本文主要是介绍【改进YOLOv8】车辆测距预警系统:融合空间和通道重建卷积SCConv改进YOLOv8,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义:
随着交通工具的普及和道路交通的不断增加,车辆安全问题日益凸显。特别是在高速公路等高速道路上,车辆之间的距离和速度差异较大,往往容易发生追尾事故。因此,开发一种准确可靠的车辆测距预警系统对于提高道路交通安全具有重要意义。
目前,YOLOv8(You Only Look Once)是一种常用的目标检测算法,它通过将图像分成网格,并在每个网格中预测目标的边界框和类别,从而实现实时目标检测。然而,YOLOv8在车辆测距预警系统中存在一些问题。首先,YOLOv8在处理小目标时存在较大的误差,这对于车辆测距预警系统来说是不可接受的。其次,YOLOv8在处理目标遮挡和复杂背景时也存在一定的困难,这可能导致误报或漏报。
为了解决上述问题,本研究提出了一种改进的YOLOv8车辆测距预警系统,即融合空间和通道重建卷积(Spatial and Channel Reconstructive Convolution,简称SCConv)。SCConv是一种新型的卷积操作,它能够在保持空间信息的同时,有效地提取目标的通道特征。通过引入SCConv,我们可以改善YOLOv8在小目标检测和目标遮挡方面的性能,从而提高车辆测距预警系统的准确性和可靠性。
本研究的意义主要体现在以下几个方面:
首先,通过改进YOLOv8车辆测距预警系统,可以提高道路交通安全性。准确可靠的车辆测距预警系统可以帮助驾驶员及时发现前方车辆的距离和速度差异,从而避免追尾事故的发生。这对于保障驾驶员和乘客的生命安全具有重要意义。
其次,本研究的结果可以为其他目标检测算法的改进提供借鉴。SCConv作为一种新型的卷积操作,可以在其他目标检测算法中进行应用。通过将SCConv引入其他算法,可以进一步提高目标检测的准确性和鲁棒性,从而推动计算机视觉领域的发展。
最后,本研究对于学术界的研究也具有一定的参考价值。通过对YOLOv8车辆测距预警系统的改进,可以深入研究目标检测算法的性能优化和改进方法。这对于推动计算机视觉领域的研究和发展具有重要意义。
综上所述,改进YOLOv8车辆测距预警系统是一项具有重要意义的研究。通过引入融合空间和通道重建卷积SCConv,可以提高车辆测距预警系统的准确性和可靠性,从而提高道路交通安全性。同时,本研究的结果也可以为其他目标检测算法的改进提供借鉴,对于学术界的研究也具有一定的参考价值。
2.图片演示



3.视频演示
【改进YOLOv8】车辆测距预警系统:融合空间和通道重建卷积SCConv改进YOLOv8_哔哩哔哩_bilibili
4.数据集的采集&标注和整理
图片的收集
首先,我们需要收集所需的图片。这可以通过不同的方式来实现,例如使用现有的公开数据集TrafficDatasets。

labelImg是一个图形化的图像注释工具,支持VOC和YOLO格式。以下是使用labelImg将图片标注为VOC格式的步骤:
(1)下载并安装labelImg。
(2)打开labelImg并选择“Open Dir”来选择你的图片目录。
(3)为你的目标对象设置标签名称。
(4)在图片上绘制矩形框,选择对应的标签。
(5)保存标注信息,这将在图片目录下生成一个与图片同名的XML文件。
(6)重复此过程,直到所有的图片都标注完毕。
由于YOLO使用的是txt格式的标注,我们需要将VOC格式转换为YOLO格式。可以使用各种转换工具或脚本来实现。
下面是一个简单的方法是使用Python脚本,该脚本读取XML文件,然后将其转换为YOLO所需的txt格式。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-import xml.etree.ElementTree as ET
import osclasses = [] # 初始化为空列表CURRENT_DIR = os.path.dirname(os.path.abspath(__file__))def convert(size, box):dw = 1. / size[0]dh = 1. / size[1]x = (box[0] + box[1]) / 2.0y = (box[2] + box[3]) / 2.0w = box[1] - box[0]h = box[3] - box[2]x = x * dww = w * dwy = y * dhh = h * dhreturn (x, y, w, h)def convert_annotation(image_id):in_file = open('./label_xml\%s.xml' % (image_id), encoding='UTF-8')out_file = open('./label_txt\%s.txt' % (image_id), 'w') # 生成txt格式文件tree = ET.parse(in_file)root = tree.getroot()size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)for obj in root.iter('object'):cls = obj.find('name').textif cls not in classes:classes.append(cls) # 如果类别不存在,添加到classes列表中cls_id = classes.index(cls)xmlbox = obj.find('bndbox')b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),float(xmlbox.find('ymax').text))bb = convert((w, h), b)out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')xml_path = os.path.join(CURRENT_DIR, './label_xml/')# xml list
