本文主要是介绍ERA5逐时、逐日、逐月气象数据的手动下载与Python代码批量下载方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文介绍在ERA5气象数据的官方网站中,手动下载、Python代码自动批量下载逐小时、逐日与逐月的ERA5气象数据各类产品的快捷方法。
ERA5(fifth generation ECMWF atmospheric reanalysis of the global climate)是由欧洲中期天气预报中心(European Centre for Medium-Range Weather Forecasts,ECMWF)开发和维护的一种全球范围内的高分辨率大气再分析数据集,提供了多种气象和气候变量的连续、一致和高质量的数据。ERA5基于全球观测数据、数值模型和物理参数化方案,通过数据同化和数值模拟的技术,对过去数十年(1940年至今)的天气状况进行再构建和模拟,从而生成了高时空分辨率的大气和地表变量数据。ERA5提供了广泛的气象和气候变量,包括温度、湿度、风速、降水、云量、地表辐射、地表温度等。这些数据以固定的时间间隔(逐小时或逐月)和空间分辨率(从数公里到数十公里)提供,可以用于气候研究、天气分析、气候模型验证、环境监测等众多应用领域。
我们可以通过ERA5的官方网站,或者在谷歌地球引擎等平台中,下载这一气象数据。由于在谷歌地球引擎中下载这一数据相对而言比较麻烦,而且速度也并不算友好,我们这里就主要介绍一下基于其官方网站,通过手动下载、Python代码下载等2种方式,下载不同ERA5数据产品的方法。
