lr专题

快速搞定“照片调色”!50000+Lr预设滤镜模板,一键让你照片不再丑!
照片调色不仅仅是调整颜色,更是一种艺术表达。通过巧妙地运用 LR 预设,可以突出照片的主题,增强情感共鸣。比如,在风景照片中,使用特定的预设可以让天空更蓝、草地更绿,让大自然的美丽更加生动地展现出来。 在人像摄影中,合适的 LR 预设可以让肤色更加自然、眼神更加明亮,让人物更加迷人。而且,LR 预设还可以根据不同的风格和场景进行定制,满足各种个性化的需求。如果你对照片调色还不是

Kaggle刷比赛的利器,LR,LGBM,XGBoost,Keras
刷比赛利器,感谢分享的人。 摘要 最近打各种比赛,在这里分享一些General Model,稍微改改就能用的 环境: python 3.5.2 XGBoost调参大全: http://blog.csdn.net/han_xiaoyang/article/details/52665396 XGBoost 官方API: http://xgboost.readthedocs.io/en

机器学习面试:请介绍下LR的损失函数?
在机器学习中,逻辑回归(Logistic Regression, LR)是一种广泛使用的分类算法,尤其适用于二分类问题。逻辑回归的损失函数主要是用来衡量模型预测值与真实值之间的差距。以下是对逻辑回归损失函数的详细介绍: 1. 逻辑回归的基本概念 逻辑回归通过一个sigmoid函数将线性组合的输入映射到0和1之间,公式如下: 其中,hθ(x)是预测的概率,θ是模型参数,x 是输入特征。

机器学习学习--Kaggle Titanic--LR,GBDT,bagging
参考,机器学习系列(3)_逻辑回归应用之Kaggle泰坦尼克之灾 http://www.cnblogs.com/zhizhan/p/5238908.html 机器学习(二) 如何做到Kaggle排名前2% http://www.jasongj.com/ml/classification/ 一、认识数据 1.把csv文件读入成dataframe格式 import pandas as

统计学习-逻辑回归(LR)和最大熵模型
逻辑回归(logistic regression) 是统计学习中的经典分类方法。最大熵是概率模型学习中的一个准则,将其推广到分类问题得到的最大熵模型(maximum entropy model)。LR和MEM都属于对数线性模型。 二项逻辑斯蒂回归模型 二项逻辑斯蒂回归模型是一种分类模型,由条件概率分布 P(Y|X) P(Y|X),形式为参数化的逻辑斯蒂分布。这里 X X随机变量为实数,YY随

GBDT与LR融合方案
GBDT与LR融合方案--CTR预估 转载原文:https://blog.csdn.net/lilyth_lilyth/article/details/48032119 1、 背景 CTR预估(Click-Through Rate Prediction)是互联网计算广告中的关键环节,预估准确性直接影响公司广告收入。CTR预估中用的最多的模
梧桐数据库(WuTongDB):数据库技术中LR算法详解
LR(Left-to-Right, Rightmost Derivation)算法是一种自底向上的语法分析方法,用于解析上下文无关文法。与 LL 分析器的自顶向下分析方式不同,LR 分析器从输入的最左侧开始读取符号,但通过“最右推导”来构建语法树。这意味着它试图在推导过程中生成输入串的最右侧符号。 LR 分析器的基本概念 LR 分析器依赖一个状态栈和一个输入缓冲区,通过状态转移表来指导分析过程

LR(Logistic Regression)算法详解
Logistic Regression本质上还是Linear Regression的一种,只是用了一个Logistic Function将线性回归的连续值映射到了 { 0 , 1 } \{0, 1\} {0,1}空间。因此Linear Regression只能对具有线性边界的分类问题有很好的预测效果,对于非线性的边界是无能为力的。至于下面这张很经典的大家常用的图,只是做了一个feature map
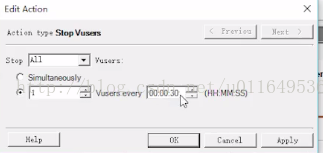
LR性能测试框架学习总结(二)--controller场景设计
分类: 手动测试场景 面向目标测试场景 手动测试场景设计: 初始化:同时初始化所有虚拟用户、每隔多长时间初始化几个虚拟用户、每个虚拟用户运行前都初始化 start vuser:立即一起开启所有虚拟用户,每隔多长时间几个虚拟用户开始执行动作 Duration:直到动作完成就结束、运行指定的时间 stop vuser:停止所有虚拟用户,每隔多长时间停止多少个虚拟

