本文主要是介绍清华商汤上海AICUHK提出Siamese Image Modeling,兼具linear probing和密集预测性能!...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
关注公众号,发现CV技术之美
本文分享论文『Siamese Image Modeling for Self-Supervised Vision Representation Learning』,由清华(黄高组)&商汤(代季峰组)&上海AI Lab&CUHK提出Siamese Image Modeling,兼具linear probing和密集预测性能!
详细信息如下:

论文链接:http://arxiv.org/abs/2206.01204
01
摘要
自监督学习(SSL)在各种下游视觉任务上都提供了优异的性能。目前提出了两种主流SSL框架,即实例鉴别(ID)和掩蔽图像建模(MIM)。ID将来自同一图像的不同视图的表示拉到在一起。它在 linear probing方面表现良好,但在检测性能方面较差。另一方面,MIM在给定mask图像的情况下重建原始内容。它擅长密集预测,但在linear probing上表现不佳。它们的区别是由于忽视了语义对齐或空间敏感性的表示要求。
具体而言,作者观察到:(1)语义对齐要求将语义相似的视图投影到附近的表示中,这可以通过对比不同的视图和强数据增强来实现;(2) 空间敏感性要求对图像中的局部结构进行建模。因此,使用掩蔽图像预测密集表示是有益的,因为它模拟了图像内容的条件分布。
在这些分析的推动下,作者提出了Siamese Image Modeling (SIM),该模型基于来自同一图像但具有不同增强的另一个mask视图,预测增强视图的密集表示。本文的方法使用带有两个分支的Siamese网络。在线分支对第一个视图进行编码,并根据这两个视图之间的相对位置预测第二个视图的表示。目标分支通过对第二个视图进行编码来生成目标。通过这种方式,可以分别使用ID和MIM实现可比较的linear probing和密集预测性能。
02
Motivation
自监督学习(SSL)长期以来一直是视觉领域追求的目标。它使我们能够在没有人工标注标签的情况下训练模型,从而可以利用大量未标记的数据。SSL在各种下游任务中提供了与监督学习baseline相比的竞争结果,包括ImageNet微调和检测/分割任务的迁移学习。
为了以SSL方式有效地训练模型,研究人员设计了所谓的“借口任务(pretext tasks)”来生成监控信号。最典型的框架之一是实例区分(ID),其核心思想是将来自同一图像的不同增强视图的表示拉在一起,避免表示崩溃。目前已经提出了ID的不同变体,包括对比学习、不对称网络和特征去相关。
最近,另一个SSL框架逐渐吸引了更多的关注,即掩蔽图像建模(MIM)。MIM方法训练模型从掩蔽图像重建原始内容。这种做法有助于了解图像中丰富的局部结构,从而在目标检测等密集预测任务中获得优异的性能。然而,MIM没有像ID那样的良好线性可分性,并且通常在few-shot分类设置下表现不佳。