首先,需要明确,我们一般常用的ERA5数据产品包括ERA5(https://cds.climate.copernicus.eu/cdsapp#!/dataset/reanalysis-era5-single-levels?tab=overview)和ERA5-Land(https://cds.climate.copernicus.eu/cdsapp#!/dataset/reanalysis-era5-land?tab=overview)等2种;其中,前者ERA5包含全球全部区域,而后者ERA5-Land仅包含全球的陆地区域,但是后者的空间分辨率(最高是0.1 °)要高于前者(最高位0.25 °)。其次,在ERA5的官方网站,无论是上述的ERA5数据,还是ERA5-Land数据,我们通过手动下载或者代码下载的方式,都只能直接下载到逐小时或逐月的气象数据;如果需要逐日的数据,大家可以在其官方网站提供的逐日统计数据计算工具(https://cds.climate.copernicus.eu/cdsapp#!/software/app-c3s-daily-era5-statistics?tab=app)中加以自动计算后手动下载,或者是在GEE中下载,再或者就是先下载逐小时的数据,然后自行撰写代码批量计算逐日或者其他时间分辨率的数据。当然,也还有一种用Python代码批量下载逐日数据的方法,但是那个方法的速度受到网络情况影响,我发现还不如我手动下载来得快,所以这里就没有介绍;之后如果用到这个代码了,就再和大家介绍一下。
