linear专题

理解分类器(linear)为什么可以做语义方向的指导?(解纠缠)
Attribute Manipulation(属性编辑)、disentanglement(解纠缠)常用的两种做法:线性探针和PCA_disentanglement和alignment-CSDN博客 在解纠缠的过程中,有一种非常简单的方法来引导G向某个方向进行生成,然后我们通过向不同的方向进行行走,那么就会得到这个属性上的图像。那么你利用多个方向进行生成,便得到了各种方向的图像,每个方向对应了很多

【CSS渐变】背景中的百分比:深入理解`linear-gradient`,进度条填充
在现代网页设计中,CSS渐变是一种非常流行的视觉效果,它为网页背景或元素添加了深度和动态感。linear-gradient函数是实现线性渐变的关键工具,它允许我们创建从一种颜色平滑过渡到另一种颜色的视觉效果。在本篇博客中,我们将深入探讨linear-gradient函数中的百分比值,特别是像#C3002F 50%, #e8e8e8 0这样的用法,以及它们如何影响渐变效果。 什么是linear-g

Spark MLlib模型训练—回归算法 Linear regression
Spark MLlib模型训练—回归算法 Linear regression 线性回归是回归分析中最基础且应用广泛的一种方法。它用于建模目标变量和一个或多个自变量之间的关系。随着大数据时代的到来,使用像 Spark 这样的分布式计算框架进行大规模数据处理和建模变得尤为重要。本文将全面解析 Spark 中的线性回归算法,介绍其原理、参数、Scala 实现、代码解读、结果分析以及实际应用场景。 1
线性代数:线性代数(Linear Algebra)综述
文章目录 矩阵 / Matrix元素运算加法 A + B A+B A+B数量乘法 c A cA cA与向量之间的运算乘法 A b A\mathbf{b} Ab 与矩阵之间的运算矩阵乘法 乘方 性质方阵 / Square Matrix零矩阵对角矩阵 / Diagonal Matrix单位矩阵 / Identity Matrix转置 / Transpose逆矩阵 / Inverse Mat

Spark MLlib模型训练—回归算法 GLR( Generalized Linear Regression)
Spark MLlib模型训练—回归算法 GLR( Generalized Linear Regression) 在大数据分析中,线性回归虽然常用,但在许多实际场景中,目标变量和特征之间的关系并非线性,这时广义线性回归(Generalized Linear Regression, GLR)便应运而生。GLR 是线性回归的扩展,能够处理非正态分布的目标变量,广泛用于分类、回归以及其他统计建模任务。

linear-gradient 渐变
CSS3 Gradient 分为 linear-gradient(线性渐变)和 radial-gradient(径向渐变)。而我们今天主要是针对线性渐变来剖析其具体的用法。为了更好的应用 CSS3 Gradient,我们需要先了解一下目前的几种现代浏览器的内核,主要有 Mozilla(Firefox,Flock等)、WebKit(Safari、Chrome等)、Opera(Opera浏览器
机器学习—线性回归算法(Linear Regression)
目录 一、基本概念二、线性回归简单分类与模型三、线性回归的关键步骤四、线性回归问题分析五、线性回归问题的解法1、最小二乘法2、梯度下降法 六、线性回归中的过拟合与欠拟合1、过拟合1、岭回归(Ridge Regression)2、套索回归 (Lasso回归)(Lasso Regression)3、弹性网(Elastic Net) 2、欠拟合 七、线性回归中的超参数与模型评估方法1、超参数(Hy

【Pytorch】Linear 层,举例:相机参数和Instance Feaure通过Linear层生成Group Weights
背景 看论文看到这个pipeline,对于相机参数和Instance Fature 的融合有点兴趣,研究如下: Linear 层 Linear 层是最基本的神经网络层之一,也称为全连接层。它将输入与每个输出神经元完全连接。每个连接都有一个权重和一个偏置。 示例代码 import torchimport torch.nn as nn# 定义一个简单的全连接网络,包含两个Linear层

爆改YOLOv8|利用全新的聚焦式线性注意力模块Focused Linear Attention 改进yolov8(v1)
1,本文介绍 全新的聚焦线性注意力模块(Focused Linear Attention)是一种旨在提高计算效率和准确性的注意力机制。传统的自注意力机制在处理长序列数据时通常计算复杂度较高,限制了其在大规模数据上的应用。聚焦线性注意力模块则通过优化注意力计算的方式,显著降低了计算复杂度。 核心特点: 线性时间复杂度:与传统的自注意力机制不同,聚焦线性注意力模块采用了线性时间复杂度的计算方法

