本文主要是介绍MD-MTSP:开普勒优化算法KOA求解多仓库多旅行商问题MATLAB(可更改数据集,旅行商的数量和起点),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、开普勒优化算法KOA
开普勒优化算法(Kepler optimization algorithm,KOA)由Mohamed Abdel-Basset等人于2023年提出。
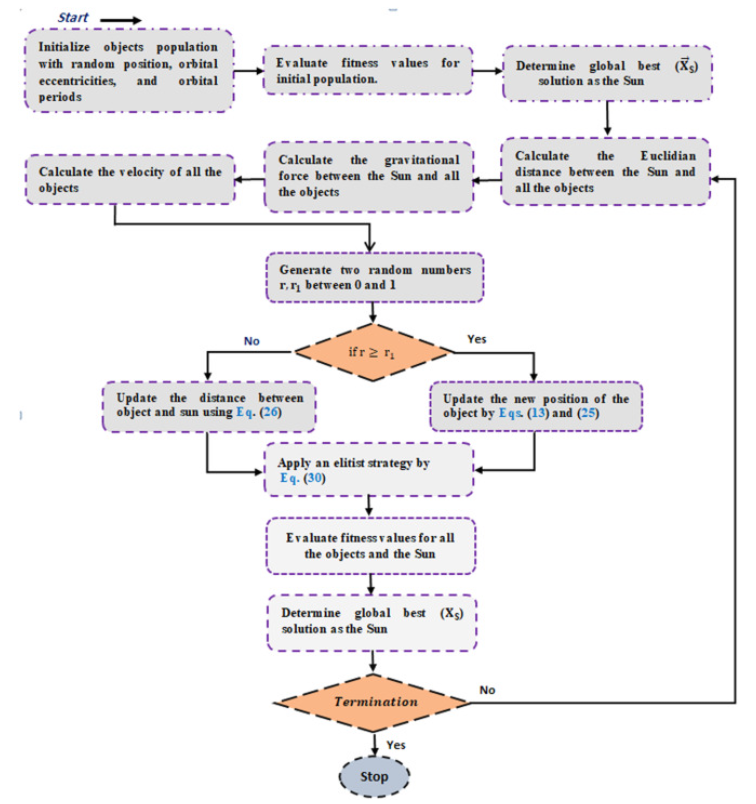
参考文献:
[1]Mohamed Abdel-Basset, Reda Mohamed, Shaimaa A. Abdel Azeem, Mohammed Jameel, Mohamed Abouhawwash, Kepler optimization algorithm: A new metaheuristic algorithm inspired by Kepler’s laws of planetary motion, Knowledge-Based Systems, 2023. DOI: Redirecting
二、多仓库多旅行商问题MD-MTSP
多旅行商问题(Multiple Traveling Salesman Problem, MTSP)是著名的旅行商问题(Traveling Salesman Problem, TSP)的延伸,多旅行商问题定义为:给定一个𝑛座城市的城市集合,指定𝑚个推销员,每一位推销员从起点城市出发访问一定数量的城市,最后回到终点城市,要求除起点和终点城市以外,每一座城市都必须至少被一位推销员访问,并且只能访问一次,需要求解出满足上述要求并且代价最小的分配方案,其中的代价通常用总路程长度来代替,当然也可以是时间、费用等。多仓库多旅行商问题是其中一种多旅行商问题。
多旅行商问题(Multiple Traveling Salesman Problem, MTSP):单仓库多旅行商问题及多仓库多旅行商问题(含动态视频)_IT猿手的博客-CSDN博客
多仓库多旅行商问题(Multi-Depot Multiple Travelling Salesman Problem, MD-MTSP):𝑚个推销员从𝑚座不同的城市出发,访问其中一定数量的城市并且每座城市只能被某一个推销员访问一次,最后回到各自出发的城市,这种问题模型被称之为MD-MTSP。
三、开普勒优化算法KOA求解MD-MTSP
本文选取国际通用的TSP实例库TSPLIB中的测试集bayg29作为测试例子,数据集可以自行修改。
3.1部分代码(可更改起点及旅行商个数)
close all
clear
clc
global data StartPoint Tnum
%数据集参考文献 REINELT G.TSPLIB-a traveling salesman problem[J].ORSA Journal on Computing,1991,3(4):267-384.
