本文主要是介绍python气象数据处理--按照时间序列计算格点数据指标,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
python气象数据处理–按照时间序列计算格点数据指标
聚合分类分析
- python气象数据处理--按照时间序列计算格点数据指标
- 前言
- 一、以hourly数据为例
- 二、使用步骤
- 1.引入库并读取数据
- 2.处理指标
- 总结
前言
气象数据常常以netcdf的形式存储,通常以hourly、daily、monthly、yearly等时间精度存储,但是我们常常需要处理成月、年、季节、气候态等数据。因此需要对其进行时间维度上的计算,常常运用xarray或者pandas进行计算。
一、以hourly数据为例
我们从ERA5官网下载的hourly气温数据,将其处理成不同的指标数据。如(日循环、月循环、年循环、月、季节气候态平均等指标)
二、使用步骤
1.引入库并读取数据
代码如下(示例):
import warnings
warnings.filterwarnings("ignore")
import numpy as np
import netCDF4 as nc
import pandas as pd
import xarray as xr
#读取变量、时间、经度和纬度信息
path0='E:/csdn_test/data/ERA5_hourly/t2m/'
mf=xr.open_mfdataset(path0+'/*.nc')
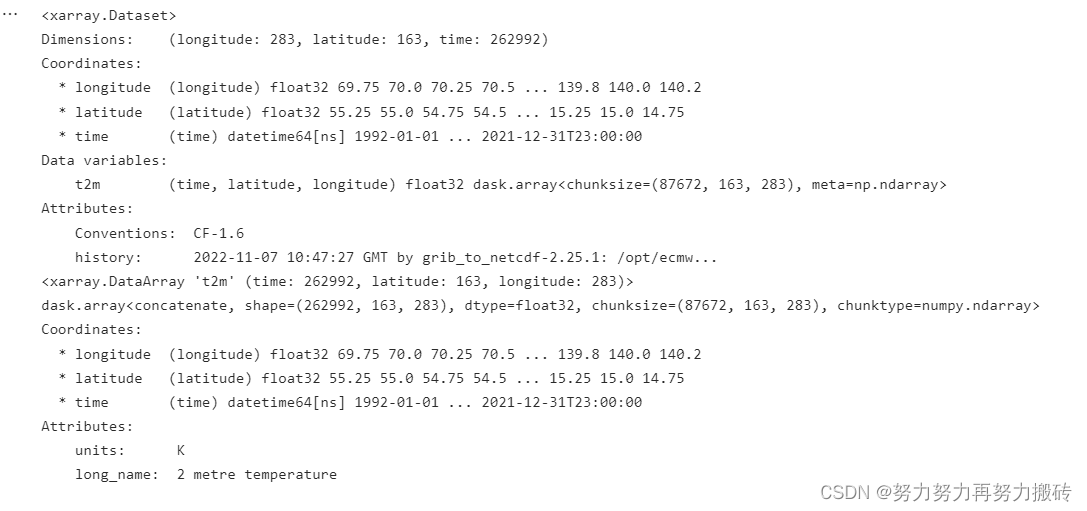
print(mf)
t2m=mf['t2m']
lon=t2m.longitude
lat=t2m.latitude
2.处理指标
1)分组聚合(a.groupby())
会自动跳过缺测,如果有缺测值要进行处理
以上数据集的维度坐标time为日期时间型对象,通过其dt属性可以按照日期时间进行分组。
代码如下(示例):
#按照日、月、年、季节循环输出,但是groupby会自动跳过缺测值
t2m_hour=t2m.groupby(t2m.time.dt.hour).mean()# sum, std, min, max
t2m_month=t2m.groupby(t2m.time.dt.month).mean()
t2m_year=t2m.groupby(t2m.time.dt.year).mean()
t2m_season=t2m.groupby(t2m.time.dt.season).mean()
print(t2m_season)
#按照春夏秋冬顺序求季节平均
def month_to_season(month):return (month - 3) % 12 // 3 + 1
t2m_ss=t2m.groupby(month_to_season(t2m.time.dt.month)).mean()
print(t2m_ss)
t2m_std=t2m.groupby(t2m.time.dt.year).std()
t2m_year_min=t2m.groupby(t2m.time.dt.year).min()
