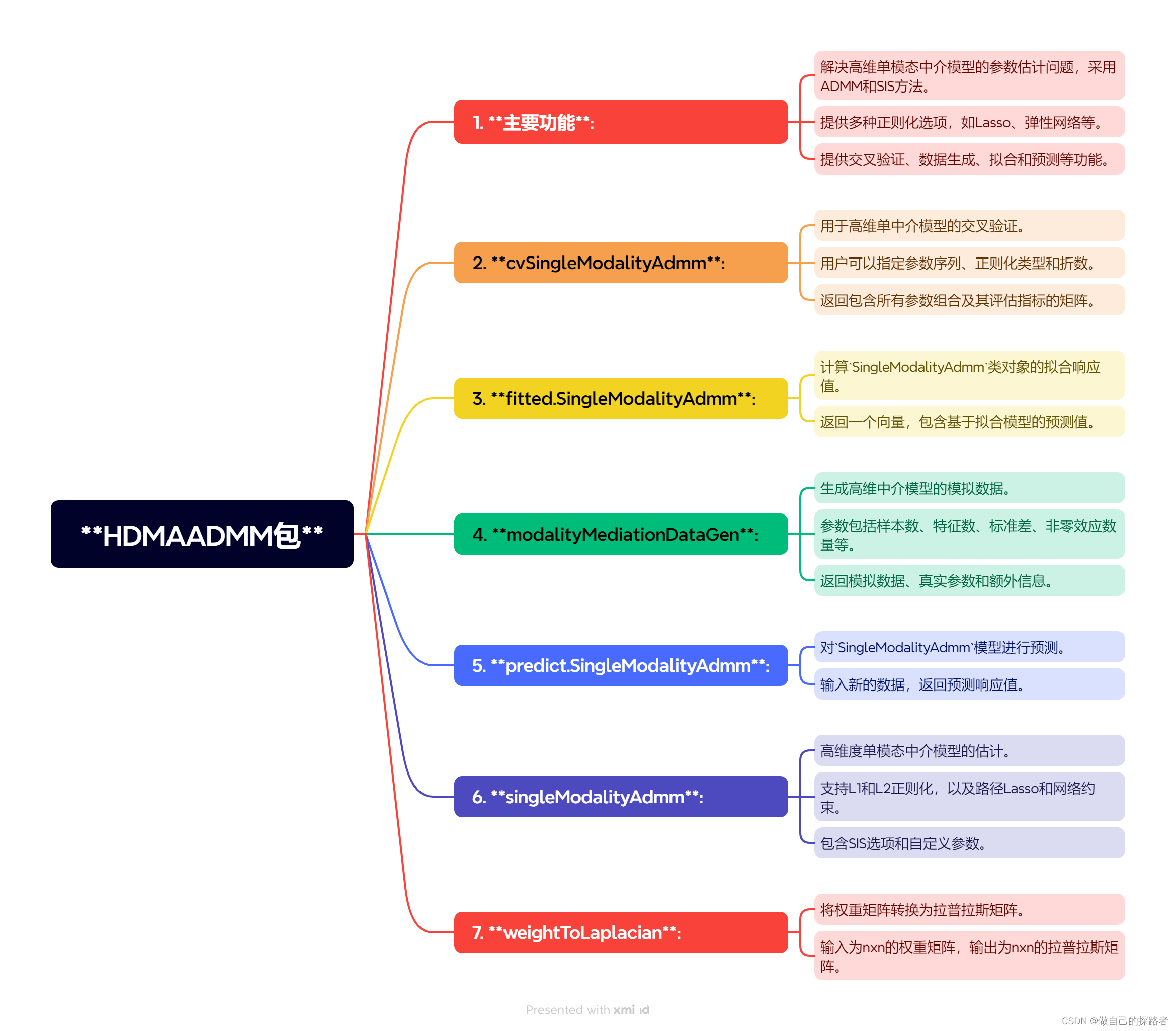
高维中介数据:基于交替方向乘子法(ADMM)的高维度单模态中介模型的参数估计(入门+实操)
全文摘要 用于高维度单模态中介模型的参数估计,采用交替方向乘子法(ADMM)进行计算。该包提供了确切独立筛选(SIS)功能来提高中介效应的敏感性和特异性,并支持Lasso、弹性网络、路径Lasso和网络约束惩罚等不同正则化方法。 Pathway Lasso 背景 传统的结构方程建模(SEM)在处理大量中介变量时变得不稳定且计算复杂。Pathway Lasso引入了一个新的惩罚函数,它是一
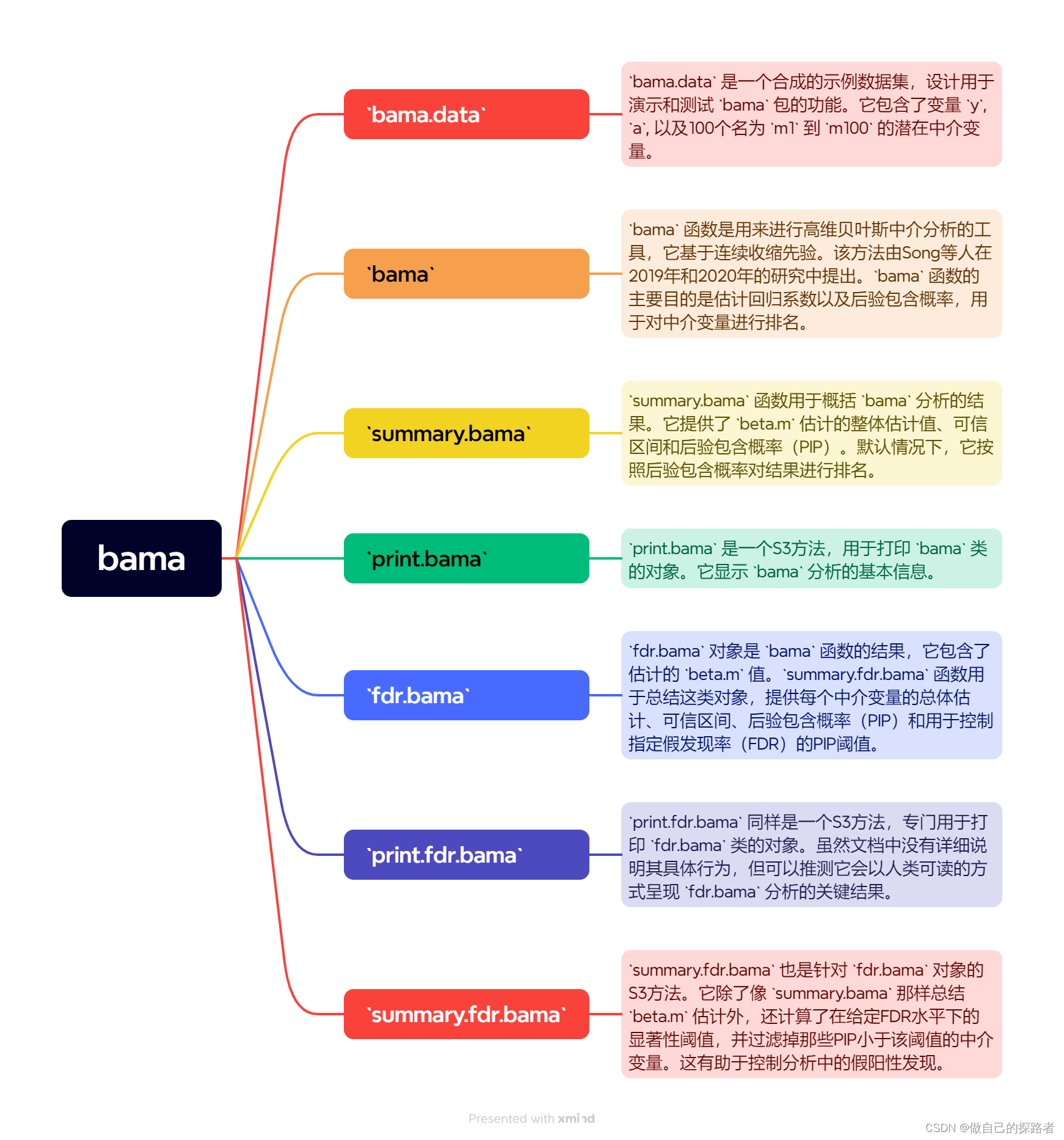
高维中介数据:基于贝叶斯推断的因果中介效应估计方法
摘要 该博客介绍一种基于贝叶斯推断的高维因果中介效应估计方法,适用于omics研究中的大量潜在中介变量分析。在贝叶斯框架下,利用连续收缩先验扩展了传统的因果中介分析技术,以处理高维数据。这种方法提高了全局中介分析的统计功效,并能有效地识别对路径中介效应有贡献的非零中介变量。此外,它有助于理解无活性中介变量的复合零情况结构 所需的识别假设 无测量混淆(unmeasured confound
json模块(高维数据的存储与读取)
