本文主要是介绍神经网络 torch.nn---Linear Layers(nn.Linear),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
torch.nn - PyTorch中文文档 (pytorch-cn.readthedocs.io)
torch.nn — PyTorch 2.3 documentation
nn.Linear
torch.nn.Linear(in_features, out_features, bias=True, device=None, dtype=None)
参数:
- in_features - 每个输入样本的大小
- out_features - 每个输出样本的大小
- bias - 若设置为False,这层不会学习偏置。默认值:True
形状:
- 输入: (N,in_features)(N , in_features)
- 输出: (N,out_features)(N , out_features)
变量:
- weight -形状为(out_features x in_features)的模块中可学习的权值
- bias -形状为(out_features)的模块中可学习的偏置
计算公式:

代码实例讲解
import torch
import torchvision
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoaderdataset = torchvision.datasets.CIFAR10(root='./dataset', train=False, transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=64,drop_last=True)
# shuffle 是否打乱 False不打乱
# drop_last 最后一轮数据不够时,是否舍弃 true舍弃
class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()self.linear1 = Linear(196608, 10)def forward(self, x):output = self.linear1(x)return outputtudui = Tudui()for data in dataloader:imgs, targets = dataprint(imgs.shape) #torch.Size([16, 3, 32, 32])output= torch.flatten(imgs)# output = torch.reshape(imgs,(1, 1, 1, -1))print(output.shape) #torch.Size([1, 1, 1, 196608])output = tudui.forward(output)print(output.shape)部分输出结果:
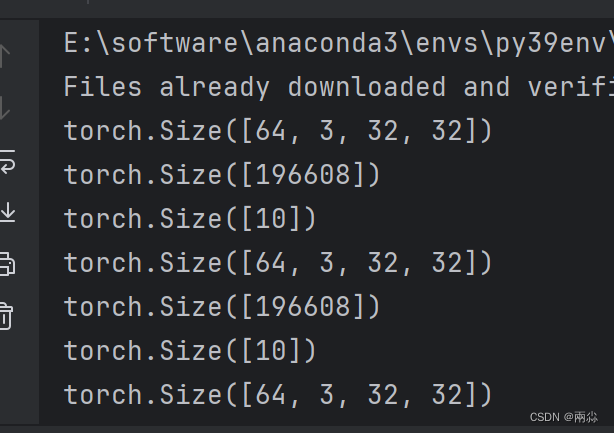
torch.flatten() 和torch.reshape()
output= torch.flatten(imgs)
output = torch.reshape(imgs,(1, 1, 1, -1))以上两行代码都是将图像展开成一行
-
torch.flatten() 和torch.reshape() 的区别:
-
torch.flatten更方便,可以直接把图像变成一行
-
torch.reshape功能更强大,可任意指定图像尺寸
-
这篇关于神经网络 torch.nn---Linear Layers(nn.Linear)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