ID和MIM方法都有各自的优缺点。作者认为,这种困境是由于忽视了语义对齐或空间敏感性的表示要求造成的。具体而言,MIM在每个图像内独立运行,而不考虑图像间的关系。语义相似图像的表示没有很好地对齐,这进一步导致MIM的linear probing性能较差。另一方面,ID只对整个图像使用全局表示,因此无法对图像内部结构进行建模。因此,缺少特征的空间敏感性,ID方法通常在密集预测上产生较差的结果。
为了克服这一困境,作者观察了语义对齐和空间敏感性的关键因素:(1) 语义对齐要求将语义相似的图像投影到附近的表示中。这可以通过对比同一图像中的不同增强视图来实现。强数据增强也是有益的,因为它们为模型提供了更多的不变性;(2) 空间敏感性需要对图像中的局部结构进行建模。因此,预测mask图像的密集表示很有帮助,因为它模拟了每个图像中图像内容的条件分布。这些观察结果促使作者从具有不同增强的mask视图预测图像的密集表示。
为此,作者提出了Siamese Image Modeling(SIM),该模型基于同一图像中的另一个增强的mask视图重建增强视图的密集表示。它采用了一个孪生网络(Siamese Network),有一个在线分支和一个目标分支。在线分支由编码器和解码器组成,前者将第一个掩蔽视图映射为潜在表示,后者根据这两个视图之间的相对位置重建第二个视图的表示。目标分支仅包含一个动量编码器,该编码器将第二个视图编码为预测目标。编码器由主干和投影组成。经过预训练后,只将在线分支用于下游任务。
SIM模型使模型能够识别语义对齐和空间敏感性的最重要因素。通过精心设计的消融研究,作者分别证明了不同视图对语义对齐的强大增强和掩蔽图像对空间敏感性的密集表示的有效性。
最后,作者在几个主流评估任务上评估了本文的模型,包括linear probing、目标检测、ImageNet使用完整和有限的训练数据进行微调。SIM能够分别使用ID和MIM获得可比较的线性评估和检测结果。此外,作者发现,为了获得语义对齐,不需要全局损失,而密集损失可以同时优化图像的全局和密集表示。
03
方法
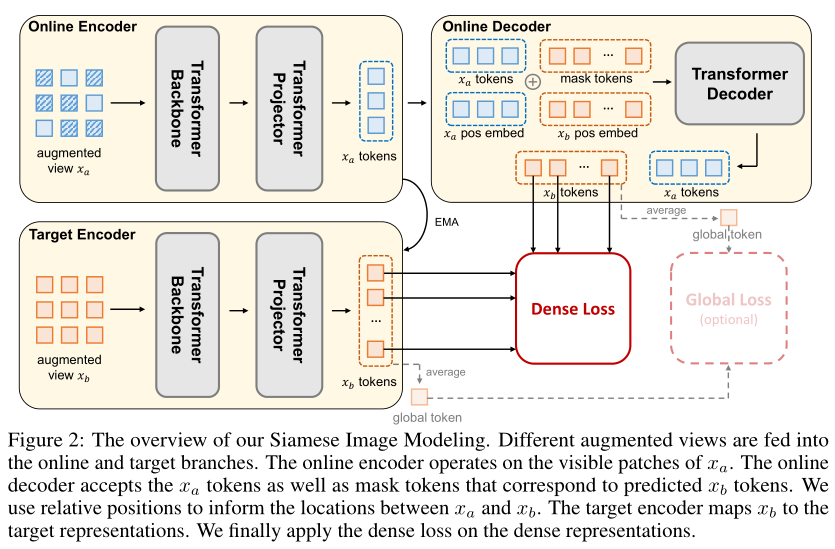
上图描述了本文的SIM模型。它采用相同图像的两个增强视图和作为输入。SIM旨在基于xa的密集表示预测xb的密集表示。使用带有在线和目标分支的孪生网络。在线分支由编码器和解码器组成,编码器将xa的可见patch编码为潜在表示,解码器根据和之间的相对位置从潜在表示预测的表示。目标分支只有一个动量编码器,该编码器将作为输入并生成预测目标。编码器由主干和投影组成。在预训练后,仅使用在线主干网络进行下游评估。
3.1 Augmented Inputs
ID方法采用两种不同的增强视图,而MIM方法使用单个视图。本文的方法中,与ID方法类似,作者将两个不同的视图分别作为在线分支和目标分支的输入。不同的视图可以显著提高linear probing结果,而不会影响目标检测的性能。
