本文主要是介绍经典文献阅读之--RenderOcc(使用2D标签训练多视图3D Occupancy模型),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
0. 简介
3D占据预测在机器人感知和自动驾驶领域具有重要的潜力,它将3D场景量化为带有语义标签的网格单元。最近的研究主要利用3D体素空间中的完整占据标签进行监督。然而,昂贵的注释过程和有时模糊的标签严重限制了3D占据模型的可用性和可扩展性。为了解决这个问题,《RenderOcc: Vision-Centric 3D Occupancy Prediction with 2D Rendering Supervision》提出了RenderOcc,一种新的范式,用于仅使用2D标签训练3D占据模型。具体地,我们从多视图图像中提取类似NeRF的3D体积表示,并利用体积渲染技术建立2D渲染,从而能够通过2D语义和深度标签直接进行3D监督。此外,我们引入了一种辅助射线方法来解决自动驾驶场景中稀疏视角的问题,利用连续帧来为每个对象构建全面的2D渲染。据我们所知,RenderOcc是首次尝试仅使用2D标签训练多视图3D占据模型,减少了对昂贵的3D占据注释的依赖。大量实验证明,RenderOcc实现了与完全受3D标签监督的模型相当的性能,突显了这种方法在实际应用中的重要性。我们的代码可在Github找到。
1. 主要贡献
针对上述问题,我们引入了RenderOcc,这是一种新的范式,用于训练3D占据模型,使用2D标签,而不依赖于任何3D空间注释。如图1所示,RenderOcc的目标是消除对3D占据标签的依赖,仅依靠像素级的2D语义在网络训练期间进行监督。具体而言,它从多视图图像构建了类似NeRF的3D体积表示,并利用先进的体积渲染技术生成2D渲染。这种方法使我们能够仅使用2D语义和深度标签提供直接的3D监督。通过这种2D渲染监督,模型通过分析来自各种摄像机的相交锥体射线来学习多视图一致性,从而更深入地理解3D空间中的几何关系。值得注意的是,自动驾驶场景通常涉及有限的视角,这可能会影响渲染监督的有效性。考虑到这一点,我们引入了辅助射线的概念,利用相邻帧的射线来增强当前帧的多视图一致性约束。此外,我们还开发了一种动态采样训练策略,用于筛选出不对齐的射线,并同时减轻与其相关的额外训练成本。本文主要贡献总结如下:
- 我们引入了RenderOcc,这是一个基于2D渲染监督的3D占据框架。我们首次尝试仅使用2D标签训练多视图3D占据网络,摒弃了昂贵且具有挑战性的3D注释。
- 为了从有限的视角学习有利的3D体素表示,我们引入了辅助射线来解决自动驾驶场景中稀疏视角的挑战。同时,我们设计了一种动态采样训练策略,用于平衡和净化辅助射线。
- 大量实验证明,与受3D标签监督的基线相比,RenderOcc在仅使用2D标签时取得了竞争性的性能。这展示了2D图像监督在3D占据训练中的可行性和潜力。
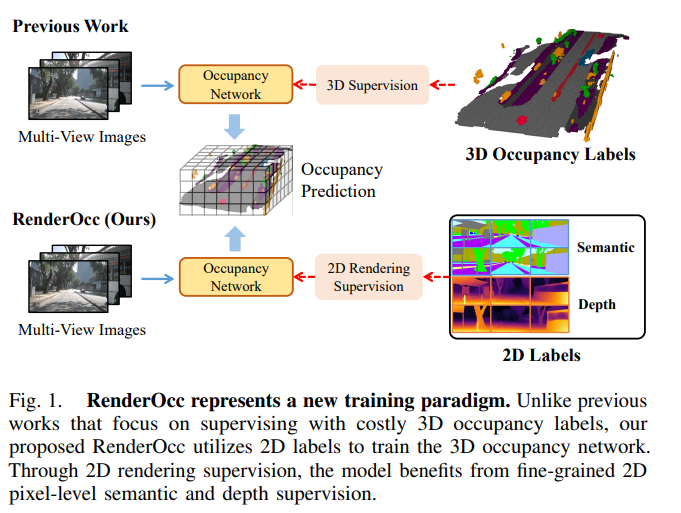
图1. RenderOcc代表了一种新的训练范式。与以往侧重于使用昂贵的3D占据标签进行监督的作品不同,我们提出的RenderOcc利用2D标签来训练3D占据网络。通过2D渲染监督,模型可以从细粒度的2D像素级语义和深度监督中受益。
2. 问题设置
我们的目标是利用多摄像头RGB图像来预测周围场景的密集语义体积,称为3D占据情况。具体来说,对于时间戳 t t t的车辆,我们将 N N N个图像 { I 1 , I 2 , ⋅ ⋅ ⋅ I N } \{I^1,I^2,···I^N\} {I1,I2,⋅⋅⋅IN}作为输入,并预测3D占据情况 O ∈ R H × W × D × L O ∈ \mathbb{R}^{H×W×D×L} O∈RH×W×D×L作为输出,其中 H H H、 W W W、 D D D表示体积的分辨率, L L L表示类别数量(包括空)。形式上,3D占据情况的预测可以被表述为:
