归一化专题

【数据分享】2000—2023年我国省市县三级逐月归一化植被指数(NDVI)数据(Shp/Excel格式)
之前我们分享过2000—2023年逐月归一化植被指数(NDVI)栅格数据(可查看之前的文章获悉详情),该数据来源于NASA定期发布的MOD13A3数据集!很多小伙伴拿到数据后反馈栅格数据不太方便使用,问我们能不能把数据处理为更方便使用的Shp和Excel格式的数据! 我们特地对数值在-0.2—1之间的NDVI栅格数据进行了处理,将2000-2023年逐月的归一化植被指数栅格分别按照我国省级行政边

深度学习速通系列:归一化和批量归一化
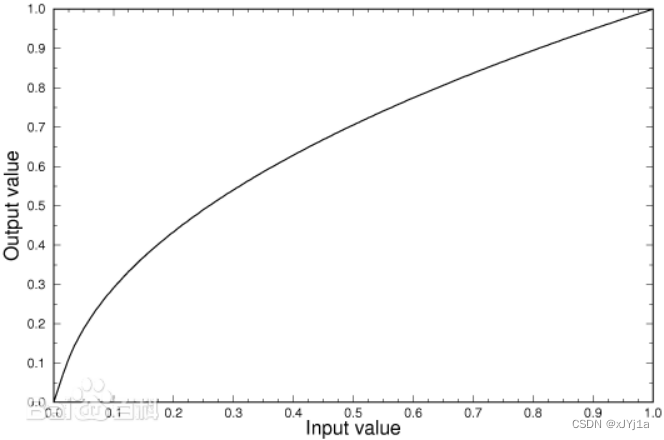
在深度学习中,归一化和批量归一化是两种常用的技术,它们有助于提高模型的训练效率和性能。下面详细解释这两种技术: 归一化(Normalization) 归一化是指将数据的数值范围调整到一个特定的区间,通常是[0, 1]或者[-1, 1],或者使其具有零均值和单位方差。这样做的目的是减少不同特征之间的数值范围差异,使得模型训练更加稳定和高效。 常见的归一化方法包括: 最小-最大归一化(Min

【无标题】【Datawhale X 李宏毅苹果书 AI夏令营】批量归一化
1、批量归一化的作用 批量归一化(Batch Normalization,BN)的把误差曲面变得平滑,使训练能够得到快速收敛; 训练过程的优化:使用自适应学习率等比较进阶的优化训练方法; 训练对象的优化:批量归一化可以改变误差表面,让误差表面比较不崎岖 参数 w i w_i wi是指训练参数或者训练的目标 1.1 特征归一化 当输入的特征,每一个维度的值,它的范围差距很大的时候,我们就可能
Datawhale X 李宏毅苹果书 AI夏令营 进阶 Task3-批量归一化+卷积神经网络
目录 1.批量归一化1.1 考虑深度学习1.2 测试时的批量归一化1.3 内部协变量偏移 2.卷积神经网络2.1 观察 1:检测模式不需要整张图像2.2 简化 1:感受野2.3 观察 2:同样的模式可能会出现在图像的不同区域2.4 简化 2:共享参数2.5 简化 1 和 2 的总结2.6 观察 3:下采样不影响模式检测2.7 简化 3:汇聚2.8 卷积神经网络的应用:下围棋 1.

Pytorch中不同的Norm归一化详细讲解
在做项目或者看论文时,总是能看到Norm这个关键的Layer,但是不同的Norm Layer具有不同的作用,准备好接招了吗?(本文结论全部根据pytorch官方文档得出,请放心食用) 一. LayerNorm LayerNorm的公示如下: y = x − E [ x ] Var [ x ] + ϵ ∗ γ + β y=\frac{x-\mathrm{E}[x]}{\sqrt{\op
波导模式分析-归一化截止波数
归一化截止波数是指波导或传输线中的截止波数相对特定参考波数的归一化值。通常在波导分析中,它通过与自由空间波数的比值来表示。你可以根据给定的截止频率来计算归一化截止波数。 截止波数: 对于某一传播模式(如TE、TM模式),波导中的截止波数与截止频率之间的关系是: 其中: 是波导中的截止波数是波导中的截止频率是相应模式下的相速度 相速度: 相速度(Phase Velocity)是在波动

CV-CNN-2015:GoogleNet-V2【首次提出Batch Norm方法:每次先对input数据进行归一化,再送入下层神经网络输入层(解决了协方差偏移问题)】【小的卷积核代替掉大的卷积核】
GoogLeNet凭借其优秀的表现,得到了很多研究人员的学习和使用,因此GoogLeNet团队又对其进行了进一步地发掘改进,产生了升级版本的GoogLeNet。 GoogLeNet设计的初衷就是要又准又快,而如果只是单纯的堆叠网络虽然可以提高准确率,但是会导致计算效率有明显的下降,所以如何在不增加过多计算量的同时提高网络的表达能力就成为了一个问题。 Inception V2版本的解决方案就是修

