本文主要是介绍基于简化版python+VGG+MiniGoogLeNet的智能43类交通标志识别—深度学习算法应用(含全部python工程源码)+数据集+模型(一),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 前言
- 总体设计
- 系统整体结构图
- 系统流程图
- 运行环境
- Python环境
- Anaconda环境
- 模块实现
- 1. 数据预处理
- 相关其它博客
- 工程源代码下载
- 其它资料下载

前言
本项目专注于解决出国自驾游特定场景下的交通标志识别问题。借助Kaggle上的丰富交通标志数据集,我们采用了VGG和GoogLeNet等卷积神经网络模型进行训练。通过对网络架构和参数的巧妙调整,致力于提升模型在不同类型交通标志识别方面的准确率。
首先,我们选择了Kaggle上的高质量交通标志数据集,以确保训练数据的多样性和丰富性。接着,采用VGG和GoogLeNet等先进的卷积神经网络模型,这些模型在图像分类任务上表现卓越。
通过巧妙的网络架构和参数调整,本项目致力于提高模型的准确率。我们深入研究了不同交通标志的特征,使网络更有针对性地学习这些特征,从而增强模型在复杂场景下的泛化能力。
最终,本项目旨在为出国自驾游的用户提供一个高效而准确的交通标志识别系统,以提升驾驶安全性和用户体验。这一创新性的解决方案有望在自动驾驶和智能导航等领域产生深远的影响。
总体设计
本部分包括系统整体结构图和系统流程图。
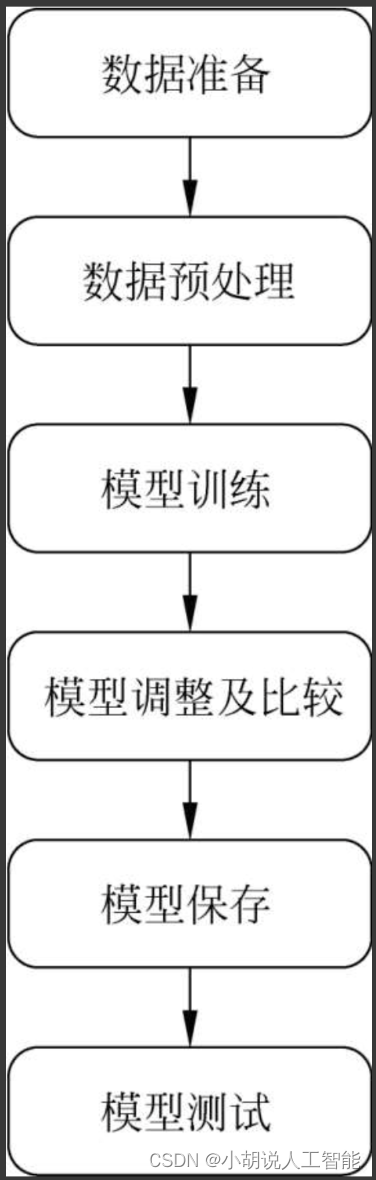
系统整体结构图
系统整体结构如图所示。
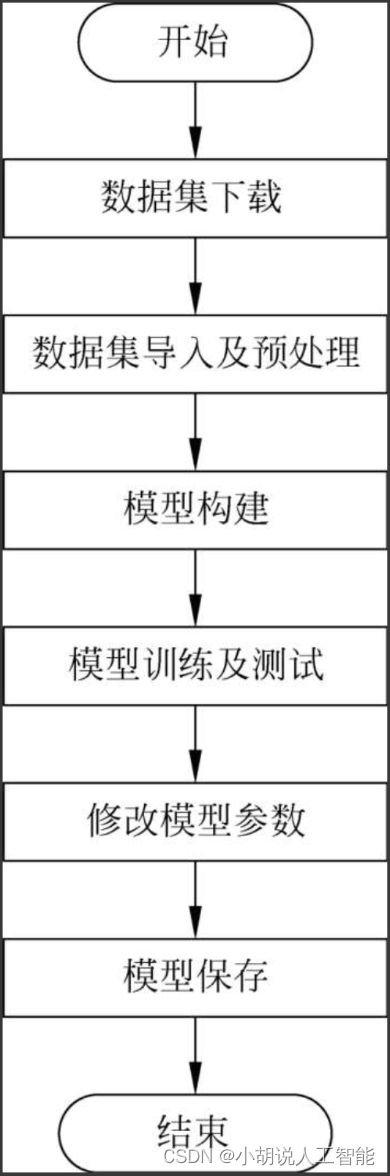
系统流程图
系统流程如图所示。
运行环境
本部分包括 Python 环境、Anaconda环境。
Python环境
需要Python 3.6及以上配置,在Windows环境下推荐下载Anaconda完成Python所需环境的配置,下载地址为https://www.anaconda.com/,也可下载虚拟机在Linux环境下运行代码。
鼠标右击“我的电脑”,单击“属性”,选择高级系统设置。单击“环境变量”,找到系统变量中的Path,单击“编辑”然后新建,将Python解释器所在路径粘贴并确定。
Anaconda环境
下载Anaconda,下载地址为:https://www.anaconda.com/。
打开Anaconda Prompt,用清华镜像安装CPU版本的TensorFlow,输入命令:
pip install tensorflow==1.14.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
需要安装其他库,输入以下命令:
pip install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install scikit-learn -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install scikit-image -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install imutils -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple
模块实现
本项目包括3个模块:数据预处理、模型构建、模型训练及保存。下面分别给出各模块的功能介绍及相关代码。
1. 数据预处理
本项目使用德国交通标志识别基准数据集(GTSRB),此数据集包含50000张在各种环境下拍摄的交通标志图像,下载地址为:https://www.kaggle.com/datasets/meowmeowmeowmeowmeow/gtsrb-german-traffic-sign。数据集下载完成后,导入数据并进行预处理,相关代码如下:
import matplotlib
from tensorflow.keras.preprocessing.image importlImageDataGenerator
from tensorflow.keras.utils import to categorical
from tensorflow,keras.optimizers import Adam
from sklearn.metrics import classification_report
from skimage import transform
from skimage import exposure
from skimage import io
import matplotlib.pyplot as plt
import numpy as np
import random
import os