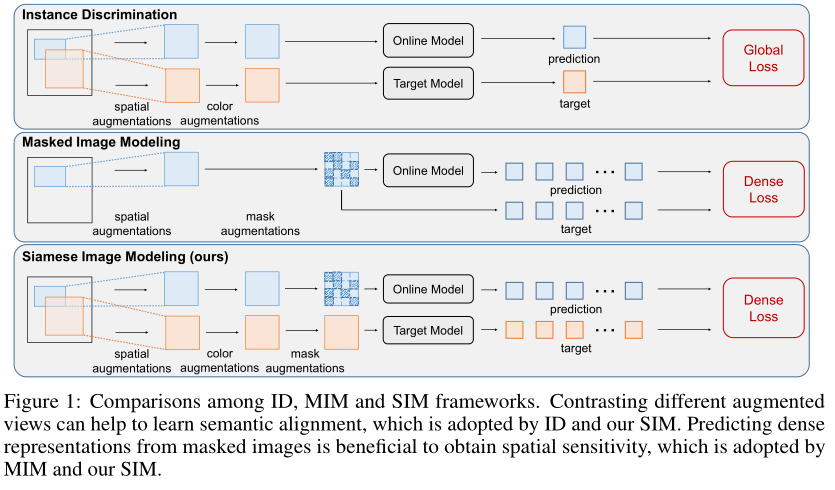
除了视图的数量之外,数据增强也存在差异。ID方法倾向于添加更强的增强,通常包含空间和颜色增强。然而,最近,MAE报告说,颜色增强对MIM预训练不利。作者发现,颜色增强在不同的训练环境下有不同的效果。当与不同的视图一起使用时,它们可以提供更多的不变性,但如果与相同的视图一起使用,这种效果将消失。因此,作者保留了ID方法的空间和颜色增强。
另一个区别是MIM mask了输入图像的一些patch以进行重建,称之为mask augmentation。通过mask augmentation,密集预测任务可以模拟每个图像中图像内容的条件分布。这些表示经过训练以捕捉局部结构,因此具有空间敏感性。因此,作者还将mask augmentation应用于在线分支的视图。
3.2 Prediction Targets
预测目标可以有多种选择。例如,ID方法用于预测不同增强视图的特征,而MIM方法用于预测同一视图的像素或特征。通过实验发现,对于不同的视图,特征预测是优越的。因此,SIM被设计用于预测来自同一图像的另一个不同增强视图的特征。
Online Branch
在线分支将进行预测。在线编码器首先将mask视图映射为潜在表示,其中表示可见patch的数量,D表示每个patch的特征尺寸。按照ID方法中的实践,作者在主干之后附加一个投影层以形成编码器。然后,在线解码器结合、mask tokenm及其相对位置来计算预测:
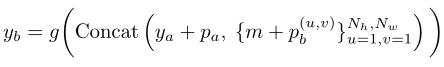
其中,m表示mask token的可学习嵌入,是的位置嵌入,表示patch在位置的位置嵌入。和分别表示中沿高度和宽度维度的token数(例如,)。因此,是中所有token的数量。请注意,与MIM方法不同,mask token对应于来自不同目标视图的图像块,而不是输入视图。
Target Branch
目标分支负责生成目标。目标编码器是在线编码器的指数移动平均。它将来自的所有token作为输入,并输出其潜在表示。注意,还可以直接预测原始像素,其中不需要目标编码器。然而,作者发现,当使用不同的视图时,特征预测可以提供更好的性能。
Positional Embedding for Online Decoder

在线解码器的位置嵌入必须告诉解码器和中每个patch的对应位置。解码器根据的可见patch及其相应位置预测的密集表示。对于在线解码器的所有输入patch,包括来自的可见patch和指示的mask token,其位置嵌入是根据相对于左上原点的相对位置计算的。上图显示了详细的过程。假设原始图像中两个裁剪视图和的(左、上、高、宽)位置为和。的位置按照以下常见做法计算:
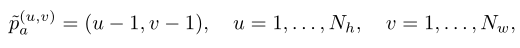