img_xmls = os.listdir(xml_path)
for img_xml in img_xmls:label_name = img_xml.split('.')[0]print(label_name)convert_annotation(label_name)print("Classes:") # 打印最终的classes列表
print(classes) # 打印最终的classes列表整理数据文件夹结构
我们需要将数据集整理为以下结构:
-----data|-----train| |-----images| |-----labels||-----valid| |-----images| |-----labels||-----test|-----images|-----labels确保以下几点:
所有的训练图片都位于data/train/images目录下,相应的标注文件位于data/train/labels目录下。
所有的验证图片都位于data/valid/images目录下,相应的标注文件位于data/valid/labels目录下。
所有的测试图片都位于data/test/images目录下,相应的标注文件位于data/test/labels目录下。
这样的结构使得数据的管理和模型的训练、验证和测试变得非常方便。
模型训练
Epoch gpu_mem box obj cls labels img_size1/200 20.8G 0.01576 0.01955 0.007536 22 1280: 100%|██████████| 849/849 [14:42<00:00, 1.04s/it]Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:14<00:00, 2.87it/s]all 3395 17314 0.994 0.957 0.0957 0.0843Epoch gpu_mem box obj cls labels img_size2/200 20.8G 0.01578 0.01923 0.007006 22 1280: 100%|██████████| 849/849 [14:44<00:00, 1.04s/it]Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:12<00:00, 2.95it/s]all 3395 17314 0.996 0.956 0.0957 0.0845Epoch gpu_mem box obj cls labels img_size3/200 20.8G 0.01561 0.0191 0.006895 27 1280: 100%|██████████| 849/849 [10:56<00:00, 1.29it/s]Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|███████ | 187/213 [00:52<00:00, 4.04it/s]all 3395 17314 0.996 0.957 0.0957 0.0845
5.核心代码讲解
5.1 deep sort.py
import os
import shutilclass ImageEnhancer:def __init__(self, path):self.path = pathdef enhance_images(self):result = os.listdir(self.path)if not os.path.exists('./train'):os.mkdir('./train')if not os.path.exists('./train/1'):os.mkdir('./train/1')if not os.path.exists('./test'):os.mkdir('./test')if not os.path.exists('./test/1'):os.mkdir('./test/1')num = 0for i in result:num += 1if num % 3 == 0:shutil.copyfile(self.path + '/' + i, './train/1' + '/' + i)if num % 3 == 1:shutil.copyfile(self.path + '/' + i, './train/1' + '/' + i)if num % 3 == 2:shutil.copyfile(self.path + '/' + i, './test/1' + '/' + i)print('分类完成')这个程序文件的作用是将指定文件夹中的图片进行分类,并将其复制到不同的文件夹中。具体的操作如下:
- 导入所需的库:cv2、numpy、os、shutil。
- 定义一个变量
path,表示存放需要图像增强的图片的文件夹路径。 - 使用
os.listdir()函数读取文件夹内的文件,并将结果保存在result变量中。 - 判断是否存在
./train文件夹,如果不存在则创建。 - 判断是否存在
./train/1文件夹,如果不存在则创建。 - 判断是否存在
./test文件夹,如果不存在则创建。 - 判断是否存在
./test/1文件夹,如果不存在则创建。 - 定义一个变量
num,初始化为0,用于计数。 - 遍历
result中的每个文件:num自增1。- 如果
num除以3的余数为0,则将当前文件复制到./train/1文件夹中。 - 如果
num除以3的余数为1,则将当前文件复制到./train/1文件夹中。 - 如果
num除以3的余数为2,则将当前文件复制到./test/1文件夹中。
- 打印输出"分类完成"。