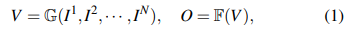
G \mathbb{G} G是一个神经网络,从 N N N视图图像中提取3D体积特征 V ∈ R H × W × D × C V ∈ \mathbb{R}^{H×W×D×C} V∈RH×W×D×C,其中 C C C表示特征维度。 F F F负责将 V V V转换为占据表示,先前的研究[7],[8]倾向于使用MLP实现每个体素的分类。考虑到所有现有方法都需要完整的3D占据标签来监督体素级别的分类,我们设计了一个新的概念来实现 F \mathbb{F} F,并仅使用2D像素级标签来监督 { G , F } \{\mathbb{G},\mathbb{F}\} {G,F}。
3. 整体框架
我们的整体框架如图2所示。在第4节中,我们首先使用2D到3D网络 G \mathbb{G} G从多视角RGB图像中提取3D体积特征 V V V。需要注意的是,我们的框架对于 G \mathbb{G} G的实现不敏感,并且可以灵活地在各种BEV/Occupancy编码器之间进行切换,比如[18],[19],[29]。接下来在第5节中,我们为每个体素预测体积密度 σ σ σ和语义logits S S S,以生成语义密度场(SDF)。随后,我们从SDF进行体积渲染,并使用2D标签优化网络。最后在第6节中,我们阐述了用于解决自动驾驶场景中稀疏视角问题的体积渲染的辅助射线训练策略。
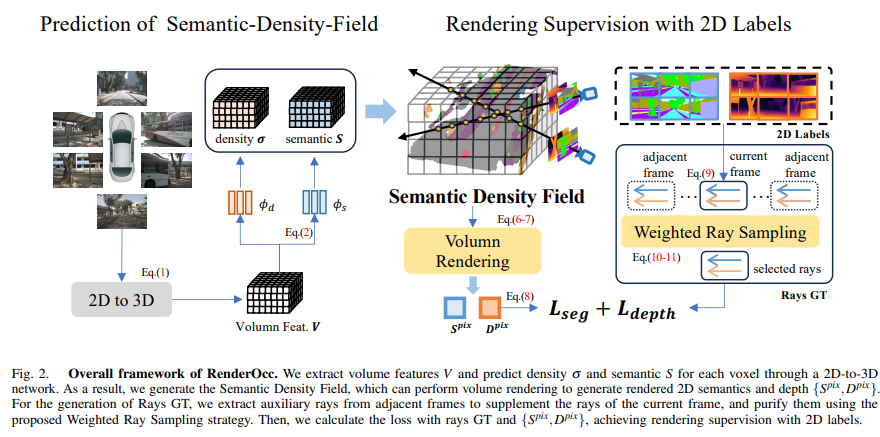
图2. RenderOcc的整体框架。我们通过2D到3D网络提取体积特征 V V V,并预测每个体素的密度 σ σ σ和语义 S S S。因此,我们生成了语义密度场,可以执行体积渲染以生成渲染的2D语义和深度 { S p i x , D p i x } \{S^{pix},D^{pix}\} {Spix,Dpix}。对于Rays GT的生成,我们从相邻帧中提取辅助射线,以补充当前帧的射线,并使用提出的加权射线采样策略对其进行净化。然后,我们使用射线GT和 { S p i x , D p i x } \{S^{pix},D^{pix}\} {Spix,Dpix}计算损失,实现了使用2D标签进行渲染监督。
4. 语义密度场
现有的3D占据方法从多视角图像中提取体积特征 V V V,并进行体素级分类[29],[30],[9],[6]以生成3D语义占据。为了利用2D像素级监督,我们的RenderOcc创新地将 V V V转换为一种称为语义密度场(SDF)的多功能表示。给定一个体积特征图 V ∈ R H × W × D × C V ∈ \mathbb{R}^{H×W×D×C} V∈RH×W×D×C,SDF通过两种表示来编码场景:体积密度 σ ∈ R H × W × D σ ∈ \mathbb{R}^{H×W×D} σ∈RH×W×D和语义logits S ∈ R H × W × D × L S ∈ \mathbb{R}^{H×W×D×L} S∈RH×W×D×L。具体来说,我们简单地采用两个MLP { φ d , φ s } \{φ_d,φ_s\} {φd,φs}来构建SDF,其公式为
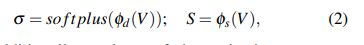
σ σ σ另外还使用softplus激活函数,以确保密度值不会变为负数。基于SDF,我们获得了从任何视角进行语义渲染的能力,并在训练过程中获得了二维监督优化,这将在第5节部分进行解释