0 准备工作
需要注意,只要不是选择用上述逐日统计数据计算工具来下载数据,那么无论我们选择手动下载数据,还是用Python代码批量下载数据,都需要进行本部分的操作。
首先,我们找到需要下载的数据首页,如下图所示。
其次,如果我们没有登陆的话,需要在上图右上角所示的位置登录或者注册一下账号。如下图所示,我这里就新注册一个账号。
完成注册后,需要在我们注册时填写的邮箱中激活一下账号,如下图所示。

随后,登录账号即可;如下图所示。
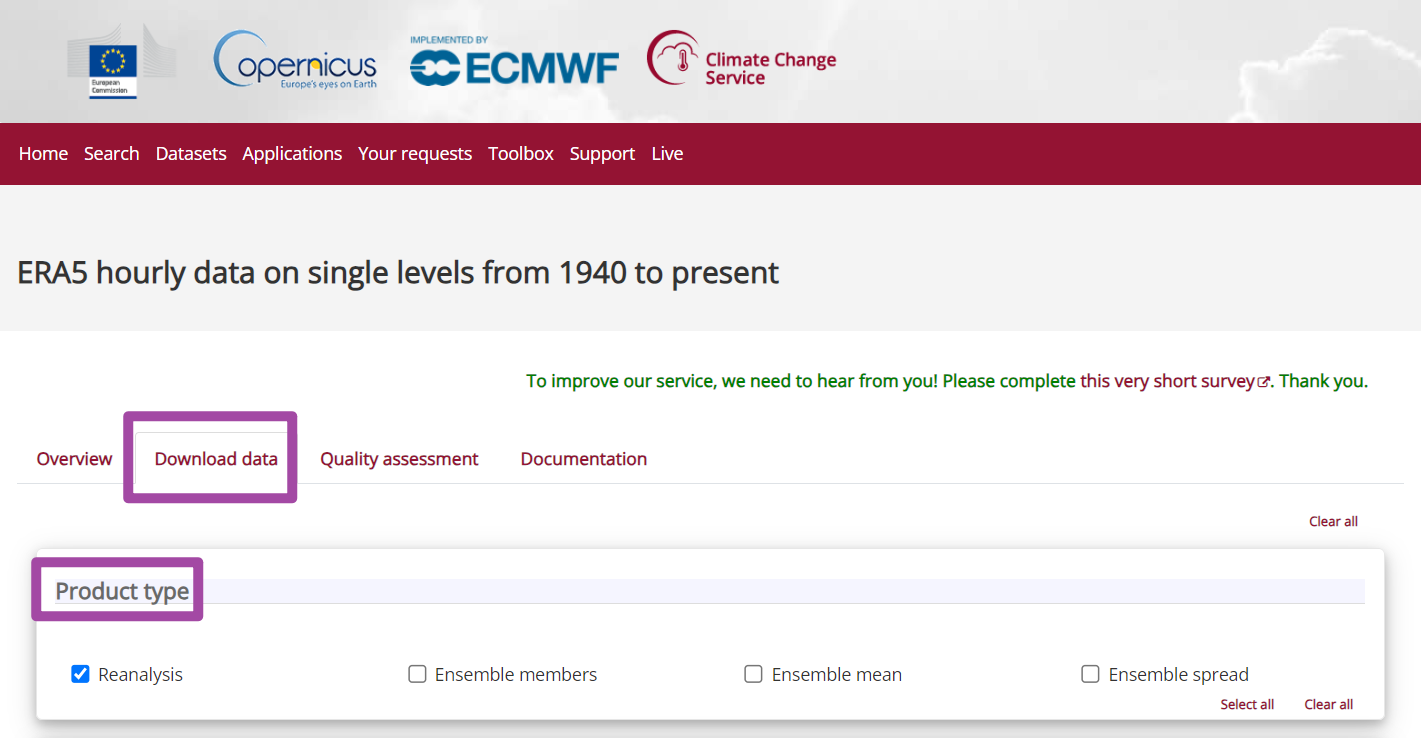
接下来,我们回到刚刚的数据首页中,选择“Download data”选项;如下图所示。随后,选择当前数据产品对应的产品类型,一般情况下,我们选择第一个,也就是“Reanalysis”选项就可以。
随后,选择我们需要的气象数据指标;可以在“Popular”这一栏选择用户常用的热门指标,也可以自己依据需要在下面的类别中搜索。如下图所示。
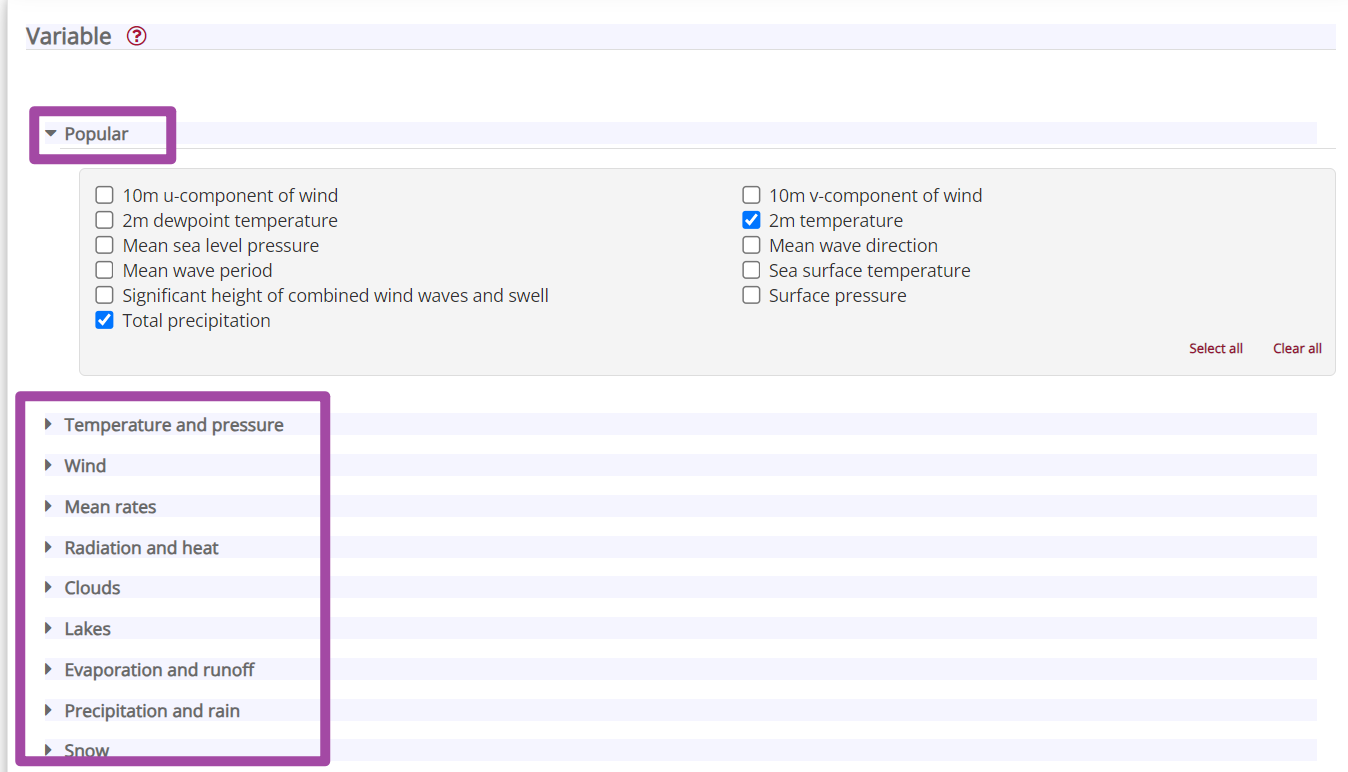
接下来,选择我们需要的年份和日期、时刻。这里需要注意,对于不同的ERA5产品,其能一次性下载的数量也是不同的;如下图所示,我这张图下载的是ERA5数据,它就可以一次性选择多年、多月的数据;但是后面我下载ERA5-Land数据,发现就不能多选年份和月份了,也就是说一次性只能下载一年中一个月的数据。