本文主要是介绍每天读一篇论文1--ANCIENT CHINESE WORD SEGMENTATION AND PART-OF-SPEECH TAGGING USING DISTANT SUPERVISIO,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要:
we propose a novel augmentation method of ancient Chinese WSG and POS tagging data using distant supervision over parallel corpus.我们提出了一种基于平行语料远程监督的古汉语WSG和词性标注数据扩充方法。
we take advantage of the memorization effects of deep neural networks and a small amount of annotated data to get a model with much knowledge and a little noise, and then we use this model to relabel the ancient Chinese sentences in parallel corpus.我们利用深度神经网络的记忆效应和少量的标注数据得到一个具有较多知识和少量噪声的模型,然后利用该模型对平行语料中的古汉语句子进行重打标号标注。
Experiments show that the model trained over the relabeled data outperforms the model trained over the data generated from distant supervision and the annotated data.实验表明,在重标注数据上训练的模型优于在远程监督生成的数据和标注数据上训练的模型。
two fundamental lexical analysis problems:
- Word segmentation (WSG) 分词
- part-of-speech (POS) tagging 词性标注
reasons:
- the rareness of labeled ancient Chinese corpus
- the huge difficulty of manual annotation
In low-resource scenario, distant supervision can provide ample but inaccurately labeled samples at low cost. Although annotation projection is effective in data augmentation, it has several problems including errors and omissions in tagging the low-resource languages
在低资源场景下,远程监督可以以较低的成本提供充足但不准确的标记样本。尽管标注投影在数据增强方面是有效的,但它在标注低资源语言时存在错误和遗漏等问题
Inspired by the memorization effects of deep neural networks (DNNs), which tend to fit clean data firstly and then fit noisy data gradually,we use the large data obtained from word alignment and the small annotated data to get a model with much knowledge and a little noise. Then we use the model to relabel thelarge data to reduce its errors and omissions. 受深度神经网络( Deep Neural Networks,DNNs )先拟合干净数据再逐步拟合噪声数据的记忆效应的启发,我们利用单词对齐得到的大数据和标注的小数据得到一个具有较多知识和少量噪声的模型。然后我们将模型运用到重打标号中大数据以减少其错误和遗漏。
INTRODUCTION:
we propose a novel data augmentation of ancient Chinese WSG and POS tagging completed in three steps. First, we use Chinese NLP tool to perform WSG and POS tagging on modern Chinese sentences to get sentences with word boundaries and POS tags. Then, we project the word boundaries and POS tags from modern Chinese to ancient Chinese. After that, we train the SIKU-Roberta2 over the large weakly labeled WSG and POS tagging data obtained from distant supervision to get the first stage model. We continue to train the first stage model over the small manually annotated WSG and POS tagging data to get the second stage model. At last, we use the second stage model to relabel the large weakly labeled data generated from distant supervision.我们提出了一种新颖的古汉语词义消歧和词性标注的数据增强方法,分三步完成。首先,我们使用中文NLP工具对现代汉语句子进行WSG和词性标注,得到带有词边界和词性标注的句子。然后,我们对现代汉语到古代汉语的词边界和词性标签进行了投射。之后,我们在远程监督获取的大型弱标注WSG和词性标注数据上训练SIKU - Roberta2得到第一阶段模型。我们继续在手工标注的小型WSG和词性标注数据上训练第一阶段模型,得到第二阶段模型。最后,我们使用第二阶段模型对远程监督产生的大量弱标注数据进行重打标号。
main contributions: 解决了古汉语词义消歧和词性标注中数据稀缺的问题
- We introduce distant supervision in ancient Chinese WSG and POS tagging.在古汉语词性标注和词性标注中引入远程监督
- We use a parallel corpus to generate large ancient Chinese WSG and POS tagging data using distant supervision.使用一个平行语料库,通过远程监督生成大型古汉语词义标注和词性标注数据
- We propose a novel method of denoising and completing the labels of the large weakly labeled data generated from distant supervision by relabeling it.提出了一种新的方法对远程监督产生的大量弱标注数据进行去噪并通过重标注完成标注
- Extensive experiments demonstrate the effectiveness of the method of distant supervision and relabeling.通过实验验证了远程监督和重标记方法的有效性
METHOD:
1、use a POS tagging set with 22 tags3, including verb(v), noun(n), adjective(a), person(nr), etc., and a WSG tag set {B, M, E, S}, where ‘B’, ‘M’, ‘E’ represent the beginning, middle and end of a word respectively, and ‘S’ indicates a word only with one character.
we treat the ancient Chinese WSG and POS tagging as one sequence labeling task using a hybrid tag set, which contains 88 tags.
2、Our model consists of a backbone, SIKU-Roberta2, one linear layer and one Conditional Random Fields (CRF) layer for the joint WSG and POS tagging sequence labeling.