总体来说,这个程序文件的功能是将指定文件夹中的图片按照一定规则进行分类,并将其复制到不同的文件夹中。
5.3 predict.py
封装为类后的代码如下:
from ultralytics.engine.predictor import BasePredictor
from ultralytics.engine.results import Results
from ultralytics.utils import opsclass DetectionPredictor(BasePredictor):def postprocess(self, preds, img, orig_imgs):preds = ops.non_max_suppression(preds,self.args.conf,self.args.iou,agnostic=self.args.agnostic_nms,max_det=self.args.max_det,classes=self.args.classes)if not isinstance(orig_imgs, list):orig_imgs = ops.convert_torch2numpy_batch(orig_imgs)results = []for i, pred in enumerate(preds):orig_img = orig_imgs[i]pred[:, :4] = ops.scale_boxes(img.shape[2:], pred[:, :4], orig_img.shape)img_path = self.batch[0][i]results.append(Results(orig_img, path=img_path, names=self.model.names, boxes=pred))return results
这是一个名为predict.py的程序文件,它是一个基于检测模型进行预测的类DetectionPredictor的定义。该类继承自BasePredictor类,用于进行基于检测模型的预测。
该文件使用了Ultralytics YOLO库,使用AGPL-3.0许可证。
该文件中的DetectionPredictor类具有postprocess方法,用于对预测结果进行后处理,并返回Results对象的列表。在后处理过程中,该方法使用了ops.non_max_suppression函数对预测结果进行非最大值抑制,使用了ops.scale_boxes函数对边界框进行缩放。最后,该方法将原始图像、图像路径、类别名称和边界框信息封装成Results对象,并将其添加到结果列表中。
该文件还包含了一个示例代码,展示了如何使用DetectionPredictor类进行预测。
总之,该文件定义了一个用于基于检测模型进行预测的类,并提供了相应的后处理方法。
5.4 train.py
# Ultralytics YOLO 🚀, AGPL-3.0 licensefrom copy import copyimport numpy as npfrom ultralytics.data import build_dataloader, build_yolo_dataset
from ultralytics.engine.trainer import BaseTrainer
from ultralytics.models import yolo
from ultralytics.nn.tasks import DetectionModel
from ultralytics.utils import LOGGER, RANK
from ultralytics.utils.torch_utils import de_parallel, torch_distributed_zero_firstclass DetectionTrainer(BaseTrainer):def build_dataset(self, img_path, mode='train', batch=None):gs = max(int(de_parallel(self.model).stride.max() if self.model else 0), 32)return build_yolo_dataset(self.args, img_path, batch, self.data, mode=mode, rect=mode == 'val', stride=gs)def get_dataloader(self, dataset_path, batch_size=16, rank=0, mode='train'):assert mode in ['train', 'val']with torch_distributed_zero_first(rank):dataset = self.build_dataset(dataset_path, mode, batch_size)shuffle = mode == 'train'if getattr(dataset, 'rect', False) and shuffle:LOGGER.warning("WARNING ⚠️ 'rect=True' is incompatible with DataLoader shuffle, setting shuffle=False")shuffle = Falseworkers = 0return build_dataloader(dataset, batch_size, workers, shuffle, rank)def preprocess_batch(self, batch):batch['img'] = batch['img'].to(self.device, non_blocking=True).float() / 255return batchdef set_model_attributes(self):self.model.nc = self.data['nc']self.model.names = self.data['names']self.model.args = self.argsdef get_model(self, cfg=None, weights=None, verbose=True):model = DetectionModel(cfg, nc=self.data['nc'], verbose=verbose and RANK == -1)if weights:model.load(weights)return modeldef get_validator(self):self.loss_names = 'box_loss', 'cls_loss', 'dfl_loss'return yolo.detect.DetectionValidator(self.test_loader, save_dir=self.save_dir, args=copy(self.args))def label_loss_items(self, loss_items=None, prefix='train'):keys = [f'{prefix}/{x}' for x in self.loss_names]if loss_items is not None:loss_items = [round(float(x), 5) for x in loss_items]return dict(zip(keys, loss_items))else:return keysdef progress_string(self):return ('\n' + '%11s' *(4 + len(self.loss_names))) % ('Epoch', 'GPU_mem', *self.loss_names, 'Instances', 'Size')def plot_training_samples(self, batch, ni):plot_images(images=batch['img'],batch_idx=batch['batch_idx'],cls=batch['cls'].squeeze(-1),bboxes=batch['bboxes'],paths=batch['im_file'],fname=self.save_dir / f'train_batch{ni}.jpg',on_plot=self.on_plot)def plot_metrics(self):plot_results(file=self.csv, on_plot=self.on_plot)def plot_training_labels(self):boxes = np.concatenate([lb['bboxes'] for lb in self.train_loader.dataset.labels], 0)cls = np.concatenate([lb['cls'] for lb in self.train_loader.dataset.labels], 0)plot_labels(boxes, cls.squeeze(), names=self.data['names'], save_dir=self.save_dir, on_plot=self.on_plot)
这是一个用于训练目标检测模型的程序文件。它使用了Ultralytics YOLO库,实现了一个名为DetectionTrainer的类,继承自BaseTrainer类。该类提供了构建数据集、构建数据加载器、预处理批次、设置模型属性等功能。
程序文件中的主要函数包括:
- build_dataset: 构建YOLO数据集。
- get_dataloader: 构建并返回数据加载器。
- preprocess_batch: 对图像批次进行预处理,包括缩放和转换为浮点数。
- set_model_attributes: 设置模型的属性,包括类别数量、类别名称和超参数。
- get_model: 返回一个YOLO检测模型。
- get_validator: 返回一个用于模型验证的DetectionValidator。
- label_loss_items: 返回一个带有标签的训练损失字典。
- progress_string: 返回训练进度的格式化字符串。
- plot_training_samples: 绘制训练样本及其注释。
- plot_metrics: 绘制来自CSV文件的指标。
- plot_training_labels: 创建一个带有标签的训练模型的绘图。
在程序的主函数中,创建了一个DetectionTrainer对象,并调用其train方法进行训练。
5.6 backbone\fasternet.py
import torch
import torch.nn as nn
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from functools import partial
from typing import List
from torch import Tensor
import copy
import os