GTSRB数据集已经划分为训练集和测试集,定义load_split()函数导入训练集、测试集的图像数据和标签。因为属于同一类的图像相邻,需要打乱图像以保证训练效果。通过统计分析得到全部图像的分辨率,如图所示,有极少数图像像素超过100×100。为便于训练,将图像像素统一调整为32×32。由于图像的对比度较低,调用skimage库的equalize_adapthist()函数,使用自适应直方图均衡算法(CLAHE)增加图像的对比度。

load_split()函数的相关代码如下:
def load_split(basePath, csvPath):#初始化data和labels列表data = []labels = []#加载存有训练集和测试集图像存储地址和标签的csv表格,去除空格,通过换行符识别各行
#并去除第一行标题行rows = open(csvPath).read().strip().split("\n")[1:]#打乱rows的各行random.shuffle(rows)for (i, row) in enumerate(rows):#每导入1000张图像后提示if i > 0 and i % 1000 == 0:print("[INFO] processed {} total images".format(i))#取csv表格最后的两列:标签和存储地址(label, imagePath) = row.strip().split(",")[-2:]#写出完整的图像存储地址imagePath = os.path.sep.join([basePath, imagePath])#读取图像数据image = io.imread(imagePath)#统一将图像调整为32*32像素image = transform.resize(image, (32, 32))#增加图像的对比度image = exposure.equalize_adapthist(image, clip_limit=0.1)#将当前图像的数据和标签添加到data和labels列表data.append(image)labels.append(int(label))data = np.array(data)labels = np.array(labels)return (data, labels)
导入图像各类别的具体名称,通过调用load_split()函数获得训练集、测试集的图像数据和标签,将图像的数据范围从[0,225]调整为[0,1],图像标签One-Hot编码,相关代码如下:
#从signnames.csv表格中获取图像各类别的具体名称,该表格共两列,第二列是类别名称
labelNames = open("signnames.csv").read().strip().split("\n")[1:]
labelNames = [l.split(",")[1] for l in labelNames]
trainPath = os.path.sep.join(['gtsrb-german-traffic-sign', "Train.csv"])
testPath = os.path.sep.join(['gtsrb-german-traffic-sign', "Test.csv"])
print("[INFO] loading training and testing data...")
#通过调用load_split()函数获得训练集、测试集的图像数据和标签
(trainX, trainY) = load_split('gtsrb-german-traffic-sign', trainPath)
(testX, testY) = load_split('gtsrb-german-traffic-sign', testPath)
#把RGB图像的数据范围从[0,225]调整为[0,1]
trainX = trainX.astype("float32") / 255.0
testX = testX.astype("float32") / 255.0
#One-hot编码图像的标签
numLabels = len(np.unique(trainY))
trainY = to_categorical(trainY, numLabels)
testY = to_categorical(testY, numLabels)
相关其它博客
基于简化版python+VGG+MiniGoogLeNet的智能43类交通标志识别—深度学习算法应用(含全部python工程源码)+数据集+模型(二)
基于简化版python+VGG+MiniGoogLeNet的智能43类交通标志识别—深度学习算法应用(含全部python工程源码)+数据集+模型(三)
工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。
这篇关于基于简化版python+VGG+MiniGoogLeNet的智能43类交通标志识别—深度学习算法应用(含全部python工程源码)+数据集+模型(一)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