这个可能是由于,ERA5-Land数据的空间分辨率比较高,数据量更大,导致官方限制了ERA5-Land数据的一次性下载的限额。
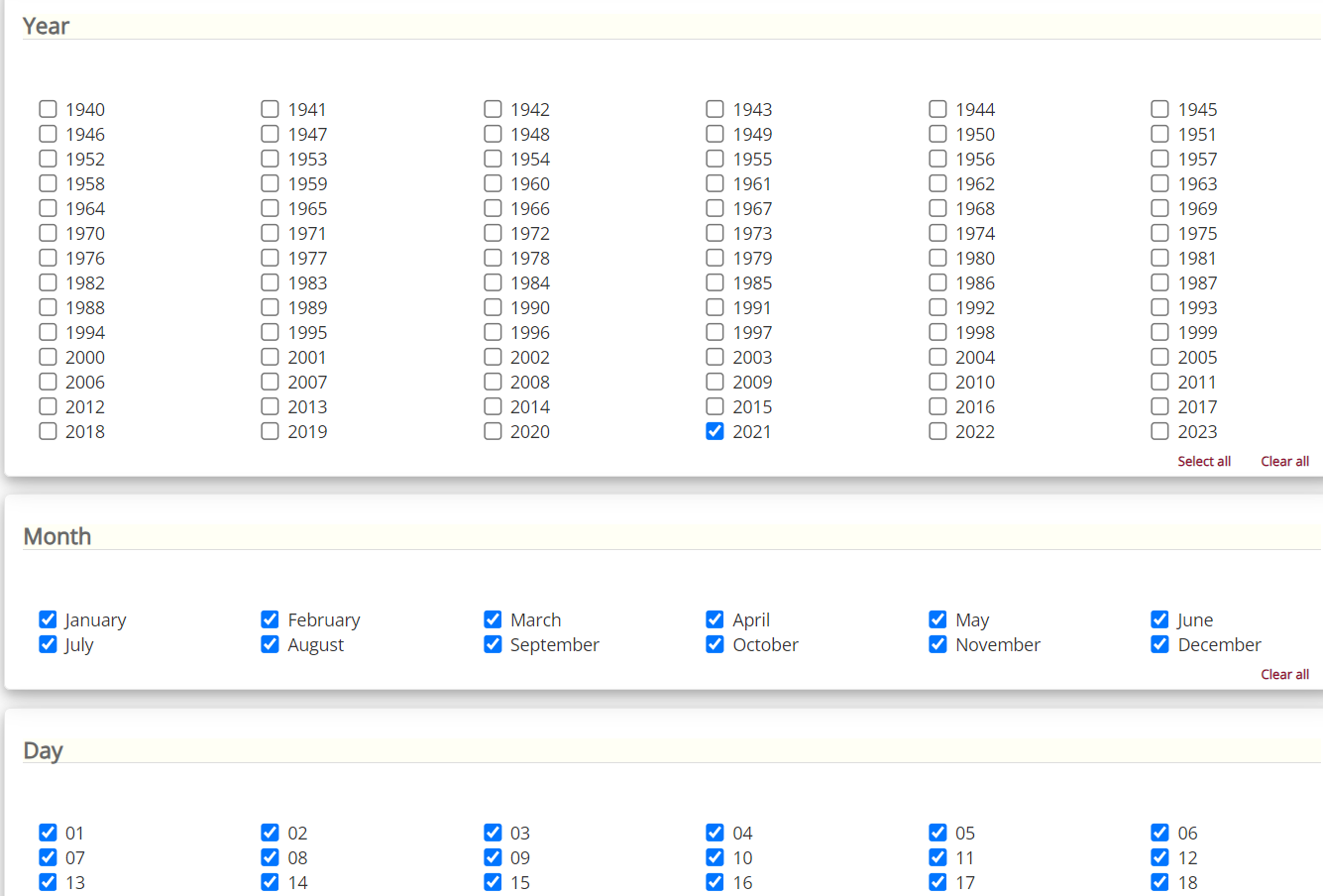
随后,选择我们要下载的数据的空间覆盖范围,并选择下载的数据格式(建议选择NetCDF格式)如下图所示。
随后,选择下图中左上方的“Accept terms”选项。
至此,我们就完成了数据下载的准备部分工作。
1 手动下载
首先,我们介绍一下手动下载的方法。手动下载其实就很简单了,在完成上一个“Accept terms”选项步骤之后,上图右下角就会变成下图右下角所示的“Submit Form”选项;选择这一项即可。这个的意思是,将我们前面配置好的下载信息作为一个请求,发给服务器,服务器只要处理好这个请求,我们就可以开始下载了。

随后,可以在新的界面中,看到我们刚刚发起的这个请求;如下图所示。需要注意的是,此时我们只是将请求发送给了官方网站的服务器,服务器还需要一段时间来处理我们的请求。

如下图所示,在提交了一个请求之后,我们可以用前文的方法再提交其他的请求;这些请求都在“Your requests”界面中有所显示。
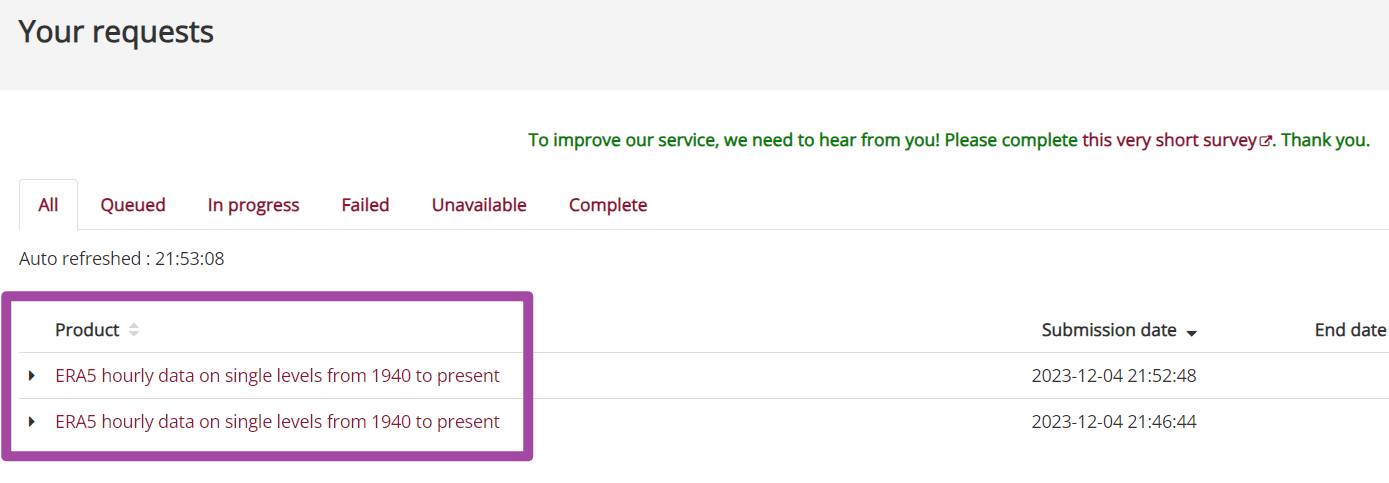
当服务器处理完毕我们的请求后,可以看到请求列表右侧出现了“Download”选项,点击它就可以下载数据了。