import numpy as npclass Partial_conv3(nn.Module):def __init__(self, dim, n_div, forward):super().__init__()self.dim_conv3 = dim // n_divself.dim_untouched = dim - self.dim_conv3self.partial_conv3 = nn.Conv2d(self.dim_conv3, self.dim_conv3, 3, 1, 1, bias=False)if forward == 'slicing':self.forward = self.forward_slicingelif forward == 'split_cat':self.forward = self.forward_split_catelse:raise NotImplementedErrordef forward_slicing(self, x: Tensor) -> Tensor:# only for inferencex = x.clone() # !!! Keep the original input intact for the residual connection laterx[:, :self.dim_conv3, :, :] = self.partial_conv3(x[:, :self.dim_conv3, :, :])return xdef forward_split_cat(self, x: Tensor) -> Tensor:# for training/inferencex1, x2 = torch.split(x, [self.dim_conv3, self.dim_untouched], dim=1)x1 = self.partial_conv3(x1)x = torch.cat((x1, x2), 1)return xclass MLPBlock(nn.Module):def __init__(self,dim,n_div,mlp_ratio,drop_path,layer_scale_init_value,act_layer,norm_layer,pconv_fw_type):super().__init__()self.dim = dimself.mlp_ratio = mlp_ratioself.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()self.n_div = n_divmlp_hidden_dim = int(dim * mlp_ratio)mlp_layer: List[nn.Module] = [nn.Conv2d(dim, mlp_hidden_dim, 1, bias=False),norm_layer(mlp_hidden_dim),act_layer(),nn.Conv2d(mlp_hidden_dim, dim, 1, bias=False)]self.mlp = nn.Sequential(*mlp_layer)self.spatial_mixing = Partial_conv3(dim,n_div,pconv_fw_type)if layer_scale_init_value > 0:self.layer_scale = nn.Parameter(layer_scale_init_value * torch.ones((dim)), requires_grad=True)self.forward = self.forward_layer_scaleelse:self.forward = self.forwarddef forward(self, x: Tensor) -> Tensor:shortcut = xx = self.spatial_mixing(x)x = shortcut + self.drop_path(self.mlp(x))return xdef forward_layer_scale(self, x: Tensor) -> Tensor:shortcut = xx = self.spatial_mixing(x)x = shortcut + self.drop_path(self.layer_scale.unsqueeze(-1).unsqueeze(-1) * self.mlp(x))return xclass BasicStage(nn.Module):def __init__(self,dim,depth,n_div,mlp_ratio,drop_path,layer_scale_init_value,norm_layer,act_layer,pconv_fw_type):super().__init__()blocks_list = [MLPBlock(dim=dim,n_div=n_div,mlp_ratio=mlp_ratio,drop_path=drop_path[i],layer_scale_init_value=layer_scale_init_value,norm_layer=norm_layer,act_layer=act_layer,pconv_fw_type=pconv_fw_type)for i in range(depth)]self.blocks = nn.Sequential(*blocks_list)def forward(self, x: Tensor) -> Tensor:x = self.blocks(x)return xclass PatchEmbed(nn.Module):def __init__(self, patch_size, patch_stride, in_chans, embed_dim, norm_layer):super().__init__()self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_stride, bias=False)if norm_layer is not None:self.norm = norm_layer(embed_dim)else:self.norm = nn.Identity()def forward(self, x: Tensor) -> Tensor:x = self.norm(self.proj(x))return xclass PatchMerging(nn.Module):def __init__(self, patch_size2, patch_stride2, dim, norm_layer):super().