其中,u和v是沿高度和宽度标注的位置索引。表示的mask token的位置计算如下:
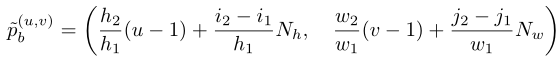
遵循MAE中的实践,作者进一步应用sin(·)和cos(·)算子得到二维sin-cos位置嵌入。为了告知两个不同视图之间的比例变化,作者将相对比例变化添加为:
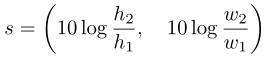
其中,用于使数值范围与相对位置相似。然后,最终位置嵌入计算如下:

其中,PE是正余弦位置编码函数。对于,作者将相对位置和比例变化连接在一起,并使用线性层将维度拟合到D中。
3.3 Loss Function
损失函数指导训练方向,从而塑造学习表征的特征。ID方法通常采用全局平均图像特征上的损失来分离图像之间的表示,而MIM在每个图像块上采用密集损失来学习每个单独图像中的表示。为了获得并结合这些理想的特性,作者对SIM实现了全局和密集级损失。
一旦计算出预测和目标,作者采用UniGrad的对比损失作为目标函数:
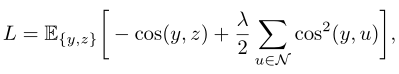
其中,y来自在线预测,其目标z是正样本,来自目标分支的所有表示构成负样本集N。之所以使用UniGrad,是因为它是一种统一的ID损失方法,并且对内存友好。大多数ID方法都使用信息损失,这将需要内存来计算相似度。这对于密集损失是不可行的,因为有大量的负样本patch。相反,UniGrad只通过首先计算负样本的协方差矩阵来消耗内存。为了指导模型获得更好的全局和密集表示,作者在全局和密集级别上都使用了UniGrad。
Global Loss
全局损失首先将每个图像的token表示平均为:
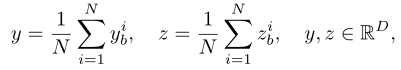
其中,和表示第i个token表示。负样本集是目标分支中所有图像的全局平均表示的组合。
Dense Loss
密集损失将每个token表示作为一个独立样本处理。作者从token表示中减去每个图像内的平均值,以避免全局和密集级损失之间的冲突。也就是说,
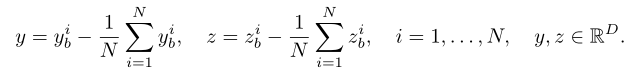
然后作者基于每一个token计算了密集损失,密集损失计算方式如下:
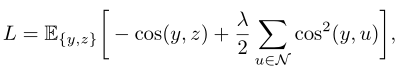
总体目标函数是全局损失和密集损失的加权组合:
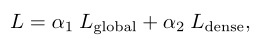
其中,α1和α2是平衡权重。
3.4 Discussion
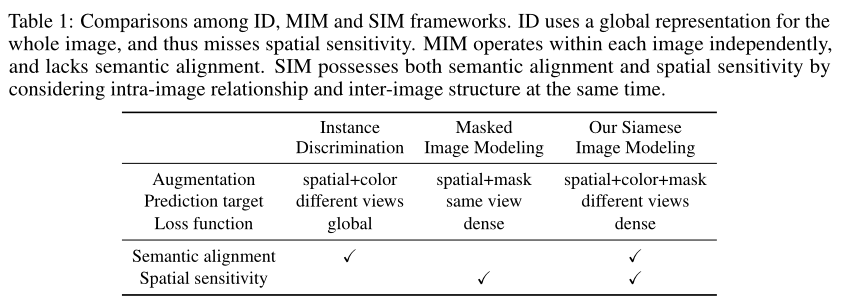
如上表所示,作者从三个角度进一步强调SIM和以前作品之间的差异:
对于增强,ID方法表明,空间和颜色变换有利于线性可分性。另一方面,mask对MIM方法很重要,有助于提高检测性能。因此,SIM采用了所有这些增强方法。