json模块是 Python 标准库中的一个模块,用于处理 JSON(JavaScript Object Notation)格式的数据。JSON是一种轻量级的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成。模块提供了在 Python 中进行 JSON 编码(序列化)和解码(反序列化)的功能。json 以下是 json模块的主要函数和用法: 1.json.dumps(obj, *, s

svm对未知数据的分类_基于SVM的高维不平衡数据分类方法与流程
https://blog.csdn.net/weixin_39833270/article/details/111519043
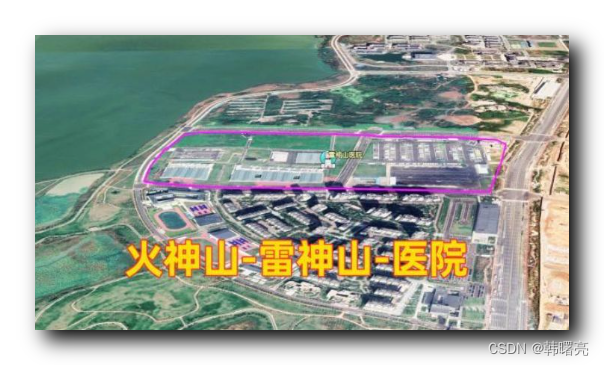
【易学】周易入门 ② ( 易学案例 | 推背图 | 火神山和雷神山 | 科学 与 玄学 的关系 | 科学 - “ 三维智慧 “ | 玄学 - “ 高维智慧 “ | 开悟 | 道与术 )
文章目录 一、易学案例1、推背图2、火神山和雷神山 二、科学 与 玄学1、科学 与 玄学 的关系2、科学 - " 三维智慧 "3、玄学 - " 高维智慧 "4、开悟 - " 打破认知 开启智慧 "5、道与术 一、易学案例 1、推背图 李世民 命 天文学家 李淳风 , 相士 袁天罡 推算大唐气运 , 李淳风 写了 一百多年 的 唐朝国运 , 袁天罡
已知高维高斯联合概率分布求边缘概率分布以及条件概率分布