GEE案例——基于光谱混合分析(SMA)的归一化差异水分指数(NDWFI)的水体监测
简介 本研究旨在开发一种新型水指数,以提高利用卫星图像感知和监测 SW 的能力,同时避开大量取样和复杂建模等劳动密集型技术,从而改进大规模 SW 测绘。 具体目标如下 (a) 引入一种新的水体指数,该指数的明确设计目的是改进对次要水体和易变水体的提取,使其非常适合于大规模、长期的水体分布图绘制;(b) 调查该新指数在阐明水体动态时空模式方面的可行性,从而推进对跨时空水体分布变化的理解;(c) 通
【机器学习】【数据预处理】数据的规范化,归一化,标准化,正则化
数据的规范化,归一化,标准化,正则化,这几个破词整得我头晕,首先这些词就没规范好,对数据做实验更晕,网上狂搜一阵后,发现数据归一化,标准化,正则化,还是有差别 数据规范化 一种是针对数据库的解释 规范化理论把关系应满足的规范要求分为几级,满足最低要求的一级叫做第一范式(1NF),在第一范式的基础上提出了第二范式(2NF),在第二范式的基础上又提出了第三范式(3NF),以后又提出
Layer Normalization(层归一化)里的可学习的参数
参考pyttorch官方文档: LayerNorm — PyTorch 2.4 documentation 在深度学习模型中,层归一化(Layer Normalization, 简称LN)是一种常用的技术,用于稳定和加速神经网络的训练。层归一化通过对单个样本内的所有激活进行归一化,使得训练过程更加稳定。 关于层归一化是否可训练,其实层归一化中确实包含可训练的参数。具体来说,层归一化会对激活值

GEE 更新和优化:利用GEE在线处理1985-2024年NDVI、EVI、SAVI、NDMI等指数归一化教程!(Landsat C02 数据)
简介 本次的归一化教程,优化了数据去云,预处理等过程,同事将landsat 5/7/8集合分别进行了数据整合,也就是原始波段的处理,从而我们可以调用1985-至今任何一个时期的影像进行归一化处理。具体的原文介绍 请看原始的博客 原始博客 利用GEE(Google Earth Engine)在线处理NDVI、EVI、SAVI、NDMI等指数归一化教程!_gee计算ndwi-CSDN博客 代码

批量归一化(Datawhale X 李宏毅苹果书 AI夏令营)
批量归一化(Batch Normalization, BN)是一种在深度学习中常用的技术,其目的是提高模型训练的稳定性和效率。BN的基本概念是对每一层的输入进行标准化处理,使得每层的输入数据在训练过程中保持均值为零、方差为一。这种处理方式有助于减轻梯度消失和梯度爆炸的问题,加速模型的收敛。 优化问题的困难 尽管在理论上,误差表面可能是凸的,但在深度学习中训练仍然

