本文主要是介绍深度学习(六):paddleOCR理解及识别手写体,手写公式,表格,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.介绍
1.1 什么是OCR?
光学字符识别(Optical Character Recognition, OCR),ORC是指对包含文本资料的图像文件进行分析识别处理,获取文字及版面信息的技术,检测图像中的文本资料,并且识别出文本的内容。
那么有哪些应用场景呢?
其实我们日常生活中处处都有ocr的影子,比如在疫情期间身份证识别录入信息、车辆车牌号识别、自动驾驶等。我们的生活中,机器学习已经越来越多的扮演着重要角色,也不再是神秘的东西。
OCR的技术路线是什么呢?
ocr的运行方式:输入->图像预处理->文字检测->文本识别->输出

1.2paddleOCR
PaddleOCR是一个基于深度学习的中文OCR(光学字符识别)工具,由清华大学KEG实验室和智谱AI公司开发。它是一个开源的OCR引擎,可以识别中文、英文、数字等多种字体,支持表格、PDF、图片等多种格式。PaddleOCR具有高精度、高召回率、高效率等优点,已经被广泛应用于金融、医疗、电商等多个领域。
以下是PaddleOCR的一些主要功能和特点:
- 中文识别:PaddleOCR支持中文识别,可以识别多种字体和格式,如表格、PDF、图片等。
- 英文识别:PaddleOCR也支持英文识别,可以识别英文格式。
- 数字识别:PaddleOCR可以识别数字格式,包括整数和小数。
- 表格识别:PaddleOCR可以识别表格格式,可以提取表格中的数据。
- PDF识别:PaddleOCR可以识别PDF格式,可以提取PDF中的文本和图片。
- 图片识别:PaddleOCR可以识别图片格式,可以提取图片中的文本和图片。
- 高精度:PaddleOCR具有高精度,可以识别高复杂度文本和格式。
- 高召回率:PaddleOCR具有高召回率,可以识别漏掉的文本和格式。
- 高效率:PaddleOCR具有高效率,可以快速识别文本和格式。
总之,PaddleOCR是一个强大的OCR引擎,可以识别多种格式和字体,具有高精度、高召回率和高效率等特点,已经被广泛应用于多个领域。
1.3使用方法
1. ocr(image, use_angle_cls=False, use_distance_cls=False, rotate_mode=’ clockwise’, language=‘eng’, force_cpu=False, return_
RESULT=False):该方法是 PaddleOCR
的核心方法,用于实现图像文本检测和识别。它接受一张图像作为输入,并返回一个包含文本检测结果和识别的结果的字典。
2. rotate_image(image, angle):该方法用于对图像进行旋转,支持顺时针和逆时针两种旋转方式。
3. rescale_image(image, scale):该方法用于对图像进行缩放,支持按比例和不按比例两种缩放方式。
4. preprocess_image(image):该方法用于对图像进行预处理,包括归一化、去噪、二值化等操作。
5. postprocess_prediction(boxes, probs, class_labels):该方法用于对文本检测结果进行后处理,包括过滤噪声、去除重复框、修正文本框等操作。
6. draw_detections(image, boxes, probs, class_labels, min_conf=0.5):该方法用于在图像上绘制文本检测结果,包括文本框、类别标签和概率等信息。
7. batch_ocr(images, use_angle_cls=False, use_distance_cls=False, rotate_mode=‘clockwise’, language=‘eng’, force_cpu=False,
return_RESULT=False):该方法用于实现批处理文本检测和识别,支持同时处理多张图像。
8. create_predictor(model_path, use_angle_cls=False, use_distance_cls=False, rotate_mode=‘clockwise’,
language=‘eng’):该方法用于创建文本检测和识别的预测器,支持加载预训练模型和自定义模型。
9. save_checkpoint(model_path, epoch, save_optimizer=False):该方法用于保存模型的检查点文件,支持保存当前训练的模型和优化器。
10. draw_text(image, text, position, font, color, thickness):该方法用于在图像上绘制文本,支持设置文本的位置、字体、颜色和粗细等参数。
该方法用于在图像上绘制文本,可以设置文本的位置、字体、颜色和粗细等参数。它是 PaddleOCR
中一个非常实用的方法,可以用于生成文本标签、添加说明等操作。
11. restore_checkpoint(model_path):该方法用于恢复模型的检查点文件,支持加载之前训练的模型。
12. accuracy(predictions, ground_truth):该方法用于计算文本检测和识别的准确率,支持同时计算多个类别的准确率。
13. evaluate(predictions, ground_truth, iou_threshold=0.5):该方法用于评估文本检测和识别的结果,支持同时计算多个类别的召回率、精确率、F1 值等指标。
14. confusion_matrix(predictions, ground_truth):该方法用于生成混淆矩阵,用于分析文本检测和识别的结果。
15. classification_report(predictions, ground_truth):该方法用于生成分类报告,用于分析文本检测和识别的结果。
2.理解
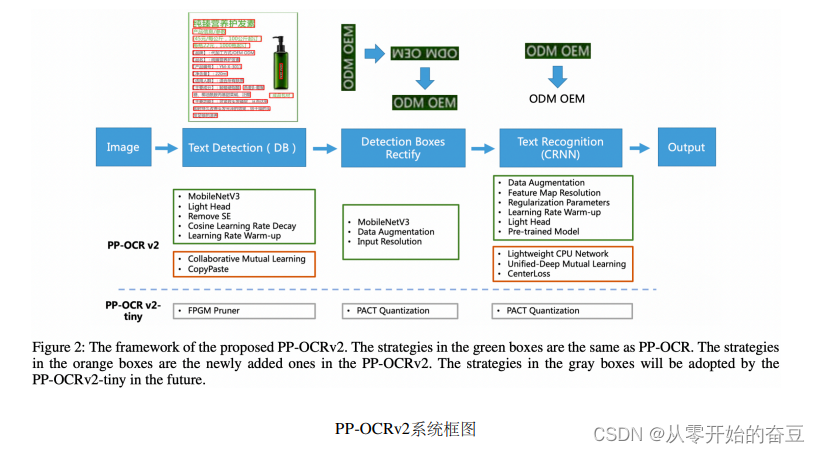
相比于PP-OCR,PP-OCRv2 在骨干网络、数据增广、损失函数这三个方面进行进一步优化,解决端侧预测效
率较差、背景复杂和相似字符误识等问题,同时引入了知识蒸馏训练策略,进一步提升模型精度。具体地:
• 检测模型优化: (1) 采用 CML 协同互学习知识蒸馏策略;(2) CopyPaste 数据增广策略;
• 识别模型优化: (1) PP-LCNet 轻量级骨干网络;(2) U-DML 改进知识蒸馏策略;(3) Enhanced CTC loss 损
失函数改进。
从效果上看,主要有三个方面提升:
• 在模型效果上,相对于 PP-OCR mobile 版本提升超7%;
• 在速度上,相对于 PP-OCR server 版本提升超过220%;
• 在模型大小上,11.6M 的总大小,服务器端和移动端都可以轻松部署。
3.实现
3.1手写体
安装导入
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple paddlepaddle
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple paddleocr
from paddleocr import PaddleOCR
import reocr = PaddleOCR(lang="ch") # 使用中文识别
result = ocr.ocr("tp.png")for line in result:print(line) # 输出识别结果