__init__()self.reduction = nn.Conv2d(dim, 2 * dim, kernel_size=patch_size2, stride=patch_stride2, bias=False)if norm_layer is not None:self.norm = norm_layer(2 * dim)else:self.norm = nn.Identity()def forward(self, x: Tensor) -> Tensor:x = self.norm(self.reduction(x))return xclass FasterNet(nn.Module):def __init__(self,in_chans=3,num_classes=1000,embed_dim=96,depths=(1, 2, 8, 2),mlp_ratio=2.,n_div=4,patch_size=4,patch_stride=4,patch_size2=2, # for subsequent layerspatch_stride2=2,patch_norm=True,feature_dim=1280,drop_path_rate=0.1,layer_scale_init_value=0,norm_layer='BN',act_layer='RELU',init_cfg=None,pretrained=None,pconv_fw_type='split_cat',**kwargs):super().__init__()if norm_layer == 'BN':norm_layer = nn.BatchNorm2delse:raise NotImplementedErrorif act_layer == 'GELU':act_layer = nn.GELUelif act_layer == 'RELU':act_layer = partial(nn.ReLU, inplace=True)else:raise NotImplementedErrorself.num_stages = len(depths)self.embed_dim = embed_dim
该程序文件是一个名为fasternet.py的Python程序文件,用于定义了一个名为FasterNet的神经网络模型。该模型是基于PyTorch框架实现的,用于图像分类任务。
该程序文件包含了以下主要部分:
- 导入所需的库和模块。
- 定义了一些辅助函数和类,如
Partial_conv3、MLPBlock、BasicStage、PatchEmbed、PatchMerging等。 - 定义了
FasterNet类,该类继承自nn.Module,用于构建FasterNet模型。 - 定义了一些辅助函数,如
update_weight、fasternet_t0、fasternet_t1等,用于加载预训练权重和创建不同配置的FasterNet模型。 - 在
__main__函数中,示例化了一个FasterNet模型,并打印了模型的输出通道数和每个阶段的输出尺寸。
总体来说,该程序文件实现了一个FasterNet模型,并提供了加载预训练权重和创建不同配置模型的函数。
6.系统整体结构
根据以上分析,整体来看,这个工程是一个视觉项目,旨在改进YOLOv8车辆测距预警系统,通过融合空间和通道重建卷积SCConv来提升YOLOv8的性能。该工程包含了多个程序文件,每个文件都有不同的功能,如数据处理、模型训练、模型导出、预测等。
下面是每个文件的功能整理:
| 文件路径 | 功能 |
|---|---|
| deep sort.py | 实现Deep SORT算法,用于目标跟踪和ID关联 |
| export.py | 将YOLOv8 PyTorch模型导出为其他格式的工具 |
| predict.py | 基于检测模型进行预测的类和函数 |
| train.py | 训练目标检测模型的类和函数 |
| ui.py | 车辆检测和车距检测的类和函数 |
| backbone\fasternet.py | 定义了FasterNet神经网络模型 |
| backbone\lsknet.py | 定义了LSKNet神经网络模型 |
| backbone\repvit.py | 定义了RepVIT神经网络模型 |
| backbone\revcol.py | 定义了RevCol神经网络模型 |
| backbone\SwinTransformer.py | 定义了Swin Transformer神经网络模型 |
| backbone\VanillaNet.py | 定义了VanillaNet神经网络模型 |
| extra_modules\orepa.py | 实现了OREPA模块 |
| extra_modules\rep_block.py | 实现了REP Block模块 |
| extra_modules\RFAConv.py | 实现了RFAConv模块 |
| extra_modules_init_.py | 额外模块的初始化文件 |
| extra_modules\ops_dcnv3\setup.py | DCNv3模块的安装配置文件 |
| extra_modules\ops_dcnv3\test.py | DCNv3模块的测试文件 |
| extra_modules\ops_dcnv3\functions\dcnv3_func.py | DCNv3模块的函数实现 |
| extra_modules\ops_dcnv3\functions_init_.py | DCNv3模块函数的初始化文件 |
| extra_modules\ops_dcnv3\modules\dcnv3.py | DCNv3模块的模型实现 |
| extra_modules\ops_dcnv3\modules_init_.py | DCNv3模块的初始化文件 |