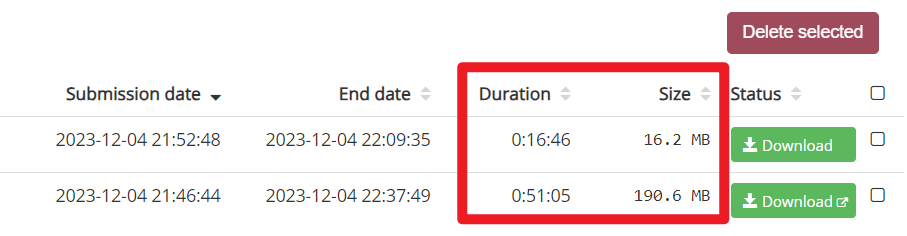
一般情况下,服务器处理我们请求的时间是不一定的,受到所要下载数据的大小、服务器繁忙情况等影响;如下图所示,我这两个请求,一个是不到200 MB的数据,一个是不到20 MB的数据,分别经过了将近1个小时、20分钟才请求完毕、可以下载,这个速度不算很快。
2 基于Python下载
接下来,我们介绍一下基于Python代码批量下载数据的方法。
首先,我们进入这个网页(https://cds.climate.copernicus.eu/#!/home);这里需要注意,进入这个网页后,首先需要通过如下的超链接,重新注册一下;我感觉这个步骤的意义就是将我们注册好的ERA5官方网站账号再赋一个API权限。
其中,如下图所示,这里的“Current password”也要输入。
随后,我们进入这个网站(https://cds.climate.copernicus.eu/api-how-to),并找到如下图所示的网页位置,将右侧黑色区域内的全部信息复制一下。
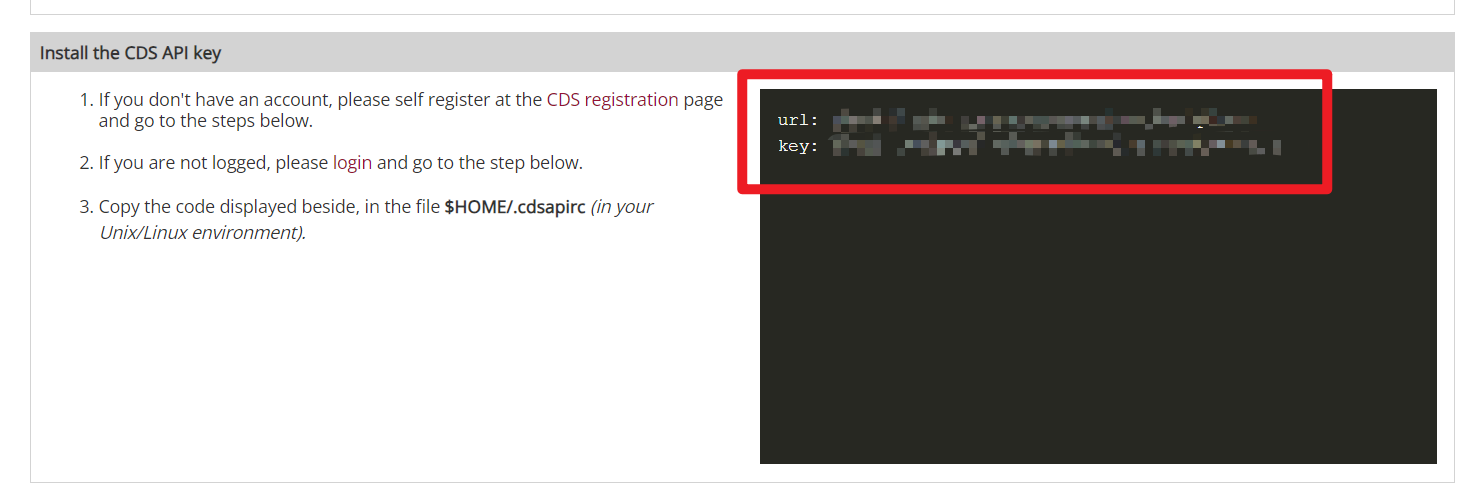
接下来,我们还需要配置一下Python代码中,用以下载ERA5数据的一个第三方库cdsapi,也就是ERA5官方开发的、专门用来供Python代码下载ERA5数据的库。