季节分组不是按照春、夏、秋、冬分布的,因此可以对算法进行优化

2)利用resample重采样计算resample
时间频率如下
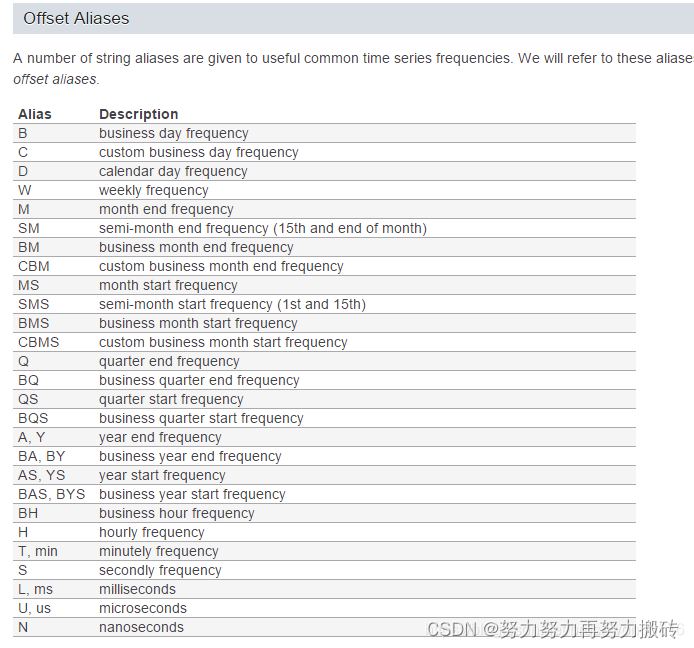
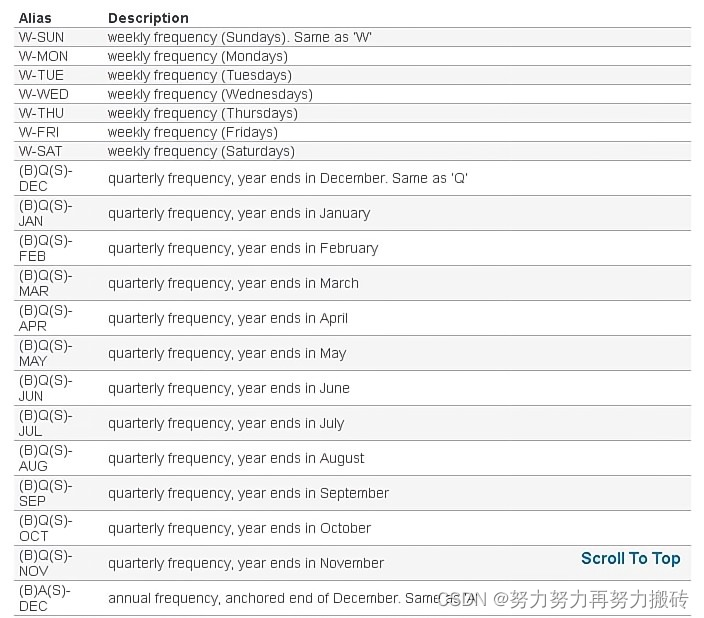
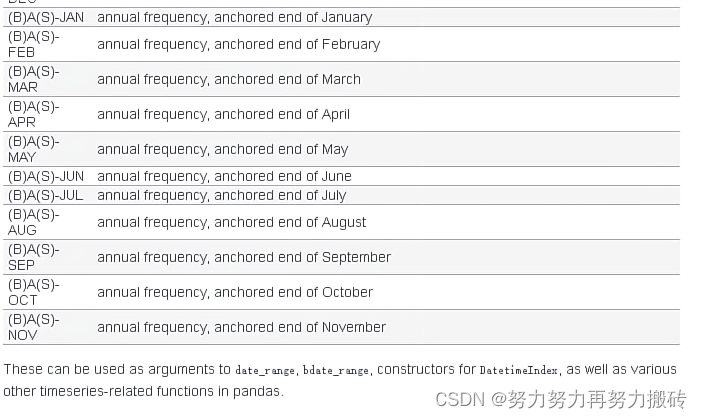
代码如下(示例):
#resample
#按日、月、季节、年平均统计(降采样)
t2mD=t2m.resample(time='D').mean()# sum, std, min, max
t2mM=t2m.resample(time='M').mean()
t2mY=t2m.resample(time='Y').mean()
t2mS=t2m.loc['1992-03':'2021-12'].resample(time='3M').mean()
t2mS1=t2m.resample(time="QS-DEC").mean()
#如果含有缺测值
t2mS1=(t2m.notnull()).resample(time="QS-DEC").mean()
#同理groupby也可以使用
t2m_year_min=(t2m.notnull()).groupby(t2m.time.dt.year).min()

3)特定变量维度
代码如下(示例):
#选择特定时间、经纬度
#t = np.array(t2m.time.dt.month.isin([12,1,2]).loc['1979-12-01':'2020-03-01',850,50:30,110:130]).mean((1,2)).reshape(41,3).mean((1))
#提取季节数据和月数据等,以提取冬季数据为例
t2m_winter1=t2m.loc[t2m.time.dt.month.isin([12,1,2])].loc['1992-12-01':'2021-03-01']
t2m_winter2=t2m.loc[t2m.time.dt.season.isin(['DJF'])]
t2m1=t2m.loc[t2m.time.dt.month.isin([12,1,2])].loc['1992-01-01':'1993-12-31',50:30,110:130]
t2m1.mean(dim=['latitude', 'longitude'])
总结
使用groupby和使用Pandas的resample函数都可以实现类似的分组聚合,但是各有区别。
groupby实现的是日、月、季节、年,是按照同一时次、同一月、同一季节、同一年进行聚合,维对应[24,x,x]、[12,x,x]、[4,x,x]、[30,x,x],以日循环为例,同一个时次的月、年都求了平均
resample对应的月[360,x,x],则是不同年份求出的月平均
可以根据不同的需求选择不同的计算方式
参考链接:
xarray实例大全
相关分析和回归分析
这篇关于python气象数据处理--按照时间序列计算格点数据指标的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