对于预测目标,ID采用两种不同的增强视图,因为它们有助于更好地建模增强下的不变性。相反,MIM只考虑输入和目标的相同视图。从重建的角度来看,这是一种自然的设计选择,但可能会损害表示的线性可分性。SIM显示MIM也可以应用于不同的视图,从而在不损害检测性能的情况下获得良好的linear probing性能。
对于损失函数,ID仅使用全局损失,因为它旨在分离单个图像。MIM采用密集损失来帮助在每个图像中的patch之间建立连接。SIM表明,密集损失对于提高表示的定位能力至关重要。因此,SIM可以在不牺牲linear probing性能的情况下提供高目标检测结果。
04
实验
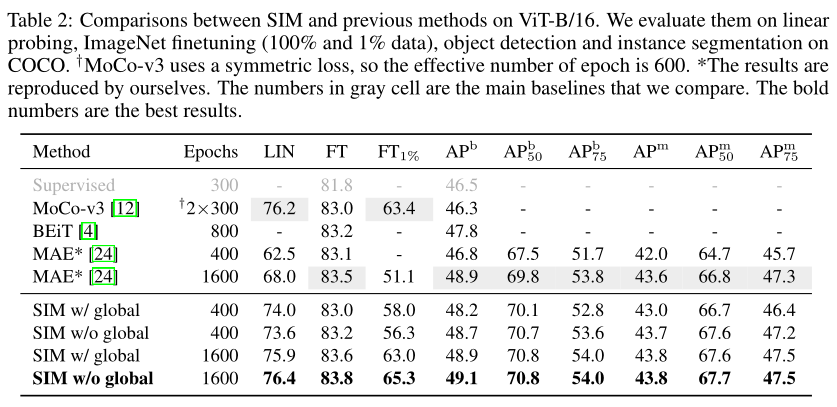
在上表中,作者这个将SIM与以前的方法在几个任务上进行了比较,包linear probing、ImageNet微调、目标检测和COCO上的实例分割。
对于linear probing,SIM可以给出与MoCo-v3相当的结果,并大大超过MAE。作者还发现,实现高linear probing性能不需要全局损失,这可能表明仅使用密集损失可以同时优化全局和密集表示。
对于COCO上的检测和分割任务,SIM优于所有以前的方法。
对于具有完整数据的ImageNet微调,所有SSL方法的性能都很好,并且优于有监督的预训练。
当只有1%的数据可用时,SIM可以超过MoCo-v3 2个点,超过MAE14个点。这表明本文的方法具有优异的few-shot能力。
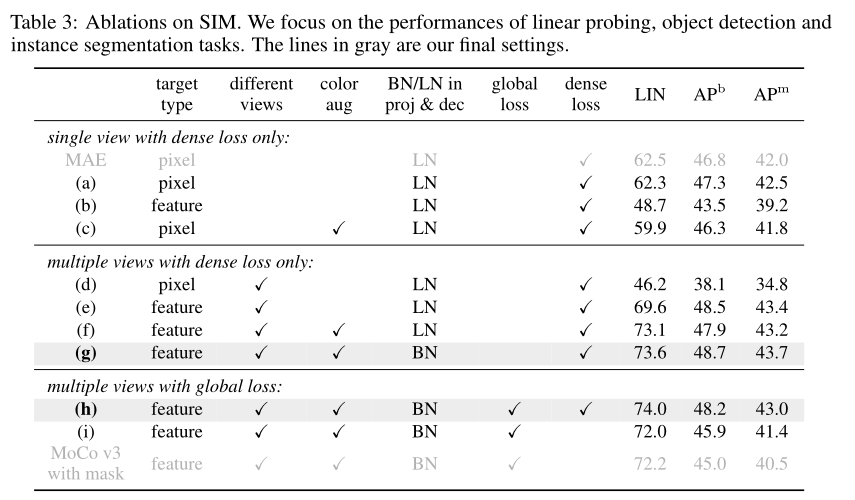
作者在上表中仔细分析了SIM的组成部分,以确定语义对齐和空间敏感性的最重要因素。可以看出本文采用的基于特征的重建、不同的视图、数据增强等都是有利于提升性能的。
05
总结
作为自监督学习范式的代表,实例判别(ID)和掩蔽图像建模(MIM)各有优缺点。ID通常表现出较高的linear probing性能,但无法很好地进行密集预测。MIM擅长密集预测,但提供的linear probing结果较低。
作者认为,这是由于忽视了语义对齐或空间敏感性的表示要求。为了解决这个难题,作者观察到:(1)语义对齐可以通过对比不同的增强视图来学习;(2) 通过对mask图像的密集表示进行建模,可以获得空间灵敏度。
因此,作者提出了孪生图像建模(SIM),该模型基于同一图像中的另一个mask增强视图,预测增强视图的密集表示。广泛的消融实验证实了本文的观察结果。SIM能够通过ID获得可比较的线性评估结果,并通过MIM获得密集预测结果。
参考资料
[1]http://arxiv.org/abs/2206.01204

END
加入「计算机视觉」交流群👇备注:CV

这篇关于清华商汤上海AICUHK提出Siamese Image Modeling,兼具linear probing和密集预测性能!...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