| models\common.py | 包含一些通用的模型函数和类 |
| models\experimental.py | 包含一些实验性的模型函数和类 |
| models\tf.py | 包含一些TensorFlow模型函数和类 |
| models\yolo.py | 包含YOLO模型的定义和相关函数 |
| models_init_.py | 模型的初始化文件 |
| utils\activations.py | 包含一些激活函数的定义 |
| utils\augmentations.py | 包含一些数据增强的函数和类 |
| utils\autoanchor.py | 包含自动锚框生成的函数和类 |
| utils\autobatch.py | 包含自动批次大小调整的函数和类 |
| utils\callbacks.py | 包含一些回调函数的定义 |
| utils\datasets.py | 包含数据集加载和处理的函数和类 |
| utils\downloads.py | 包含一些下载和解压缩数据集的函数 |
| utils\general.py | 包含一些通用的辅助函数 |
| utils\loss.py | 包含一些损失函数的定义 |
| utils\metrics.py | 包含一些评估指标的定义 |
| utils\plots.py | 包含一些绘图函数的定义 |
| utils\torch_utils.py | 包含一些PyTorch相关的辅助函数 |
| utils_init_.py | 工具函数的初始化文件 |
| utils\aws\resume.py | AWS上的模型恢复函数 |
| utils\aws_init_.py | AWS工具函数的初始化文件 |
| utils\flask_rest_api\example_request.py | Flask REST API的示例请求 |
| utils\flask_rest_api\restapi.py | Flask REST API的实现 |
| utils\loggers_init_.py | 日志记录器的初始化文件 |
| utils\loggers\wandb\log_dataset.py | 使用WandB记录数据集的函数 |
| utils\loggers\wandb\sweep.py | 使用WandB进行超参数搜索的函数 |
| utils\loggers\wandb\wandb_utils.py | 使用WandB的辅助函数 |
| utils\loggers\wandb_init_.py | WandB日志记录器的初始化文件 |
以上是对每个文件的功能进行了简要的概括和整理。
7.YOLOv8简介
YOLOv8 尚未发表论文,因此我们无法直接了解其创建过程中进行的直接研究方法和消融研究。话虽如此,我们分析了有关模型的存储库和可用信息,以开始记录 YOLOv8 中的新功能。
如果您想自己查看代码,请查看YOLOv8 存储库并查看此代码差异以了解一些研究是如何完成的。
在这里,我们提供了有影响力的模型更新的快速总结,然后我们将查看模型的评估,这不言自明。
GitHub 用户 RangeKing 制作的下图显示了网络架构的详细可视化。

在这里插入图片描述
在这里插入图片描述
YOLOv8 架构,GitHub 用户 RangeKing 制作的可视化
无锚检测
YOLOv8 是一个无锚模型。这意味着它直接预测对象的中心而不是已知锚框的偏移量。
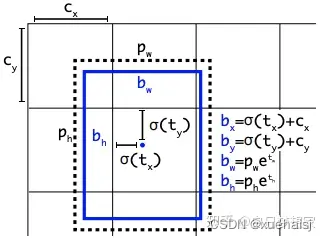
YOLO中anchor box的可视化
锚框是早期 YOLO 模型中众所周知的棘手部分,因为它们可能代表目标基准框的分布,而不是自定义数据集的分布。
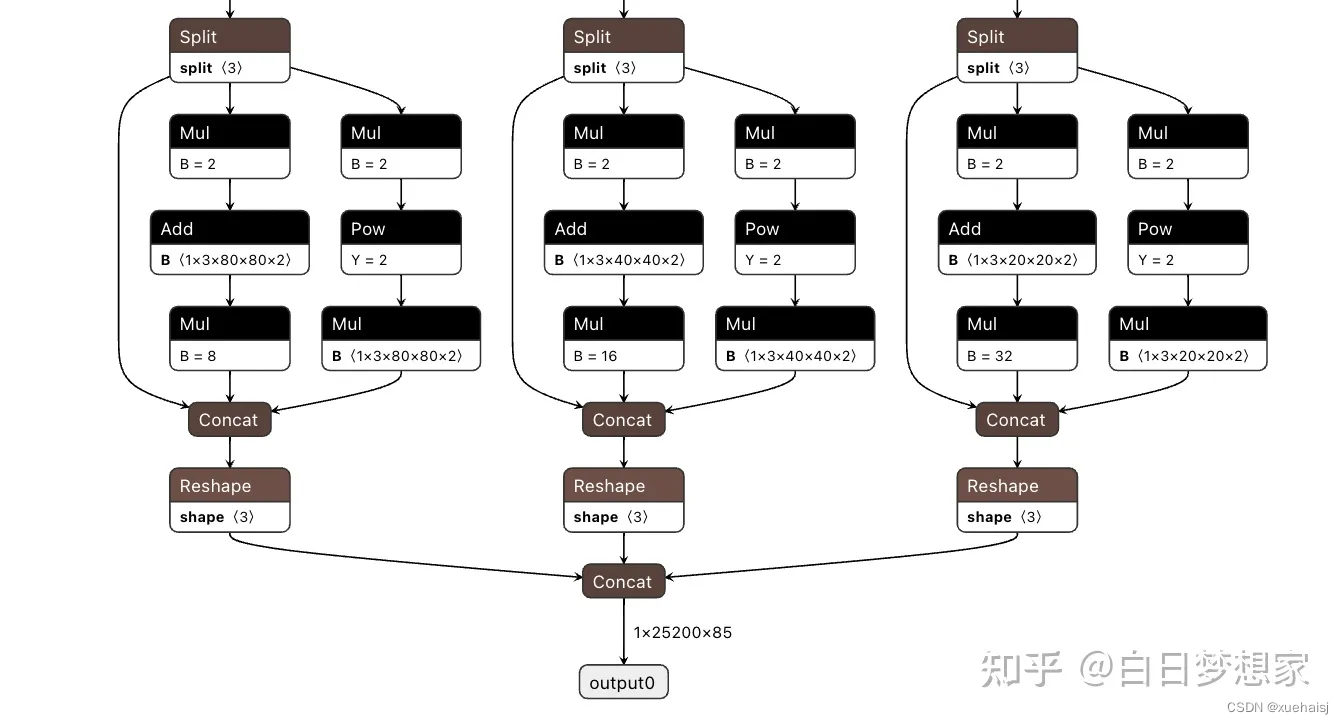
YOLOv8 的检测头,在netron.app中可视化
Anchor free 检测减少了框预测的数量,从而加速了非最大抑制 (NMS),这是一个复杂的后处理步骤,在推理后筛选候选检测。
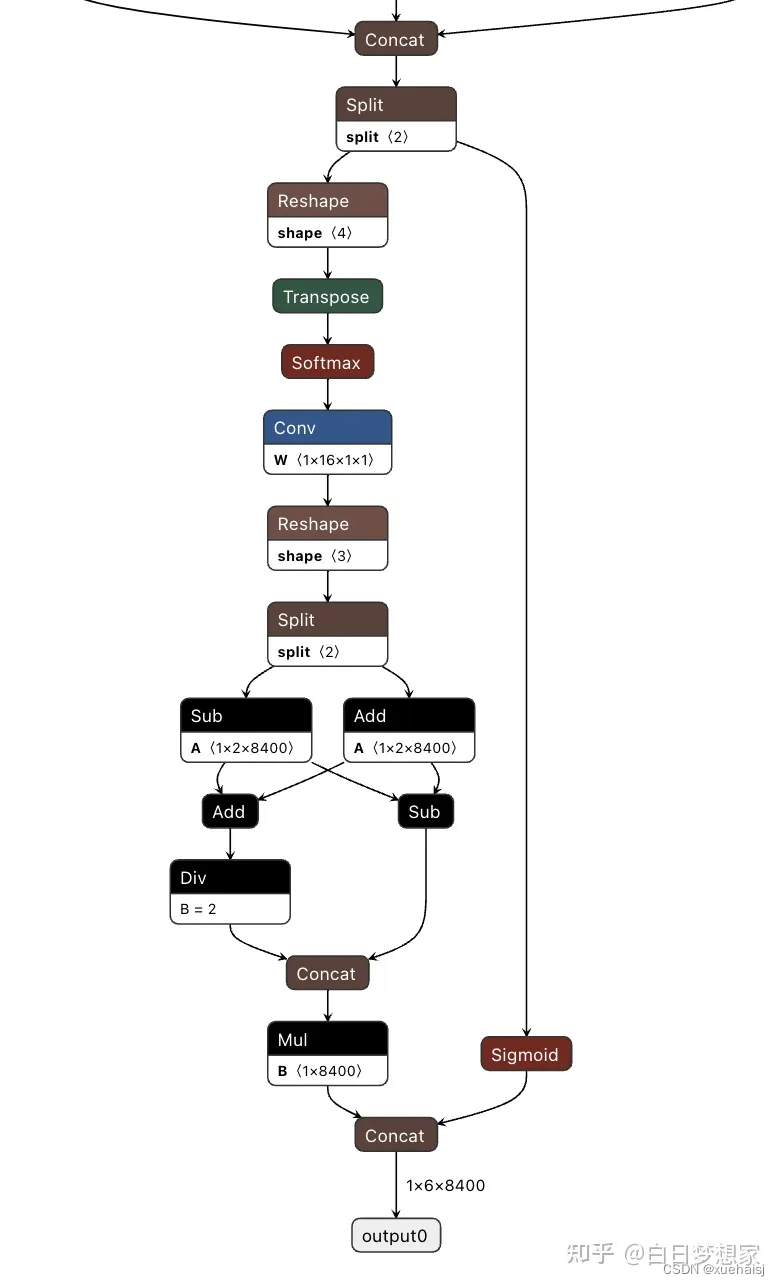
YOLOv8 的检测头,在netron.app中可视化
新的卷积
stem 的第一个6x6conv 被替换为 a 3x3,主要构建块被更改,并且C2f替换了C3。该模块总结如下图,其中“f”是特征数,“e”是扩展率,CBS是由a Conv、a BatchNorm、a组成的block SiLU。
在中, (两个具有剩余连接的 3x3C2f的奇特名称)的所有输出都被连接起来。而在仅使用最后一个输出。BottleneckconvsC3``Bottleneck
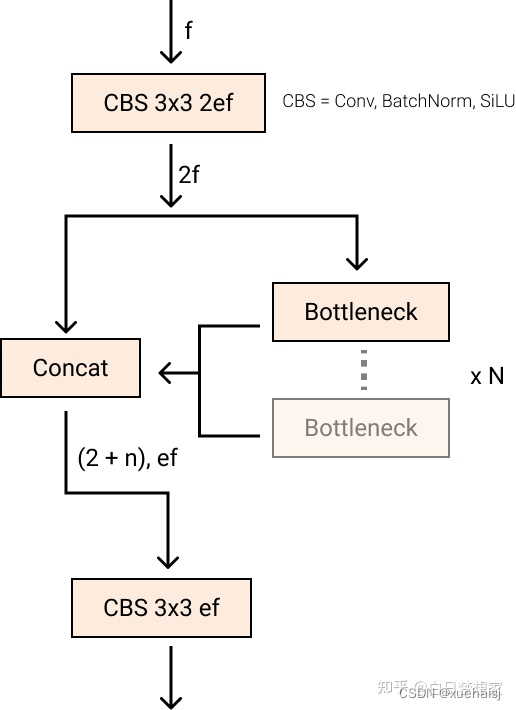
新的 YOLOv8C2f模块
这Bottleneck与 YOLOv5 中的相同,但第一个 conv 的内核大小从更改1x1为3x3. 从这些信息中,我们可以看到 YOLOv8 开始恢复到 2015 年定义的 ResNet 块。
在颈部,特征直接连接而不强制使用相同的通道尺寸。这减少了参数数量和张量的整体大小。
8.空间和通道重建卷积SCConv
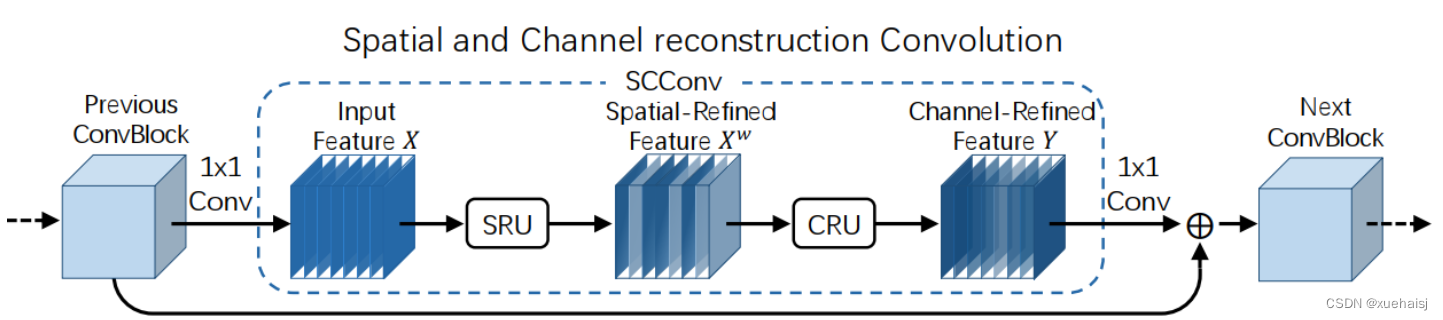
参考该博客提出的一种高效的卷积模块,称为SCConv (spatial and channel reconstruction convolution),以减少冗余计算并促进代表性特征的学习。提出的SCConv由空间重构单元(SRU)和信道重构单元(CRU)两个单元组成。
(1)SRU根据权重分离冗余特征并进行重构,以抑制空间维度上的冗余,增强特征的表征。
(2)CRU采用分裂变换和融合策略来减少信道维度的冗余以及计算成本和存储。