% 导入TSP数据集 bayg29
load('data.txt')
StartPoint=[1 5 15 16 20];%起点城市的序号(可以修改) 必须由小到大排列 (建议:2到6个旅行商)
Tnum=length(StartPoint);%旅行商个数
Dim=size(data,1)-Tnum;%维度
lb=-100;%下界
ub=100;%上界
fobj=@Fun;%计算总距离
SearchAgents_no=100; % 种群大小(可以修改)
Max_iteration=3000; % 最大迭代次数(可以修改)
[fMin,bestX,curve]=KOA(SearchAgents_no,Max_iteration,lb,ub,Dim,fobj);
3.2部分结果
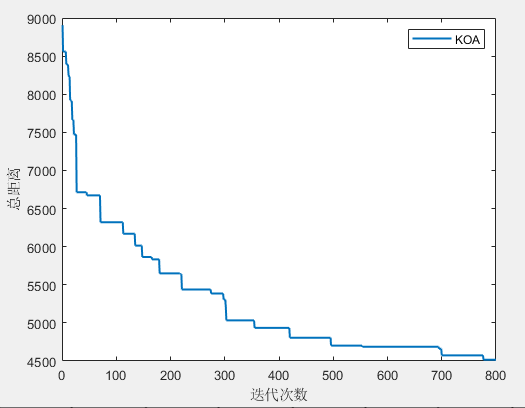
(1)4个旅行商
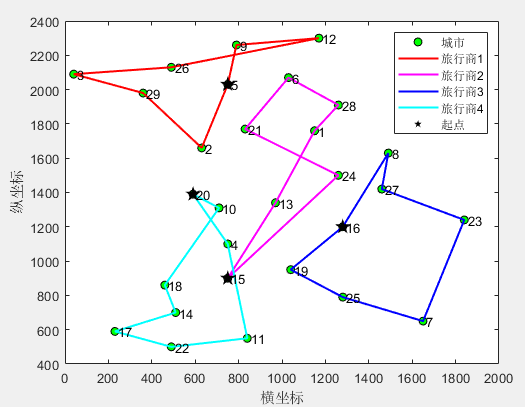

第1个旅行商的路径:5->2->29->3->26->12->9->5
第1个旅行商的总路径长度:1156.287162
第2个旅行商的路径:15->13->1->28->6->21->24->15
第2个旅行商的总路径长度:1253.714481
第3个旅行商的路径:16->8->27->23->7->25->19->16
第3个旅行商的总路径长度:1093.069074
第4个旅行商的路径:20->10->18->14->17->22->11->4->20
第4个旅行商的总路径长度:1012.620363
所有旅行商的总路径长度:4515.691080
(2)5个旅行商
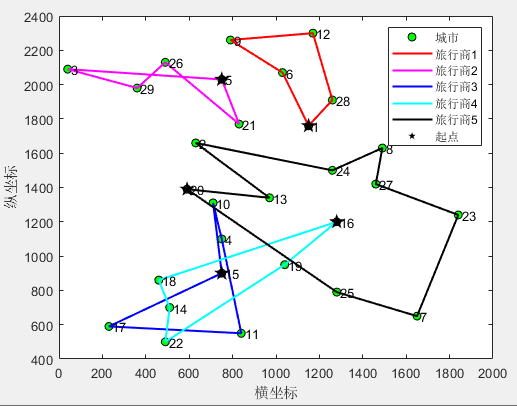
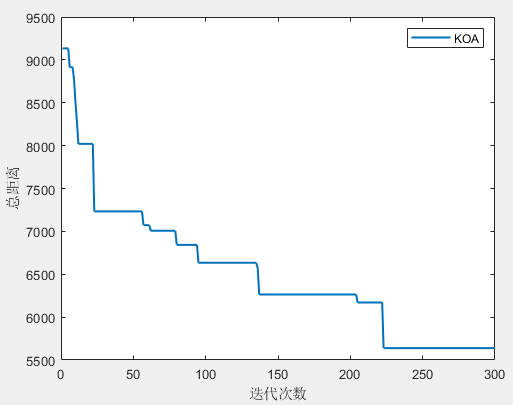
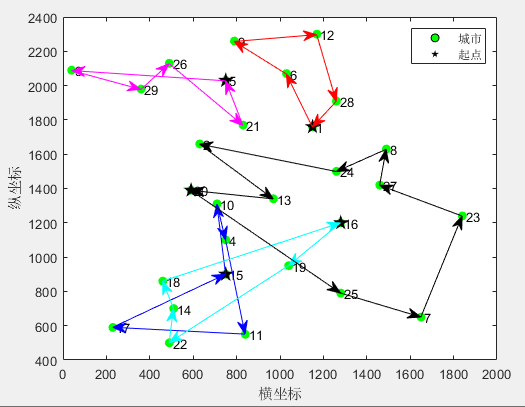
第1个旅行商的路径:1->6->9->12->28->1
第1个旅行商的总路径长度:738.241153
第2个旅行商的路径:5->3->29->26->21->5
第2个旅行商的总路径长度:990.353472
第3个旅行商的路径:15->10->4->11->17->15
第3个旅行商的总路径长度:1125.255527
第4个旅行商的路径:16->19->22->14->18->16
第4个旅行商的总路径长度:1217.209924
第5个旅行商的路径:20->25->7->23->27->8->24->2->13->20
第5个旅行商的总路径长度:1567.099231
所有旅行商的总路径长度:5638.159307
四、完整Matlab代码
这篇关于MD-MTSP:开普勒优化算法KOA求解多仓库多旅行商问题MATLAB(可更改数据集,旅行商的数量和起点)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