Introduction to linear optimization 第二章全部课后题答案
费了好长时间,终于把这本经典理论教材第二章的课后题做完了。大部分都是证明题,很多都是比较有难度的。 不少题我参考了网上找到的一些资料的思路,但是有一些题目我觉得这些网上找到的答案也不太好,自己修正完善了下,少部分题目自己独立完成。 我把答案放在一个 Jupyter book 上,见链接:第二章答案
Linear Regression学习笔记
回归主要分为线性回归和逻辑回归。线性回归主要解决连续值预测问题,逻辑回归主要解决分类问题。但逻辑回归输出的是属于某一类的概率,因此常被用来进行排序。 1. 线性回归的原理 假定输入 χ \chi和输出 y y之间有线性相关关系,线性回归就是学习一个映射 f:χ→yf: \chi \to y 然后对于给定的样本 x x,预测其输出: y^=f(x)\hat y=f(x) 现假定 x=
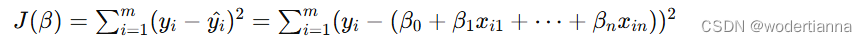
线性回归(Linear Regression)原理详解及Python代码示例
一、线性回归原理详解 线性回归是一种基本的统计方法,用于预测因变量(目标变量)与一个或多个自变量(特征变量)之间的线性关系。线性回归模型通过拟合一条直线(在多变量情况下是一条超平面)来最小化预测值与真实值之间的误差。 1. 线性回归模型 对于单变量线性回归,模型的表达式为: 其中: y是目标变量。x是特征变量。β0是截距项(偏置)。β1
让IE8支持CSS3属性(border-radius、box-shadow、linear-gradient)
下载 PIE-1.0.0.zip解压后,将文件夹重命名为PIE,放到项目目录下在CSS3文件中添加一行代码 behavior: url(PIE/PIE.htc); 例如: .form__input{border-radius: 0.3em;behavior: url(PIE/PIE.htc);} 参考: TYStudio-专注WEB前端开发 css3pie

论文浅读之Mamba: Linear-Time Sequence Modeling with Selective State Spaces
介绍 这篇论文提出了一种新型的"选择性状态空间模型"(Selective State Space Model, S6)来解决之前结构化状态空间模型(SSM)在离散且信息密集的数据(如文本)上效果较差的问题。 Mamba 在语言处理、基因组学和音频分析等领域的应用中表现出色。其创新的模型采用了线性时间序列建模架构,结合了选择性状态空间,能够在语言、音频和基因组学等不同模式中提供卓越的性能。这种突破

Introduction to linear optimization 第 2 章课后题答案 11-15
线性规划导论 Introduction to linear optimization (Dimitris Bertsimas and John N. Tsitsiklis, Athena Scientific, 1997), 这本书的课后题答案我整理成了一个 Jupyter book,发布在网址: https://robinchen121.github.io/manual-introductio