LR性能测试框架学习总结
性能目的:使用起来速度快,不崩,稳定 性能分类: 常规性能测试--响应时间、响应速度----正常工作,你的速度有多快 负载测试---持续加压,目的是找到崩溃的临界点,目的是用户使用时能不触碰到此临界点---不断增加工作量使工作饱和度不断增加,你什么时候撑不住了 压力测试--在一定饱和度内,会不会出错----在工作量比较大时,你工作会不会犯错 并发测试---多用户同时访问一个应用、模块、数
自下而上语法分析、自上而下语法分析和递归下降法、预测分析法、LL(1)和LR是什么关系
自下而上语法分析、自上而下语法分析、递归下降法、预测分析法、LL(1)和LR都是与语法分析(语法解析)相关的概念和技术。它们在编译原理中扮演着重要的角色,用于将源代码的字符流转换为语法树(或抽象语法树,AST),以便进一步的编译和优化。以下是这些概念之间的关系和各自的特点: 自上而下语法分析(Top-Down Parsing) 自上而下语法分析从开始符号开始,根据文法规则推导输入字符串。主要方

Logistic逻辑回归模型(LR)基础
逻辑回归(Logistic Regression, LR)模型其实仅在线性回归的基础上,套用了一个逻辑函数,但也就由于这个逻辑函数,使得逻辑回归模型成为了机器学习领域一颗耀眼的明星,更是计算广告学的核心。本文主要详述逻辑回归模型的基础,至于逻辑回归模型的优化、逻辑回归与计算广告学等,请关注后续文章。 1 逻辑回归模型 回归是一种极易理解的模型,就相当于y=f(x),表明自变量x与
编译原理:代替LR分析法的MP分析法
LR分析法由Knuth先生于1965年开发。LR分析法存在一个问题:当文法产生式变多,分析表变大之后,占用很多内存。为了接近自然语言编程,需要大量的文法产生式,有可能分析表过大,内存里放不下。 MP分析法,是multi-pass(多遍分析法)。 词法分析和语法分析仍然是分开的,语法分析按照“先乘除后加减”,分成多遍,即MP。 词法分析返回的不是经典《编译原理》中所说的符号串,而是简单的树。所
力扣:777. 在LR字符串中交换相邻字符
777. 在LR字符串中交换相邻字符 在一个由 'L' , 'R' 和 'X' 三个字符组成的字符串(例如"RXXLRXRXL")中进行移动操作。一次移动操作指用一个 "LX" 替换一个 "XL",或者用一个 "XR" 替换一个 "RX"。现给定起始字符串 start 和结束字符串 end,请编写代码,当且仅当存在一系列移动操作使得 start 可以转换成 end 时, 返回 True。
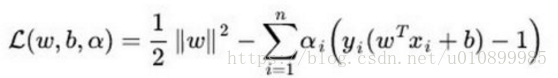
支持向量机SVM与逻辑斯谛回归LR区别
逻辑回归模型 逻辑回归模型是一种分类模型,由条件概率分布P(Y|X) 表示,形式为参数化的逻辑分布,这里,随机变量X取值为实数,随机变量Y取值为1或0。 在学习逻辑回归时大家总是将线性回归作比较,线性回归模型的输出一般是连续的, 在线性回归模型中每一个输入x,都有一个对应的y输出。模型的定义域和值域都可以是[-∞, +∞]。但是逻辑回归输入可以是连续的[-∞, +∞],输出却一般是离散的
LR的web_reg_save_param详解
运行脚本时,web_reg_save_param 函数将扫描所访问的后续 HTML 页。如果指 定左边界和/ 或右边界, VuGen 将搜索这些边界之间的文本。VuGen 找到文本 后,会将其分配给某个参数。 函数的语法如下所示: 下表列出可用的属性。注意,属性值字符串(例如 Search=all)不区分大小写。 NotFound 找不到边界并且生成了空字符串时的处理方法。默认值
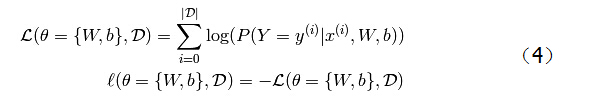
深度学习(DL)与卷积神经网络(CNN)学习笔记随笔-03-基于Python的LeNet之LR(转)
原地址可以查看更多信息 本文主要参考于:Classifying MNIST digits using Logistic Regression Python源代码(GitHub下载 CSDN免费下载) 0阶张量叫标量(scarlar);1阶张量叫向量(vector);2阶张量叫矩阵(matrix) 本文主要内容:如何用python中的theano包实现最基础的分类器–