(3)SCConv是一种即插即用的架构单元,可直接用于替代各种卷积神经网络中的标准卷积。实验结果表明,scconvo嵌入模型能够通过减少冗余特征来获得更好的性能,并且显著降低了复杂度和计算成本。
SCConv如图所示,它由两个单元组成,空间重建单元(SRU)和通道重建单元(CRU),以顺序的方式放置。具体而言,对于瓶颈残差块中的中间输入特征X,首先通过SRU运算获得空间细化特征Xw,然后利用CRU运算获得信道细化特征Y。SCConv模块充分利用了特征之间的空间冗余和通道冗余,可以无缝集成到任何CNN架构中,以减少中间特征映射之间的冗余并增强CNN的特征表示。
SRU单元用于空间冗余
为了利用特征的空间冗余,引入了空间重构单元(SRU),如图2所示,它利用了分离和重构操作。
分离操作 的目的是将信息丰富的特征图与空间内容对应的信息较少的特征图分离开来。我们利用组归一化(GN)层中的比例因子来评估不同特征图的信息内容。具体来说,给定一个中间特征映射X∈R N×C×H×W,首先通过减去平均值µ并除以标准差σ来标准化输入特征X,如下所示:
其中µ和σ是X的均值和标准差,ε是为了除法稳定性而加入的一个小的正常数,γ和β是可训练的仿射变换。
GN层中的可训练参数\gamma \in R^{C}用于测量每个批次和通道的空间像素方差。更丰富的空间信息反映了空间像素的更多变化,从而导致更大的γ。归一化相关权重W_{\gamma} \in R^{C}由下面公式2得到,表示不同特征映射的重要性。
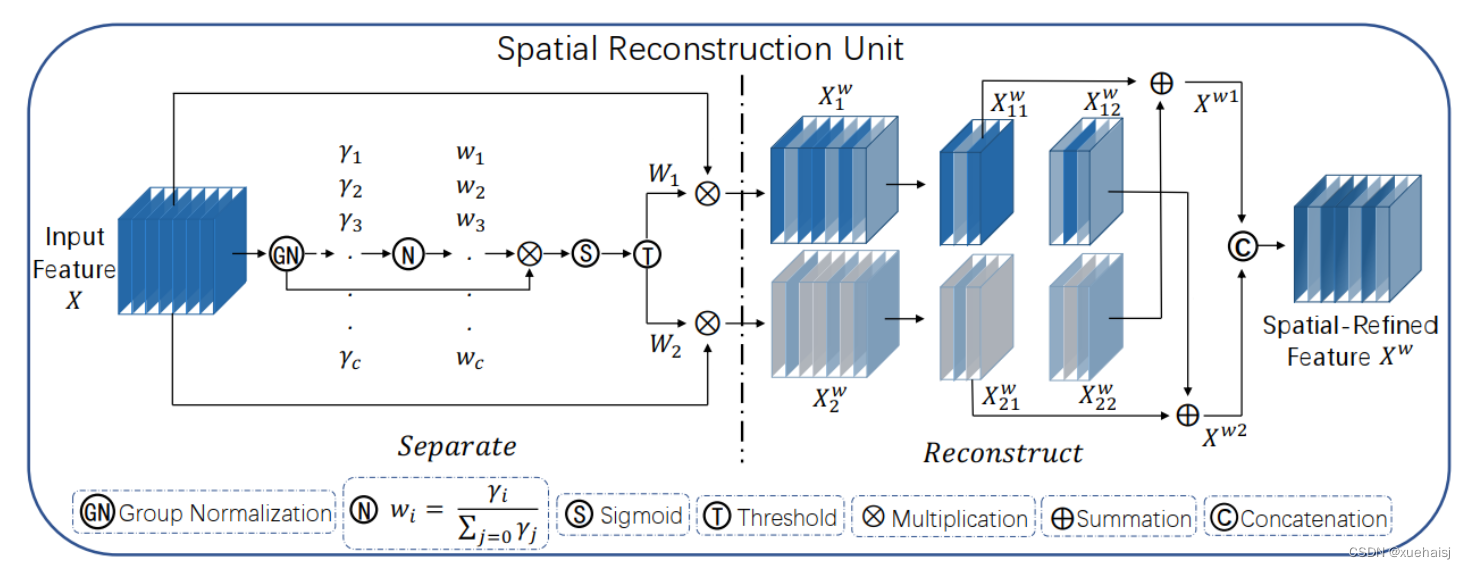
然后将经Wγ重新加权的特征映射的权值通过sigmoid函数映射到(0,1)范围,并通过阈值进行门控。我们将阈值以上的权重设置为1,得到信息权重W1,将其设置为0,得到非信息权重W2(实验中阈值设置为0.5)。获取W的整个过程可以用公式表示。
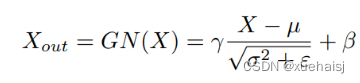
最后将输入特征X分别乘以W1和W2,得到两个加权特征:信息量较大的特征X_{1}^{\omega }和信息量较小的特征X_{2}^{\omega }。这样就成功地将输入特征分为两部分:X_{1}^{\omega }具有信息量和表达性的空间内容,而X_{2}^{\omega }几乎没有信息,被认为是冗余的。
重构操作 将信息丰富的特征与信息较少的特征相加,生成信息更丰富的特征,从而节省空间空间。采用交叉重构运算,将加权后的两个不同的信息特征充分结合起来,加强它们之间的信息流。然后将交叉重构的特征X{\omega1}和X{\omega2}进行拼接,得到空间精细特征映射X^{\omega}。从后过程表示如下:
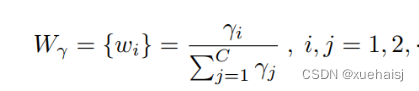
其中⊗是逐元素的乘法,⊕是逐元素的求和,∪是串联。将SRU应用于中间输入特征X后,不仅将信息特征与信息较少的特征分离,而且对其进行重构,增强代表性特征,抑制空间维度上的冗余特征。然而,空间精细特征映射X^{\omega}在通道维度上仍然是冗余的。
CRU单元用于通道冗余
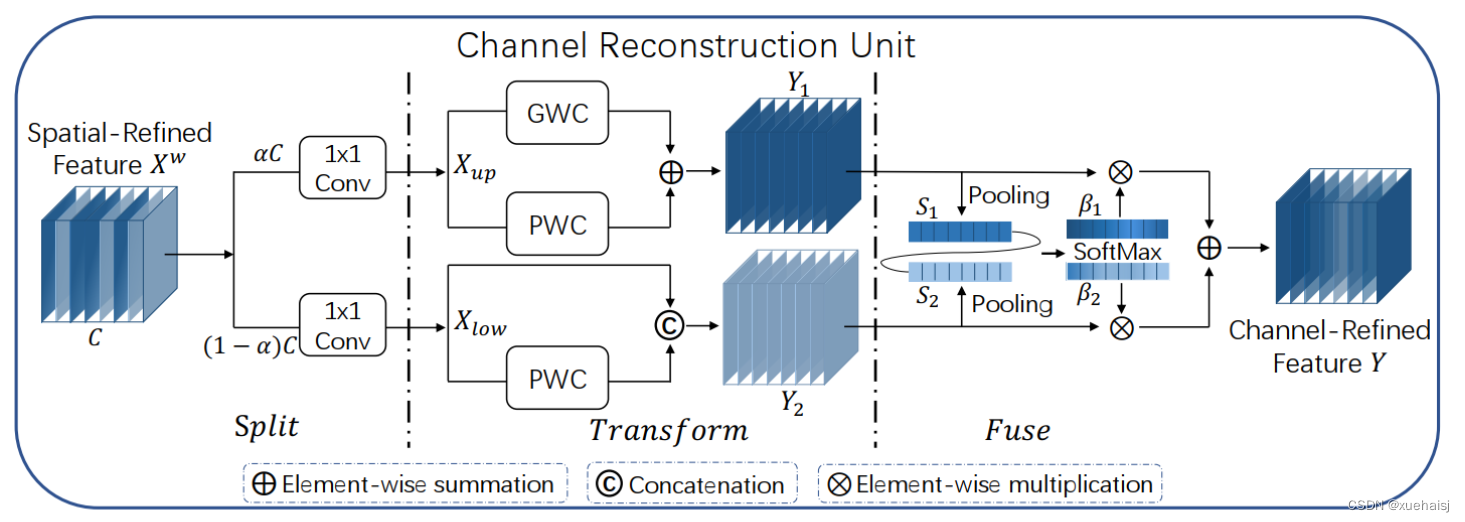
分割 操作将输入的空间细化特征X^{\omega}分割成两个部分,一部分通道数是\alpha C,另一部分通道数是(1-\alpha) C,随后对两组特征的通道数使用1 * 1卷积核进行压缩,分别得到X_{up}和X_{low}。
转换 操作将输入的X_{up}作为“富特征提取”的输入,分别进行GWC和PWC,然后相加得到输出Y1,将输入X_{low}作为“富特征提取”的补充,进行PWC,得到的记过和原来的输入取并集得到Y2。
融合 操作使用简化的SKNet方法来自适应合并Y1和Y2。具体说是首先使用全局平均池化将全局空间信息和通道统计信息结合起来,得到经过池化的S1和S2。然后对S1和S2做Softmax得到特征权重向量\beta _{1}和\beta _{2},最后使用特征权重向量得到输出Y = \beta {1}*Y{1} + \beta {2}*Y{2},Y即为通道提炼的特征。
9.系统整合
下图完整源码&数据集&环境部署视频教程&自定义UI界面

参考博客《【改进YOLOv8】车辆测距预警系统:融合空间和通道重建卷积SCConv改进YOLOv8》
10.参考文献
[1]金辉,李昊天.基于驾驶风格的前撞预警系统报警策略[J].汽车工程.2021,(3).DOI:10.19562/j.chinasae.qcgc.2021.03.014 .
[2]唐敏,王东强,曾鑫钰.汽车碰撞预警主动安全预测方法[J].计算机科学.2020,(4).DOI:10.11896/jsjkx.190700137 .
[3]张三川,叶建明,师艳娟.基于毫米波雷达的汽车前防撞预警系统设计[J].郑州大学学报(工学版).2020,(6).DOI:10.13705/j.issn.1671-6833.2020.06.006 .
[4]杨炜,刘佳俊,张志威,等.结合前车驾驶意图辨识的汽车主动防撞预警系统[J].中国科技论文.2020,(2).
[5]张文会,孙舒蕊,苏永民.双车道公路超车安全距离模型[J].交通运输系统工程与信息.2019,(2).DOI:10.16097/j.cnki.1009-6744.2019.02.026 .
[6]李寿涛,王蕊,徐靖淳,等.一种基于模型预测复合控制的车辆避碰控制方法[J].吉林大学学报(工学版).2021,(2).DOI:10.13229/j.cnki.jdxbgxb20191201 .
[7]李梦,韩帮国.双参数车辆行驶偏离提醒与预警策略研究[J].电子测量与仪器学报.2020,(10).DOI:10.13382/j.jemi.B2002990 .
这篇关于【改进YOLOv8】车辆测距预警系统:融合空间和通道重建卷积SCConv改进YOLOv8的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!