机器学习 - 线性回归(Linear Regression)
1. 目标 线性回归是希望通过对样本集进行有监督的学习之后,找出特征属性与标签属性之间的线性关系 Θ \Theta Θ。从而在获取没有标签值的新数据时,根据特征值和线性关系,对标签值进行预测。 2. 算法原理 2.1 线性模型(Linear Model) 在二维平面坐标系中,一条直线可表示为: f ( x ) = θ 1 x + θ 0 f(x) = \theta_1x + \thet
数据结构之线性表(linear_list)一
线性结构的特点(非空 有限 集合): 1、存在唯一一个头元素; 2、存在唯一一个尾元素; 3、除头元素外,每个元素都有唯一前驱; 4、除尾元素外,每个元素都有唯一后继; 线性表中数据元素的组成:若干个数据项,此种情况下,通常把线性表称为记录;含有大量记录的线性表称为文件。 注意:同一线性表中的元素必定具有相同特性(组成、顺序),相邻元素间有序偶关系。序偶关系引
Lecture3——线性最优化(Linear Optimization)
一,本文重点 线性最优化(LP)和标准线性最优化(Standard LP form)的定义如何将LP转换为Standard LP用Python解决LP问题将非线性最优化问题(NLP)转换为LP 二,定义 1,线性最优化 定义 线性最优化问题,或者线性规划(linear programming,缩写:LP)是一个目标函数和所有限制函数(在决策变量中)都是线性的最优化问题。 注意:
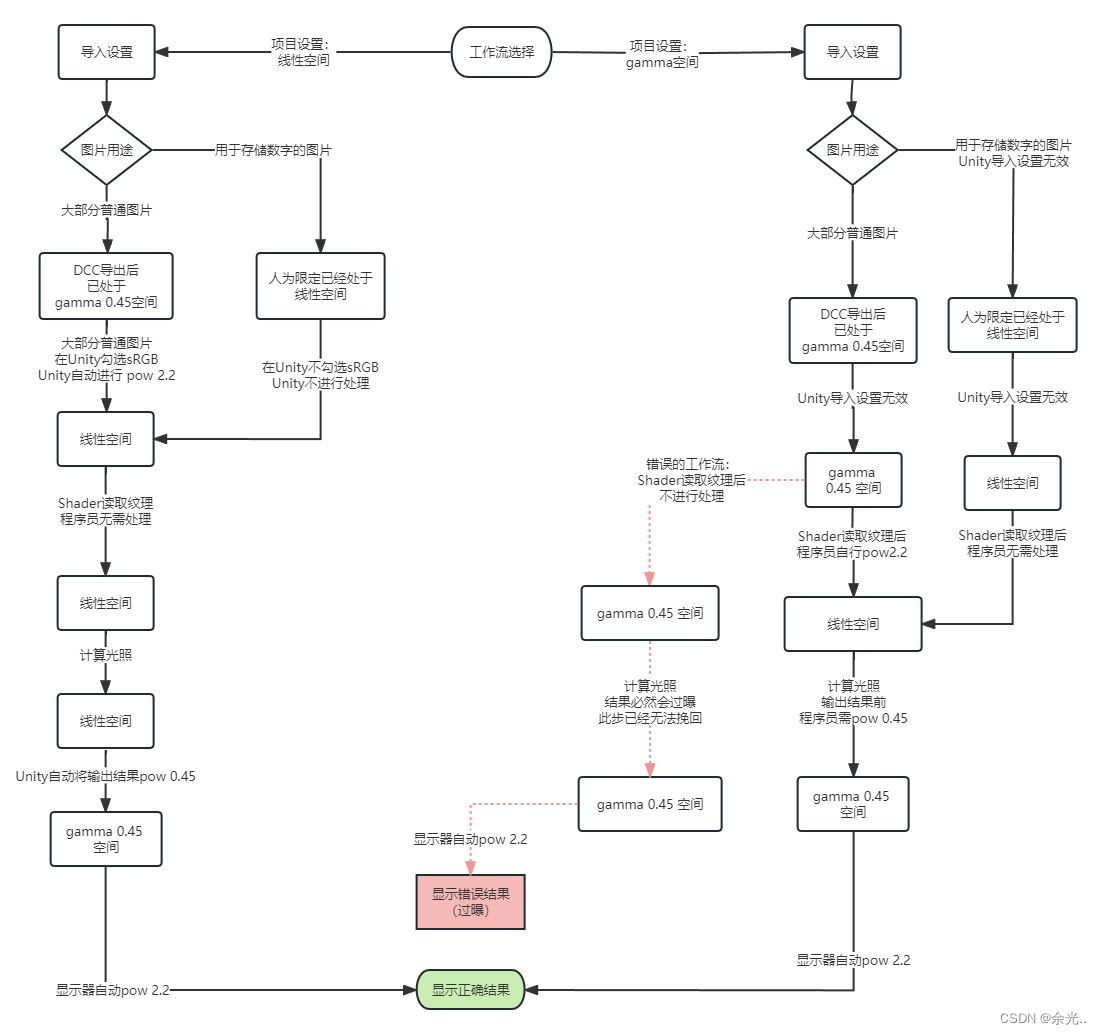
Unity中的伽马(Gamma)空间和线性(Linear)空间
伽马空间定义:通常用于描述图像在存储和显示时的颜色空间。在伽马空间中,图像的保存通常经过伽马转换,使图片看起来更亮。 gamma并不是色彩空间,它其实只是如何对色彩进行采样的一种方式 为什么需要Gamma: 在游戏业界长期以来都忽视一个伽马矫正的问题,这就导致渲染出来的效果要么过曝,要么过暗,总是和真实世界不同。 尽管是使用了同一shader渲染,但选择颜色空间不同和处理gamma矫正
神经网络 torch.nn---Linear Layers(nn.Linear)
torch.nn - PyTorch中文文档 (pytorch-cn.readthedocs.io) torch.nn — PyTorch 2.3 documentation nn.Linear torch.nn.Linear(in_features, out_features, bias=True, device=None, dtype=None) 参数: in_features -
什么是线性代数(Linear algebra)?
什么是代数 代数的英文是Algebra,这个英文源自一个阿拉伯语“al jebr”,意思是 破碎部分的重新组合。这个意思促进了我代数的概念的理解。在代数中,我们会使用基本的算术(加、减、乘、除),便是对于要处理的量通常是未知的,我们会用一些字符,如字母来暂时代替这些量,这也是为什么它们会用字母来表示的原因,先用个占位符占着那个位置先。如a+b+bc = 100, 字母a、b和c都代表了一个数字。
Pytorch实用教程:pytorch中nn.Linear()用法详解 | 构建多层感知机 | nn.Module的作用 | nn.Sequential的作用
文章目录 1. nn.Linear()用法构造函数参数示例使用场景 2. 构建多层感知机步骤代码示例注意事项 3. 继承自nn.Module的作用是什么?1. 组织网络结构2. 参数管理3. 模型保存和加载4. 设备管理不继承 `nn.Module` 的后果
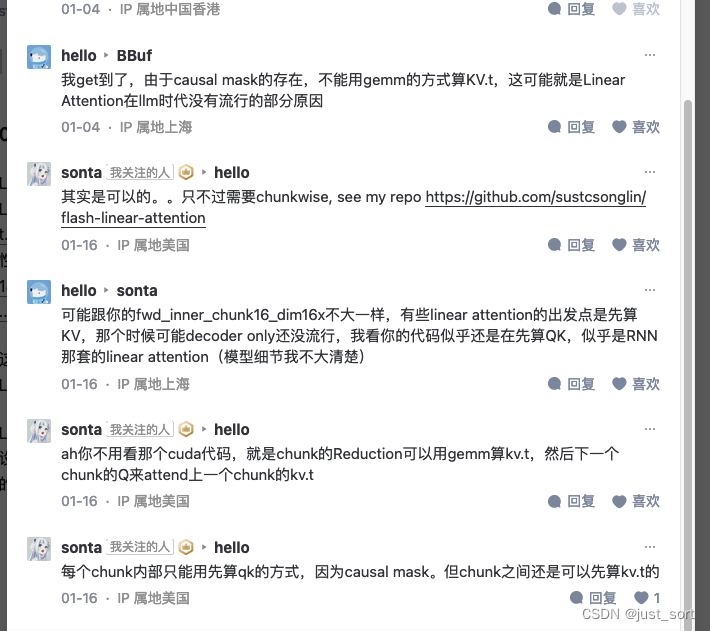
flash-linear-attention中的Chunkwise并行算法的理解
这里提一下,我维护的几三个记录个人学习笔记以及社区中其它大佬们的优秀博客链接的仓库都获得了不少star,感谢读者们的认可,我也会继续在开源社区多做贡献。github主页:https://github.com/BBuf ,欢迎来踩 0x0. 前言 我之前解读过causal linear attention的cuda实现,文章见:https://zhuanlan.zhihu.com/p/673