博主最近在看卡尔曼滤波算法,个人认为在卡尔曼滤波算法中最核心的部分莫过于高维高斯联合概率分布的性质,因此打算将这些性质整理成博客记录下来方便自己今后的学习,如果有哪里不对,欢迎各位读者指正。 一 引理 这里我引入一个定理,这个定理不在本博客证明,因为它很直观,便于理解。 假设随机变量 X X X服从均值为 μ \mu μ,协方差矩阵为 Σ \Sigma Σ的高斯分布(为了更具有一般性,
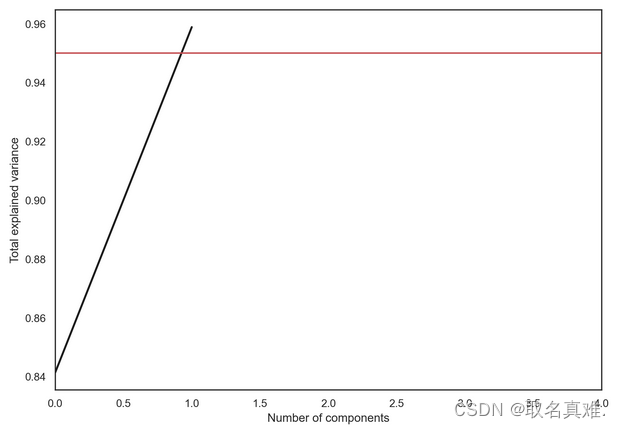
无监督学习Principal Component Analysis(PCA)精简高维数据
目录 介绍 一、PCA之前 二、PCA之后 介绍 Principal Component Analysis (PCA) 是一种常用的数据降维和特征提取技术。PCA通过线性变换将高维数据映射到低维空间,从而得到数据的主要特征。PCA的目标是找到一个正交基的集合,使得将数据投影到这些基上时,能够保留尽可能多的数据信息。每个正交基称为一个主成分,它的重要性通过其对应的特征值来衡量。PCA

python机器学习之降维算法PCA(高维数据的可视化,鸢尾花案例)
高维数据的可视化 n_components是我们降维后需要的维度,即降维后需要保留的特征数量,降维流程中第二步里需要确认的k值,一般输入[0, min(X.shape)]范围中的整数。 调用库和模块 import matplotlib.pyplot as pltfrom sklearn.datasets import load_irisfrom sklearn.decomposition