如果大家此时还没有Python环境,则可以基于文章Win10中Anaconda及Python的下载与安装方法(https://blog.csdn.net/zhebushibiaoshifu/article/details/122642187)中提到的方法来配置代码环境。
接下来,我们配置cdsapi库;如果需要在虚拟环境中下载这个库,大家可以参考文章Anaconda中Python虚拟环境的创建、使用与删除(https://blog.csdn.net/zhebushibiaoshifu/article/details/128334614)中提到的方法,创建新的虚拟环境后再用如下的方法来配置这个库。
配置cdsapi库也是很简单的。我们直接在Python环境的命令行中分别输入如下代码即可(如果大家没有conda环境的话,可以用pip来安装,具体方法参考ERA5的官方网站即可)。其中,第一句代码用于在conda的配置文件中添加一个新的软件源channel,即conda-forge;conda-forge是一个社区驱动的软件源,提供了广泛的开源软件包,包括这个cdsapi库。第二句代码就是下载cdsapi库。
conda config --add channels conda-forge
conda install cdsapi
运行上述代码,如下图所示。
 )
)
我在第一次配置cdsapi库的时候,出现了如下图所示的报错;这种问题一般就是没有管理员权限导致的。
 )
)
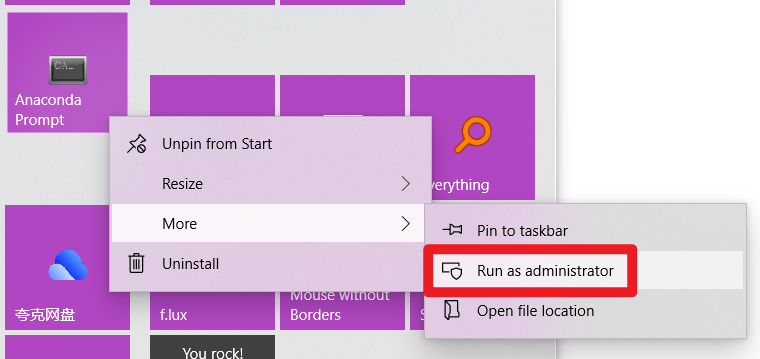