用java开发编译器:构建LR跳转表
阅读博客的朋友可以到我的网易云课堂中,通过视频的方式查看代码的调试和执行过程: http://study.163.com/course/courseMain.htm?courseId=1002830012 如果大家运行上一节的代码,可以得到压缩后的LR有限状态机,以及节点间的跳转关系: ***begin to print a map row*** from state: State Nu
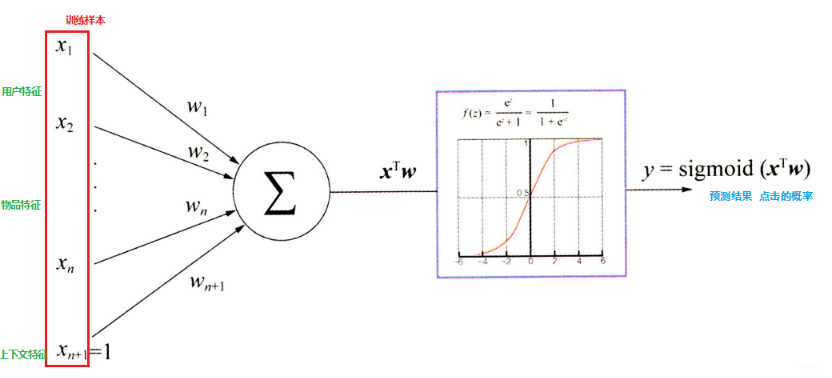
逻辑回归模型与GBDT+LR——特征工程模型化的开端
随着信息技术和互联网的发展, 我们已经步入了一个信息过载的时代,这个时代,无论是信息消费者还是信息生产者都遇到了很大的挑战: 信息消费者:如何从大量的信息中找到自己感兴趣的信息?信息生产者:如何让自己生产的信息脱颖而出, 受到广大用户的关注? 为了解决这个矛盾, 推荐系统应时而生, 并飞速前进,在用户和信息之间架起了一道桥梁,一方面帮助用户发现对自己有价值的信息, 一方面让信息能够展现在对它感
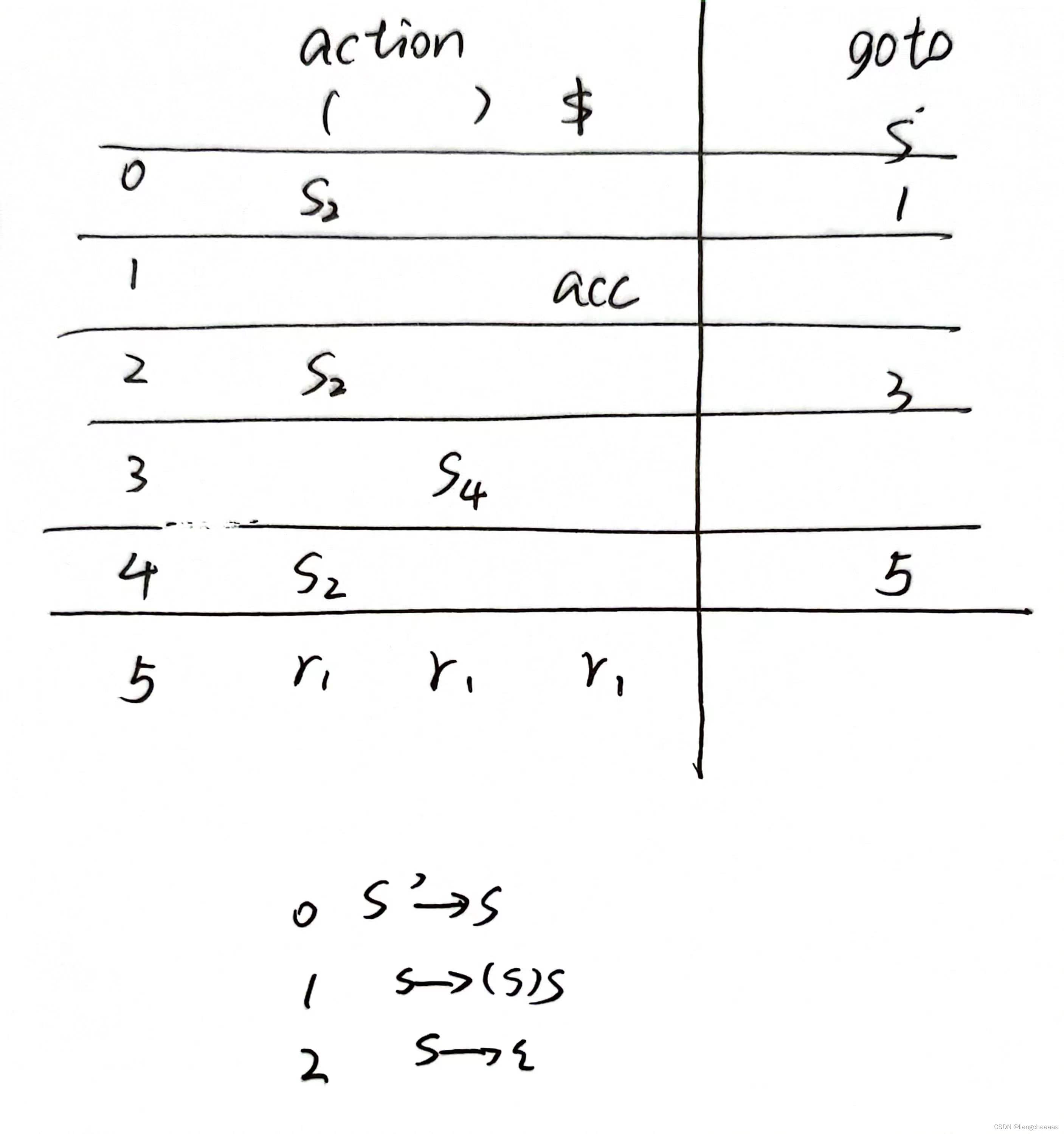
编译原理 LR(0)
讲解视频:编译原理LR(0)分析表(上)_哔哩哔哩_bilibili 【编译原理】LR(0)分析表分析输入串_哔哩哔哩_bilibili 拓广文法 已知G:S->(S)S | ε 拓广文法: S' -> S S -> (S)S S -> ε 写出所有项目 S' -> .S S' -> S. S -> .(S)S S -> (.S)S S -> (S.)S S -> (S).
LR为什么取log损失函数,又为什么在似然函数计算之后取对数
在学习和做项目的过程中,逐渐加深了对LR的理解。 其中最重要的一点就是为什么取-log函数为损失函数,损失函数的本质就是,如果我们预测对了,能够不惩罚,如果预测错误,会导致损失函数变得很大,也就是惩罚较大,而-log函数在【0,1】之间正好符合这一点,另外还有一点需要说明,LR是一种广义的线性回归模型,平方损失函数的话,对于Sigmoid函数求导计算,无法保证是凸函数,在优化的过程中,求得的解有
LR+GBDT的工作原理
