本文主要是介绍Mistral AI 推出高质量的稀疏专家混合AI人工智能模型——SMoE,有望超越ChatGPT3.5,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Mistral AI(“Mistral AI”是一家由前DeepMind和Meta Platforms(META.US)的研究人员组建的新公司。)继续履行为开发者社区提供最佳开放模型的使命。他们发布了 Mixtral 8x7B,这是一个高质量的稀疏专家混合模型(SMoE),拥有开放权重,该模型的性能在大多数基准测试中优于 Llama 2 70B,推理速度提高了6倍。
Mixtral 是一个稀疏的专家混合网络,可以处理 32k 令牌的上下文,并且能够处理英语、法语、意大利语、德语和西班牙语。它在代码生成方面表现出强大的性能,还可以通过微调成为指令跟踪模型。Mixtral 的稀疏架构使其在控制成本和延迟的同时增加了模型的参数数量,从而提高了性能。与 Llama 2相比,Mixtral 更真实,并且在偏见方面表现较少。
此外,Mixtral 可以优雅地指定禁止某些输出,以满足需要严格审核的应用程序的要求。为了让社区能够使用完全开源的堆栈运行 Mixtral,他们已向 vLLM 项目提交了更改。最后,他们感谢 CoreWeave 和 Scaleway 团队在模型训练中的技术支持。
Mixtral 具有以下功能:
- 上下文处理能力:它似乎可以轻松地处理长达32,000个令牌的上下文,这表明它具有处理大量文本信息的能力。
- 多语言支持:该模型支持多种语言,包括英语、法语、意大利语、德语和西班牙语。这使得它更加灵活,适用于不同的语境和用户群。
- 代码生成性能:模型在代码生成方面表现出强大的性能。这可能意味着它能够生成高质量的源代码或者在与代码相关的任务上表现出色。
- 微调能力:该模型可以进行微调,使其适应特定的任务,比如指令跟踪模型。这增加了模型的灵活性,使其可以在不同领域取得更好的性能。
- MT-Bench性能:在MT-Bench上获得8.3分重写一次。这可能指的是模型在机器翻译任务上的性能评分。
通过稀疏架构推动开放模型的前沿:
Mixtral 是一个稀疏的专家混合网络。它是一个纯解码器模型,其中前馈块从一组8个不同的参数组中进行选择。在每一层,对于每个令牌,路由器网络选择其中的两个组(“专家”)来处理令牌并相加地组合它们的输出。
该技术增加了模型的参数数量,同时控制了成本和延迟,因为该模型仅使用每个令牌总参数集的一小部分。具体来说,Mixtral 共有46.7B 个参数,但每个代币仅使用12.9B 个参数。因此,它以与12.9B 模型相同的速度和相同的成本处理输入并生成输出。
Mixtral 根据从开放网络提取的数据进行了预训练——同时训练专家和路由器。
表现方面:
研发团队将 Mixtral 与 Llama 2系列和 GPT3.5基础模型进行比较。 Mixtral 在大多数基准测试中均匹配或优于 Llama 2 70B 以及 GPT3.5。

在下图中,研发团队衡量了质量与推理预算的权衡。与 Llama 2型号相比,Mistral 7B 和 Mixtral 8x7B 属于高效型号系列。

下表给出了上图的详细结果。

幻觉和偏见。为了识别可能的缺陷,通过微调/偏好建模来纠正,研发团队在 TruthfulQA/BBQ/BOLD 上测量基本模型的性能。

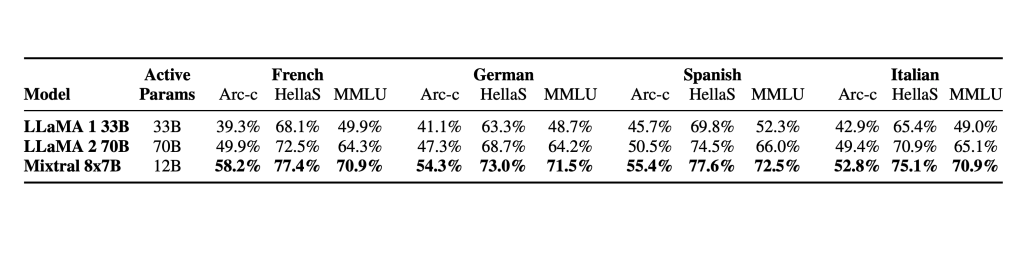
与 Llama 2相比,Mixtral 更真实(在 TruthfulQA 基准上为73.9%vs 50.2%),并且在 BBQ 基准上呈现出更少的偏差。总体而言,Mixtral 在 BOLD 上比 Llama 2显示出更积极的情绪,每个维度内的差异相似。语言方面: Mixtral 8x7B 精通法语、德语、西班牙语、意大利语和英语。
指导模型:
研发团队与 Mixtral 8x7B 一起发布了 Mixtral 8x7B Instruct。该模型已通过监督微调和直接偏好优化 (DPO) 进行优化,以仔细遵循指令。在MT-Bench上,它达到了8.30的分数,使其成为最好的开源模型,性能可与GPT3.5相媲美。
使用开源部署堆栈部署 Mixtral:
为了使社区能够使用完全开源的堆栈运行 Mixtral,我们已提交对 vLLM 项目的更改,该项目集成了 Megablocks CUDA 内核以实现高效推理。Skypilot 允许在云中的任何实例上部署 vLLM 端点。
这篇关于Mistral AI 推出高质量的稀疏专家混合AI人工智能模型——SMoE,有望超越ChatGPT3.5的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