【Python机器学习】NLP分词——利用分词器构建词汇表(六)——词汇表归一化
目录 大小写转换 词干还原 词形归并 使用场景 词汇表大小对NLP流水线的性能有很大的影响,有一种减少词汇表大小的方法是将词汇表归一化以便意义相似的词条归并成单个归一化的形式。这样做一方面可以减少需要再词汇表中保留的词条数,另一方面也会提高语料库中意义相似但是拼写不同的词条或者n-gram之间的语义关联。 大小写转换 当两个单词只有大小写形式不同时,大小写转换会用来把笔不同的
pandas 数据归一化以及行删除例程
pandas 数据归一化以及行删除例程 #coding:utf8import pandas as pdimport numpy as npfrom pandas import Series,DataFrame# 如果有id列,则需先删除id列再进行对应操作,最后再补上# 统计的时候不需要用到id列,删除的时候需要考虑# delete rowdef row_del(df, num_
caffe中BatchNorm层和Scale层实现批量归一化(batch-normalization)注意事项
caffe中实现批量归一化(batch-normalization)需要借助两个层:BatchNorm 和 Scale BatchNorm实现的是归一化 Scale实现的是平移和缩放 在实现的时候要注意的是由于Scale需要实现平移功能,所以要把bias_term项设为true 另外,实现BatchNorm的时候需要注意一下参数use_global_stats,在训练的时候设为false,
归一化(Normalization)与标准化(Standardization)
在机器学习和数据挖掘中,经常会听到两个名词:归一化(Normalization)与标准化(Standardization)。它们具体是什么?带来什么益处?具体怎么用?本文来具体讨论这些问题。 一、是什么 1. 归一化 常用的方法是通过对原始数据进行线性变换把数据映射到[0,1]之间,变换函数为: x′=x−minmax−min x′=x−minmax−min 其中 min
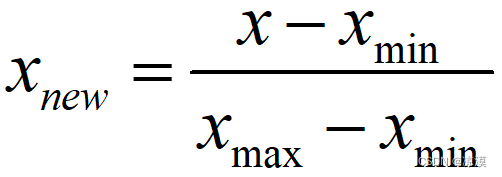
数据预处理——调整方差、标准化、归一化(Matlab、python)
对数据的预处理: (a)、调整数据的方差; (b)、标准化:将数据标准化为具有零均值和单位方差;(均值方差归一化(Standardization)) (c)、最值归一化,也称为离差标准化,是对原始数据的线性变换,使结果值映射到[0 , 1]之间 (a)、调整数据的方差 均方差=标准差 方差的定义是:离平均值的平方距离的平均。 (b)、标准化 也称为均值归一化(me
归一化在神经网络训练中的作用
归一化是深度学习中的一个重要概念,特别是在神经网络的训练过程中,它起着至关重要的作用。本文将深入探讨归一化在神经网络训练中的意义、不同的归一化方法,以及通过具体例子来说明归一化的实际效果。 一、什么是归一化? 归一化,指的是通过比例缩放,将数据调整至一个特定的范围(通常是0到1或者-1到1)。在神经网络中,归一化通常是指对输入数据的处理,目的是为了消除数据特征之间数量级的差异,有时也指模型内部
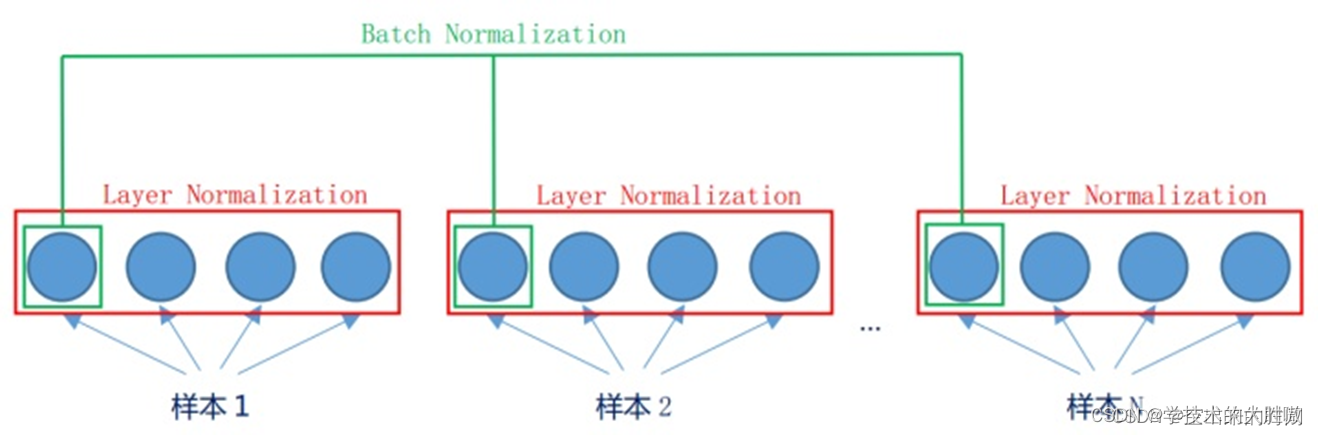
批量归一化(BN)和层归一化(LN)的区别
批量归一化(Batch Normalization, BN)和层归一化(Layer Normalization, LN)是深度学习中常用的两种归一化技术,它们主要用于解决训练过程中的内部协变量偏移问题,加速模型收敛和提高稳定性。 1. 为什么需要归一化 由于数据来源的不同,不同数据的特征分布是不一致的。模型在训练过程中学习了这个批次的特征分布,如果下一批次的特征分布截然不同,那么模型的参数就会

Transformer详解(4)-前馈层残差连接层归一化
1、前馈层 前馈层接收自注意力层的输出作为输入。 from torch import nnimport torch.nn.functional as Fclass FeedForward(nn.Module):def __init__(self, d_model=512, d_ff=2048, dropout=0.1):super().__init__()# d_ff 默认设置为2048s
神经网络中的归一化操作
神经网络中的归一化 文章目录 神经网络中的归一化概述最大最小归一化标准归一化批归一化层归一化实例归一化组归一化权重归一化 概述 由于样本不同特征的量纲或量纲单位不同,变化区间也处于不同数量级, 使用原始样本训练机器学习或深度学习模型,不同特征对模型的影响会不同,这也导致训练所得的模型缺乏鲁棒性。 归一化(Normalization)是一种常见的数据预处理方法,它将数据映射成

CCF20220601——归一化处理
CCF20220601——归一化处理 代码如下: #include<bits/stdc++.h>using namespace std;int main(){int n,a[1000],sum=0;scanf("%d",&n);for(int i=1;i<=n;i++){scanf("%d",&a[i]);sum+=a[i];}double aver=1.0,b=0.0,d=1.0
【Python-图结构准备】“pickled object“、 调整邻接矩阵使其对称、图加自环 图邻接矩阵归一化、稀疏邻接矩阵格式转换
引言:python代码学习,本博客对python的"pickled object" (腌制对象,也叫序列化对象), 调整邻接矩阵使其对称、图加自环 & 图邻接矩阵归一化、稀疏邻接矩阵格式转换从代码实现的角度进行介绍。我们先引入一段代码,通过这段代码来解释相应的知识点。 with open('data/' + args.dataset + '_mean_' + args.diffusion_mod