优化后,SDF可以直接转换为3D占据结果。我们使用 σ σ σ过滤出占据的体素,并根据 S S S确定它们的语义类别。该过程可以形式化如下:

τ τ τ作为 σ σ σ的阈值,用于确定一个体素是否被占据。
5. 利用2D标签进行渲染监督
我们利用体积渲染来构建表面法线和2D像素之间的桥梁,从而通过2D标签方便地进行监督。具体来说,我们利用相机的内参和外参参数从当前帧提取3D射线,其中每个2D像素对应于从相机发出的一条3D射线。每条射线 r r r携带着对应像素的语义和深度标签 { S ^ p i x ( r ) , D ^ p i x ( r ) } \{\hat{S}^{pix}(r),\hat{D}^{pix}(r)\} {S^pix(r),D^pix(r)}。同时,我们基于SDF进行体积渲染[40],得到渲染的语义 S p i x ( r ) S^{pix}(r) Spix(r)和深度 D p i x ( r ) D^{pix}(r) Dpix(r),用于计算与2D标签 { S ^ p i x ( r ) , D ^ p i x ( r ) } \{\hat{S}^{pix}(r),\hat{D}^{pix}(r)\} {S^pix(r),D^pix(r)}的损失。
为了渲染像素的语义和深度,我们在射线 r r r上预定义的范围内对射线上的 K K K个点 { z k } k = 1 K \{z_k\}^K_{k=1} {zk}k=1K进行采样。然后可以通过计算累积透射率 T T T和终止概率 α α α来得到点 z k z_k zk的信息。
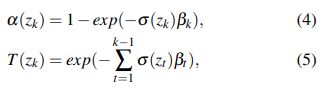
β k = z k + 1 − z k β_k = z_{k+1} − z_k βk=zk+1−zk是两个相邻点之间的距离。最后,我们使用 { z k } \{z_k\} {zk}查询SDF,并将它们累积起来,以获得渲染的语义和深度。
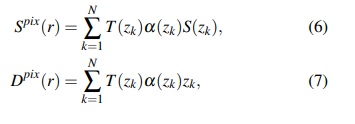
对于损失函数,交叉熵损失 L s e g L_{seg} Lseg和SILog损失 L d e p t h L_{depth} Ldepth [41] 被用来监督语义和深度。我们还引入了失真损失[35] 和TV损失[42] 作为SDF的正则化,称为 L r e g L_{reg} Lreg。因此,整体损失可以通过计算得到。

6. 辅助光线:增强多视角一致性
通过第III-D节中的2D渲染监督,模型可以从多视角一致性约束中受益,并学会考虑体素之间的空间遮挡关系。然而,在单帧中,周围摄像机的视角覆盖非常稀疏,它们的重叠范围也有限。因此,大多数体素无法同时被具有显著视角差异的多条光线采样,这很容易导致局部最优解。因此,我们引入了来自相邻帧的辅助光线,以补充多视角一致性约束,如图3所示。
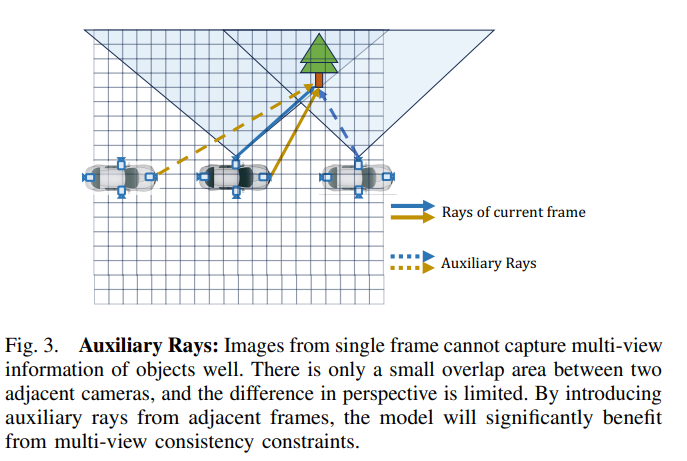
图3. 辅助光线:单帧图像无法很好地捕捉物体的多视角信息。相邻摄像头之间只有一个小的重叠区域,并且透视差异有限。通过引入相邻帧的辅助光线,模型将显著受益于多视角一致性约束。
6.1 辅助光线的生成
具体而言,对于当前帧索引为 t t t,我们选择附近的 M a u x M_{aux} Maux个相邻帧。对于每个相邻帧,我们分别生成光线,并将它们转换到当前帧,以获得最终的辅助光线 r a u x r_{aux} raux:
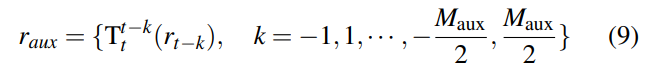
…详情请参照古月居
这篇关于经典文献阅读之--RenderOcc(使用2D标签训练多视图3D Occupancy模型)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