我们的模型由一个主干、SIKU - Roberta2、一个线性层和一个条件随机场( Conditional Random Fields,CRF ) 层组成,用于联合WSG和词性标注序列标注。
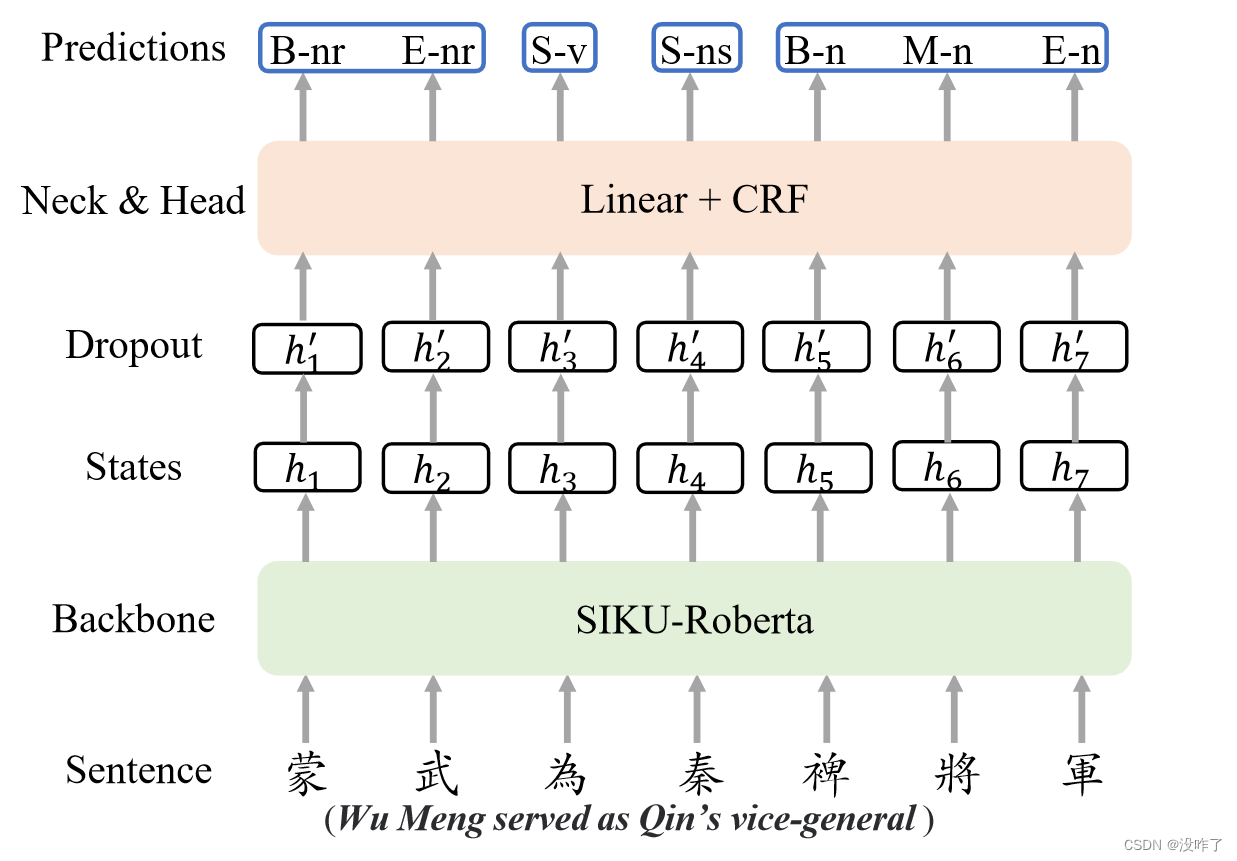
3、we use LTP to perform WSG and POS tagging on the modern Chinese to get sentences with word boundaries and POS tags, and then divide the ancient Chinese sentences into single characters.利用LTP对现代汉语进行WSG和词性标注,得到带有词边界和词性标注的句子,然后将古汉语句子切分为单字。
4、After processing the parallel corpus, we set modern Chinese as source language and ancient Chinese as target language. Then we use GIZA++ to implement word alignment on the parallel corpus, using IBM model 4, an unsupervised generative model, which can find possible pairs of aligned words and calculate their alignment probabilities.经过对平行语料的处理,我们将现代汉语设为源语言,古代汉语设为目标语言。然后我们使用GIZA + +在平行语料上实现词对齐,使用IBM model 4这个无监督的生成式模型,可以找到可能的对齐词对并计算其对齐概率。
5、For each ancient Chinese character, the POS tag of it is obtained from the dictionary based on the POS tag of its aligned modern Chinese word, if it is paired with at least one modern Chinese word, we take the modern Chinese word with the highest alignment probability as its alignment object; if it is not paired with any modern Chinese word, we take it as a single character word and tag it as null value. After that, for adjacent ancient Chinese characters, we combine ones aligned with one modern Chinese word into one word.对于每个古文字,它的POS标签是根据其对齐的现代汉语词的POS标签从词典中获得的,如果它至少与一个现代汉语词配对,我们将对齐概率最高的现代汉语词作为其对齐对象;如果没有与任何现代汉语词配对,我们将其作为单字词,并标记为空值。之后,对于相邻的古文字,我们将与一个现代汉语词对齐的字合并为一个词。
6、Denoising and Completing by Relabeling(1)Training over Large Projected Data(2)Training over Small Annotated Data(3)Training over Large Relabeled Data
CONCLUSION:
In this paper, we propose a method of augmentation of ancient Chinese WSG and POS tagging data using distant supervision. Besides, we use the method of relabeling to reduce the noise introduced by distant supervision. Experiments show the effectiveness of distant supervision and relabeling.
这篇关于每天读一篇论文1--ANCIENT CHINESE WORD SEGMENTATION AND PART-OF-SPEECH TAGGING USING DISTANT SUPERVISIO的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