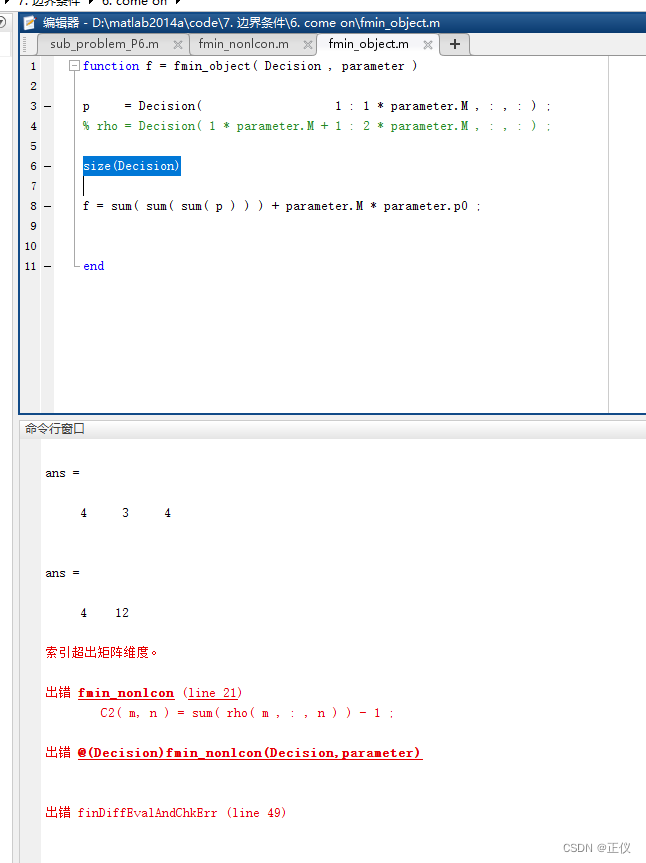
fmincon函数的决策变量可以是二维矩阵,但不建议是高维矩阵
1)二维矩阵代码 clear allclc% 定义目标函数fun = @(x) sum(sum(x.^2));% 初始矩阵x0 = 2 + rand(2, 2);% 定义空的线性不等式约束A = [];b = [];% 定义空的线性等式约束Aeq = [];beq = [];% 定义变量的上下界lb = ones(2,2);ub = [];% 使用 fmincon 求解opt
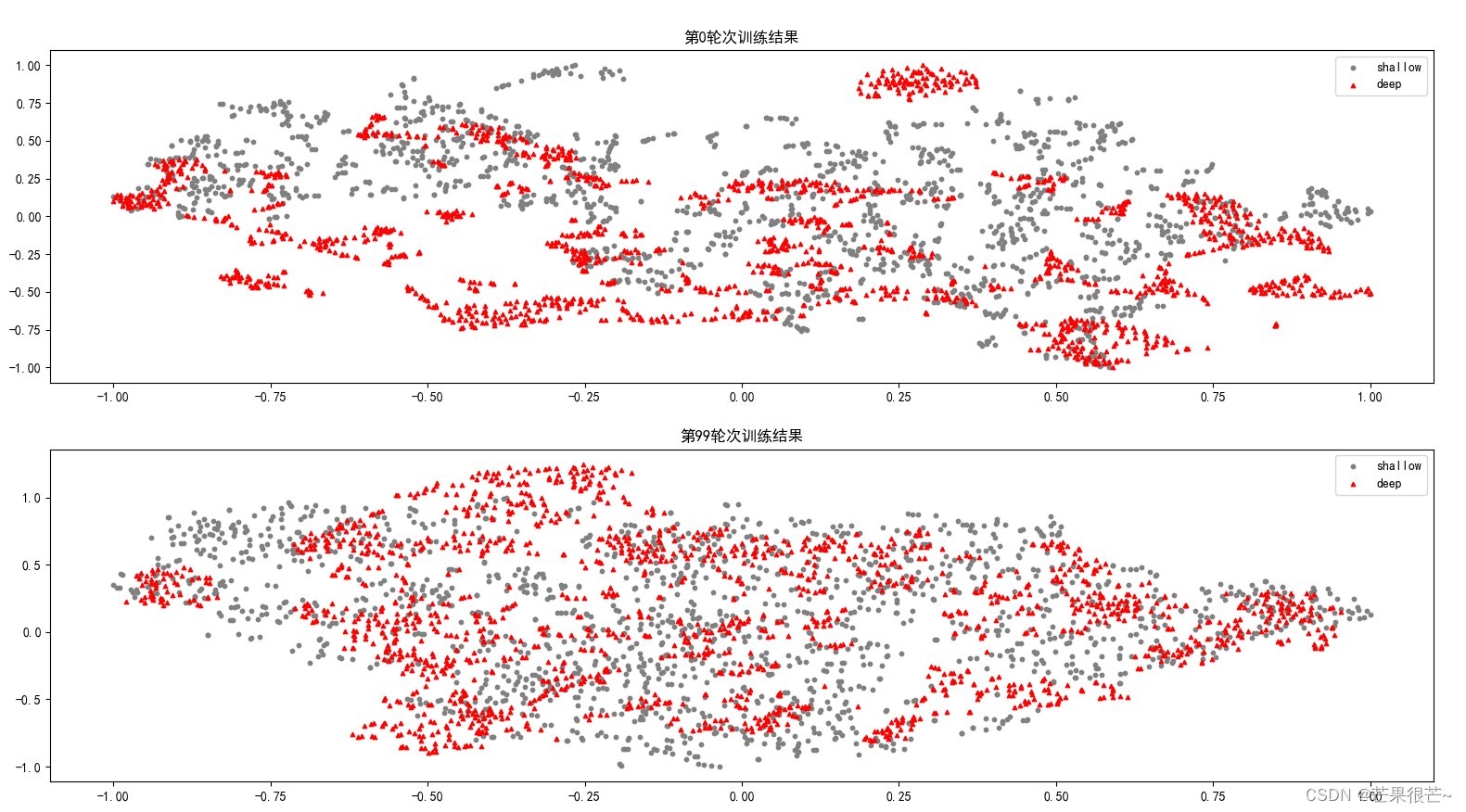
t-SNE高维数据可视化实例
t-SNE:高维数据分布可视化 实例1:自动生成一个S形状的三维曲线 实例1结果: 实例1完整代码: import matplotlib.pyplot as pltfrom sklearn import manifold, datasets"""对S型曲线数据的降维和可视化"""x, color = datasets.make_s_curve(n_samples=1000, ran

t-SNE高维数据可视化实例
t-SNE:高维数据分布可视化 实例1:自动生成一个S形状的三维曲线 实例1结果: 实例1完整代码: import matplotlib.pyplot as pltfrom sklearn import manifold, datasets"""对S型曲线数据的降维和可视化"""x, color = datasets.make_s_curve(n_samples=1000, ran

FWT+高维前缀和:Gym - 103202M
https://vj.imken.moe/contest/597216#problem/F 考虑两个人的集合分别为 i , j i,j i,j,那么我们令 f ( i ⊗ j ) + + f(i\otimes j)++ f(i⊗j)++,其中 f ( s ) f(s) f(s) 表示两个人不同集合恰好为 s s s,显然 f ( s ) f(s) f(s) 可以FWT求。 假设 g

Python知识点——高维数据的格式化
常用JSON格式对高维数据进行表达和存储: 常见的高维数据最典型的例子:<key,value>键值对 JSON格式表达键值对<key, value>的基本格式如下,键值对都保存在双引号中: "key" : "value" Json库 dumps()和loads()分别对应编码和解码功能 函数描述json.dumps(obj,sort_keys=False,indent=None)将P