简介 因为梯度提升树训练过于复杂,而逻辑回归过于简单,只能发现线性简单,而对于交互项和非线性关系没有辨识度。 于是用梯度提升树训练模型,基于树模型,就有了交叉和非线性,然后把叶子节点放到逻辑回归模型里,解决了逻辑回归算法的缺点。 简单来说,就是将梯度提升树的输出作为逻辑回归的输入,最终得到逻辑回归模型。 如梯度提升树中有三棵树, T 1 T_1 T1、 T 2 T_2 T2和 T 3 T
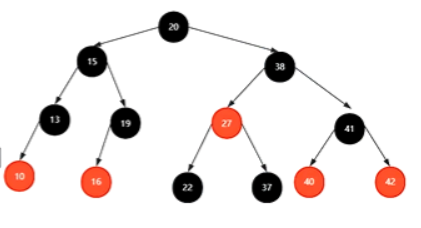
B树,红黑树,LR,RL
红黑树来源于多叉树–>234树4阶B树 红黑树:每个节点不是红色就是黑色,根节点一定是黑色,叶子节点是黑色的,一个红色节点的子节点一定是黑色的,从根节点到根节点都会经过相同数量的黑色节点,从根节点到任意节点经过的路径最长的路径不会超过最短路径的二倍 时间上O(logn),再者就是稳定 插入节点都是红色的
将事务插入到 Vuser 脚本(lr用户手册)
可以定义事务以度量服务器的性能。每个事务度量服务器响应指定 Vuser 请求所用的时间。这些请求可以是简单任务(如等待对单个查询的响应),也可以是复杂任务(如提交多个查询和生成报告)。要度量事务,需要插入 Vuser 函数以标记任务的开始和结束。在脚本内,可以标记的事务不受数量限制,每个事务的名称都不同。对于 LoadRunner 和优化模块,Controller 或控制台将度量执行每个事务所用
性能测试一般过程与LR性能测试过程
性能测试作为测试分类的一个大类,等同于系统测试中的功能测试、安全性测试和配置测试等,因此她的测试过程是对整个测试类型中测试过程的一个描述,因此包含了测试需要的确认目标,熟悉系统、获得需求等部分,因此性能能测试(performance testing)的测试一般过程如下: 1)制定目标和分析系统 2)获得需求 3)设计性能测试用例 4)通过协议模拟系统操作 5)设计场景运行测试用
LR参数化详解(朋友写的原创文章)
试验过程: 1、 使用loadrunner录制一个脚本; 2、 录制脚本内容为登录一个web网站,并下载网站的一个文件;(注本例无登录和退出操作) 3、 把所下载的文件设置参数化; 4、 对select next row和update value on进行两两组合,并设置不同用户数量(用户数量多余参数数量和等于参数数量)和迭代次数(1次迭代或多次迭代); 参数列表: 1、