因此,选择用管理员权限打开命令行,如下图所示。
 )
)
随后,就配置好了cdsapi库;如下图所示。
 )
)
接下来,我们需要找到.cdsapirc文件,并将前面我们复制的url和key复制到其中。这里需要注意,这个.cdsapirc文件,原理上在配置完毕cdsapi库后,会自动出现在我们电脑中的C:\Users\用户名文件夹内;如下图所示。
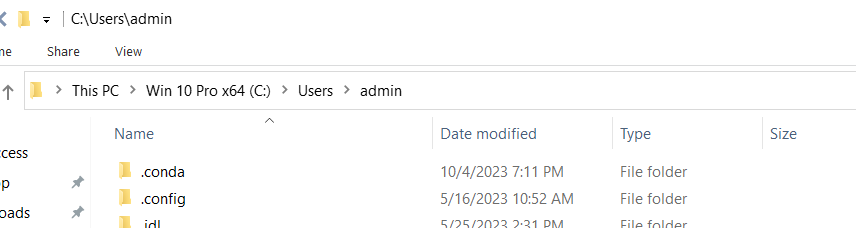
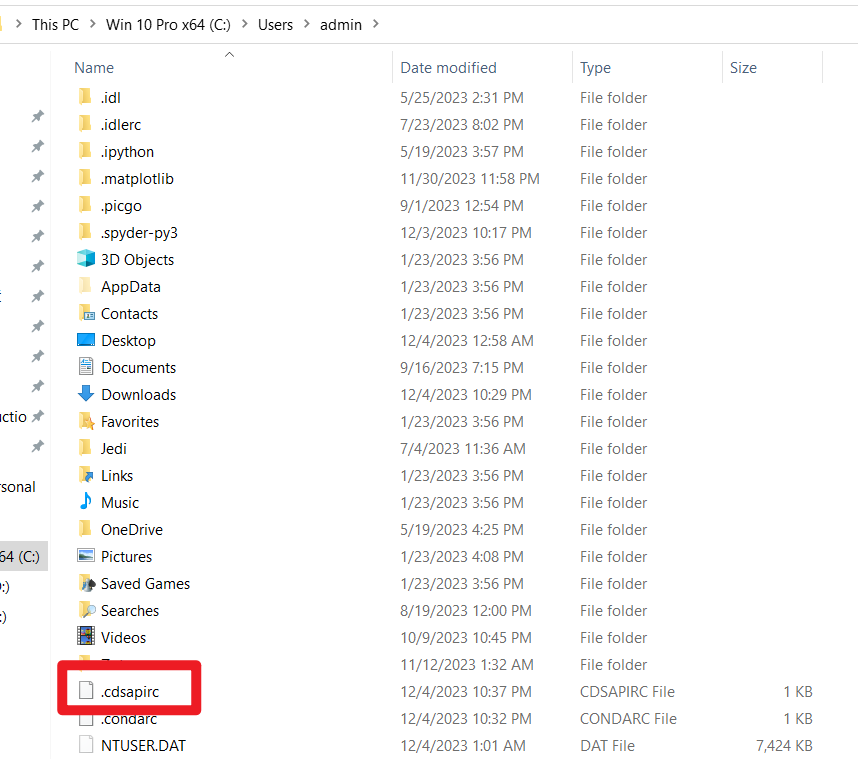
但是实际上,有的时候我们在上述文件夹内是看不到这个文件的;这样的话,我们可以在这个文件夹内新建一个.txt格式的文本文件,并将我们复制的url和key复制到其中,如下图所示。

随后,将这个.txt格式的文本文件重命名为.cdsapirc,如下图所示。
 )
)
随后,我们回到前面ERA5官方网站中,设置下载数据属性的那个网站,并选择最左侧的“Show API request”选项;如下图所示。
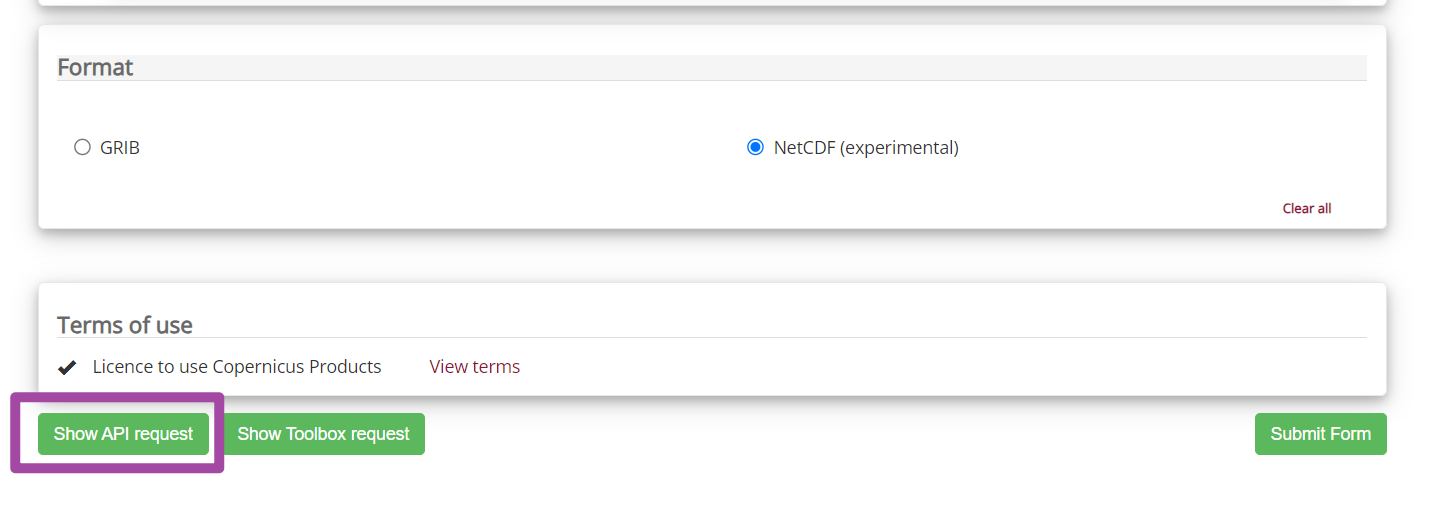
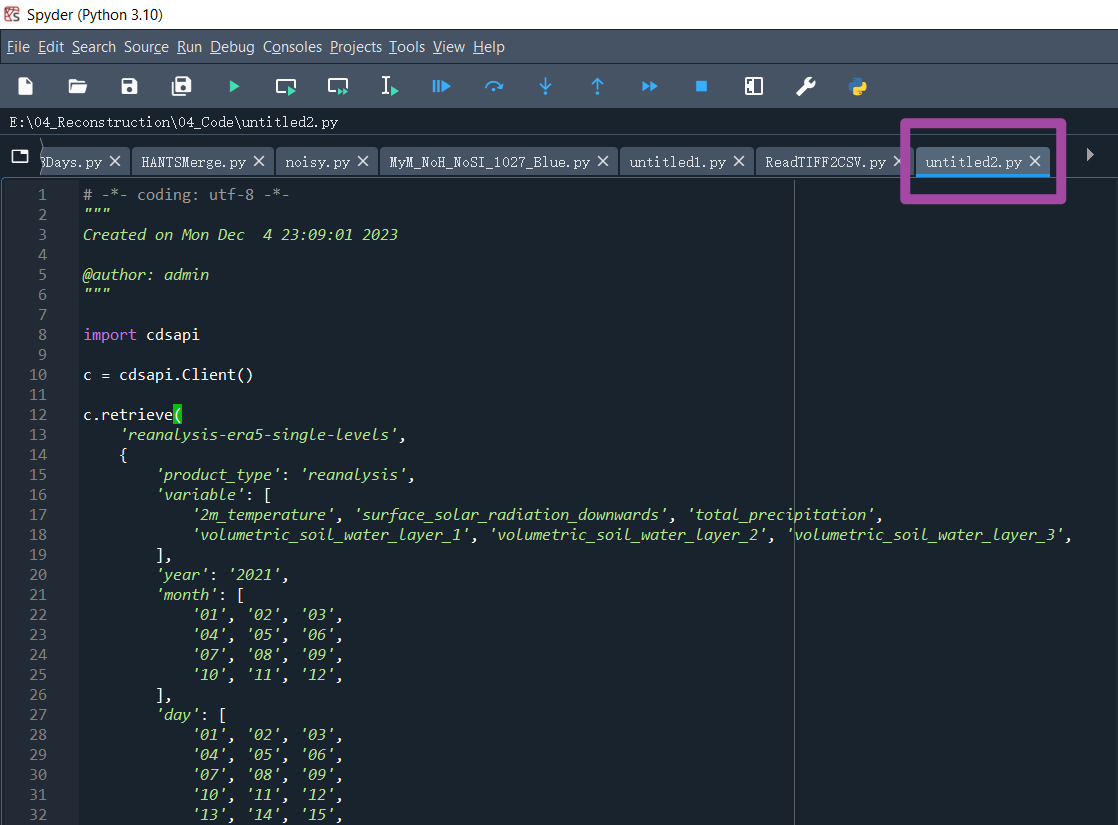
随后,会出现一个Python代码;如下图所示。我们将这个代码复制到自己的Python语言的IDE中,执行代码即可。

复制后如下图所示。
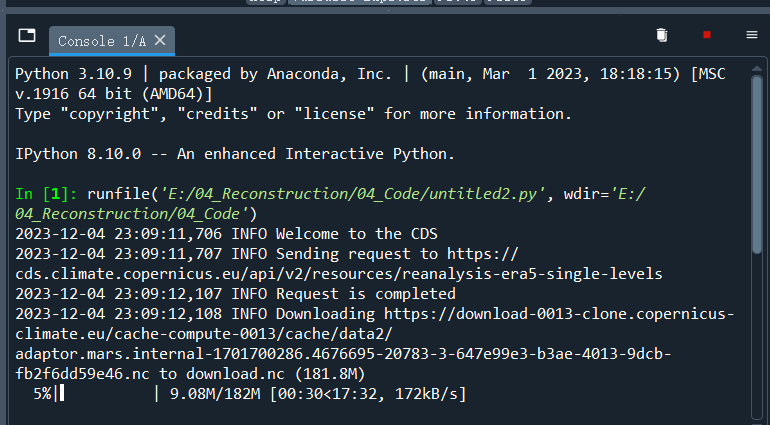
