本文主要是介绍tensorflow2中自定义损失、传递loss函数字典/compile(optimizer=Adam(lr = lr), loss= lambda y_true, y_pred: y_pred)理解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在阅读yolov3代码的时候有下面这样一样代码:
model.compile(optimizer=Adam(lr = lr), loss={'yolo_loss': lambda y_true, y_pred: y_pred}),这行代码在网上有人进行解释过,但是都是看的云里雾里,一般使用compile的时候我们都是直接传递的一个函数对象,这里竟然传递的是一个字典,对此很是不解。
经过大量的饿查阅别人写的博客:最后在这篇博客中得到了答案的启发:链接,这篇文章 写的很好,大家可以去看看。
我在上面文章的基础上,会尽量使用简单的语言来描述这个函数的作用,并给出一个例子帮助大家进行理解。
因为这里是在compile模型,因此,要理解其原委,我们还需要到其模型中去看起所以然,进入模型定义中,我们会发现有下面这样一个loss的层定义:
model_loss = Lambda(get_yolo_loss(input_shape, len(model_body.output), num_classes), output_shape = (1, ), name = 'yolo_loss',)([*model_body.output, *y_true])
而且我们会发现,这里面给该Lambda层起了一个名字:yolo_loss,是的。你没有看错,就是和前面compile里面的loss的键值一样,这是巧合吗?然而当我将这个name进行修改成其他名字的时候,发现无法进行训练,因此,我们可以确定,这个name就是在comple中进行引用的键值。间接性的将,上面的loss引用的是这里的这个Lambda层。但是否是这样呢?我们在上面的那篇博客中可以得到答案,的确是这样。
为了进一步的验证该猜想,我们自定义一个简单的层,然后将最后一层当做Loss层进行处理,及最后一层的输出是一个数,这个数既代表预测的结果,也用来表示函数的损失。
在这里我们定义一个简单的LSTM层来进行说明:
from tensorflow.keras.layers import *
from tensorflow.keras import backend as K
from tensorflow.keras.layers import Input, Lambda
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input,Embedding,LSTM,Dense
import tensorflow as tfword_size = 128
nb_features = 10
nb_classes = 10
encode_size = 64
margin = 0.1embedding = Embedding(nb_features,word_size) # 对单词进行编码
lstm_encoder = LSTM(encode_size) # LSTM层进行定义def encode(input): # 定义一个函数,进行层的传播return lstm_encoder(embedding(input))q_input = Input(shape=(100,)) # 定义一个输入
q_encoded = Dense(encode_size)(q_encoded) # 将LSTM层的输出放入全连接层进行整合loss = Lambda(lambda x: K.relu(0.001+x[0][:,1:2]+100),name="test_loss")([q_encoded]) # 随便写了一个算法 让第一个数据*0.001+100作为输出,然后让Dense层的输入通过该Lambda层,这一层也是最后一层,模型的整体组成请看下面model_train = Model(inputs=[q_input], outputs=loss) # 定义模型model_train.compile(optimizer='adam', loss={'test_loss':lambda y_true,y_pred: y_pred})# 对模型进行编译,这里也是本篇文章的重点,loss={'test_loss':lambda #y_true,y_pred: y_pred} 表示loss函数引用的是test_loss这个层,后面的两个#参数是tensorflow2中对loss进行重定义的标准输入,在这里表示直接输出预测#值。这样锁可能不太好理解,我们还可以将上面的compile换成下面这个形式:#model_train.compile(optimizer='adam', loss=lambda y_true,y_pred: y_pred)#这样是不是很好理解了呢?loss和之前的传递自定义函数是不是很向呢?想想在我们传递自定义loss函数的时候是怎么传递的,直接将一个函数对象赋给loss,是的,#这里的Lambda就是一个匿名对象,至于后面的参数这是标准的tensorflow自定义#loss必须要传递的链各个值: y_true,y_pred,不好理解的地方在于,这样不是直#接返回的y_predect嘛,是的,在Lambda函数中,我们要求函数直接返回预测值,#也就是这里的函数输出,这这个输出就是最后一层的输出,因此,通过这样定义,#我们即将最后一层当做输出,也将最后一层当做`loss`损失进行优化。t1 = tf.range(10) # 随便定义一个数据进行预测
y = tf.range(10) # 宿便定义一个输出,因为这里我们后面要进行优化,因此这个值随便定义。这里定义y只是为了瞒住fit的时候需要一个y值而已model_train.fit([t1], y, epochs=10) # 进行训练p = model_train.predict([5]) # 预测5这个数的lossprint(p) # 打印p的值模型的摘要:

训练的输出:

可以看到这里训练10步之后输出也即loss为99.57左右,那么可以猜想我们的预测下一个值的输出也应该在99.57左右,因为我们的输出即做预测值使用,也做Loss使用,那到底是不是这样呢?
预测输出:
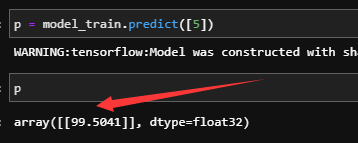
可以看到,这和我们的猜想是一样的,也验证了我们上面的说法。
这篇关于tensorflow2中自定义损失、传递loss函数字典/compile(optimizer=Adam(lr = lr), loss= lambda y_true, y_pred: y_pred)理解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





