本文主要是介绍CTR介绍,数据集往往为表格形式,训练集使用历史的日志数据,然后进行特征归一化、离散化和特征哈希等操作,最终一条训练集为一行多列的二分类任务。,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在CTR预估任务中数据集往往为表格形式,训练集使用历史的日志数据,然后进行特征归一化、离散化和特征哈希等操作,最终一条训练集为一行多列的二分类任务。
在CTR训练过程损失函数可以使用交叉熵:
![]()
CTR模型的发展可以分为特征工程和模型两个部分,在早期CTR模型主要依赖人工特征工程,然后随着深度学习的发展逐步依赖复杂的网络模型设计。
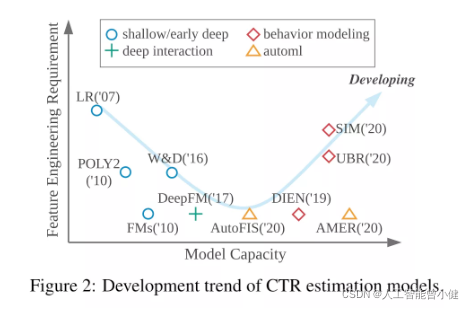
LR
在早期逻辑回归LR是最基础的CTR模型,模型简单且训练速度很快,m为特征个数。
![]()
FM
Factorization machine (FM)给每个特征分配个隐含的向量,可以自动的完成特征交叉:

其中特征i与特征j的相关性通过![]() 来完成自动学习。
来完成自动学习。
这篇关于CTR介绍,数据集往往为表格形式,训练集使用历史的日志数据,然后进行特征归一化、离散化和特征哈希等操作,最终一条训练集为一行多列的二分类任务。的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