随后,执行上述复制后的代码,如下图所示。可以看到,已经开始代码的下载了。
 )
)
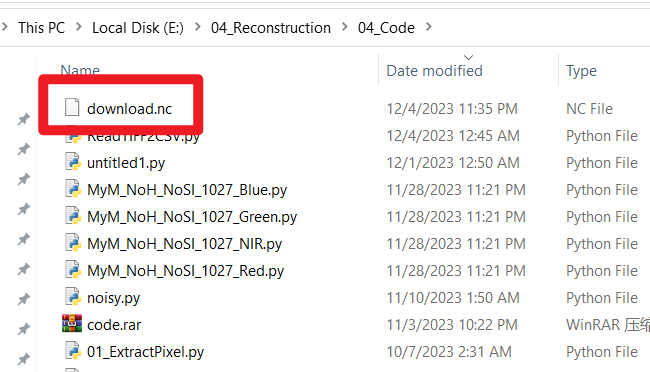
这里需要注意,下载的气象数据默认保存在Python代码所在的文件夹中;如下图所示。
 )
)
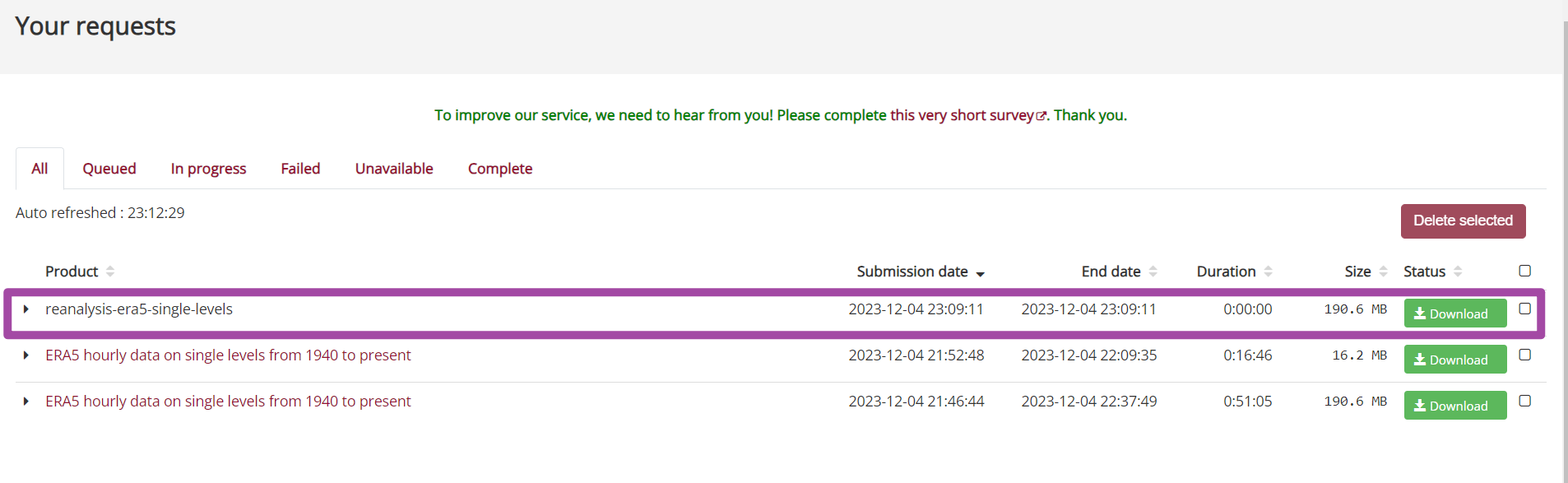
此外,我们通过上述方式获取的数据,其实也是一个向服务器发送的请求,也是需要首先处理请求、随后在Python中开始下载的;我们同样可以在“Your requests”页面中看到我们通过Python下载数据的请求。下图中,Python下载数据的请求处理数据为0,这个是因为对于同一个数据,我先用手动下载的方式提交过一次请求了,服务器处理之后我又用Python提交了一次请求,所以Python下载数据时就不用了再重新处理请求了。
同时,当时还简单对比了一下手动下载和Python下载的速度差异,但是感觉两者速度差异不大,都不算很快;但是如果用手动下载的方法,提交并处理完毕请求后,用IDM等下载软件来下载,速度就会很快——至少比用浏览器自带的下载功能,或者Python下载,要明显快很多。
至此,大功告成。
欢迎关注:疯狂学习GIS
这篇关于ERA5逐时、逐日、逐月气象数据的手动下载与Python代码批量下载方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