Pytorch_linear
Linear 对输入数据应用线性变换:y = xA^T + b torch.nn.Linear(in_features, out_features, bias=True) 参数 in_features 每个输入样本的大小out_features 每个输出样本的大小bias 若为False,layer不会学习附加偏差b shape 输入: (N, ∗, H_in),其中 ∗ 代表任意
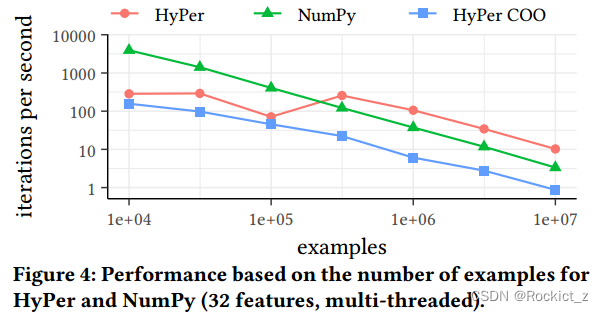
【论文阅读】Machine Learning, Linear Algebra, and More: Is SQL All You Need?
文章目录 摘要一、介绍二、SQL算法原语2.1、Variables2.2、Functions2.3、Conditions2.4、Loops2.5、Errors 三、案例研究3.1、对数据库友好的SQL映射3.2、性能结果 四、结论以及未来工作 摘要 尽管SQL在简单的分析查询中无处不在,但它很少用于更复杂的计算,如机器学习、线性代数和其他计算密集型算法。这些算法通常以过程
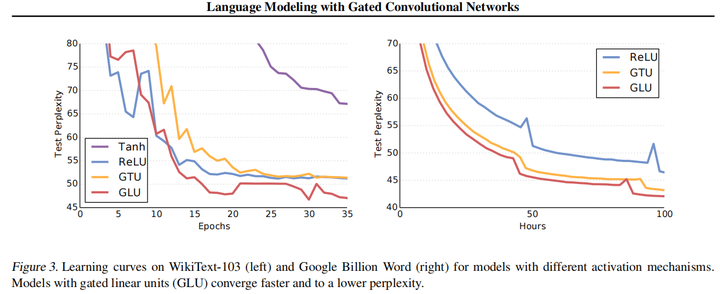
GLU(Gated Linear Unit) 门控线性单元
文章目录 一、RNN二、GLU2.1 整体结构2.2 输入层(Input Sentence+Lookup Table)2.3 中间层(Convolution+Gate)2.4 输出层(Softmax)2.5 实验结果2.6 实现代码 三、RNN与GLU的对比参考资料 GLU可以理解为能够并行处理时序数据的CNN网络架构,即利用CNN及门控机制实现了RNN的功能。优点在进行时序数据处