3.2手写公式
ocr = PaddleOCR(lang="ch",model_path="path/to/数学符号识别模型")
# 使用数学符号识别模型进行公式识别
result = ocr.ocr("gs.png")
for line in result:# 输入文本equation_text = lineprint(equation_text)
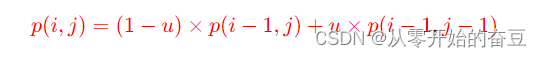

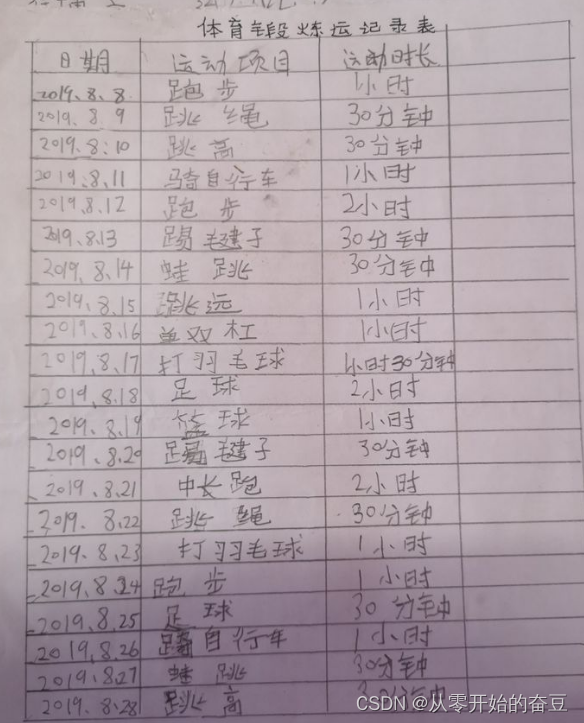
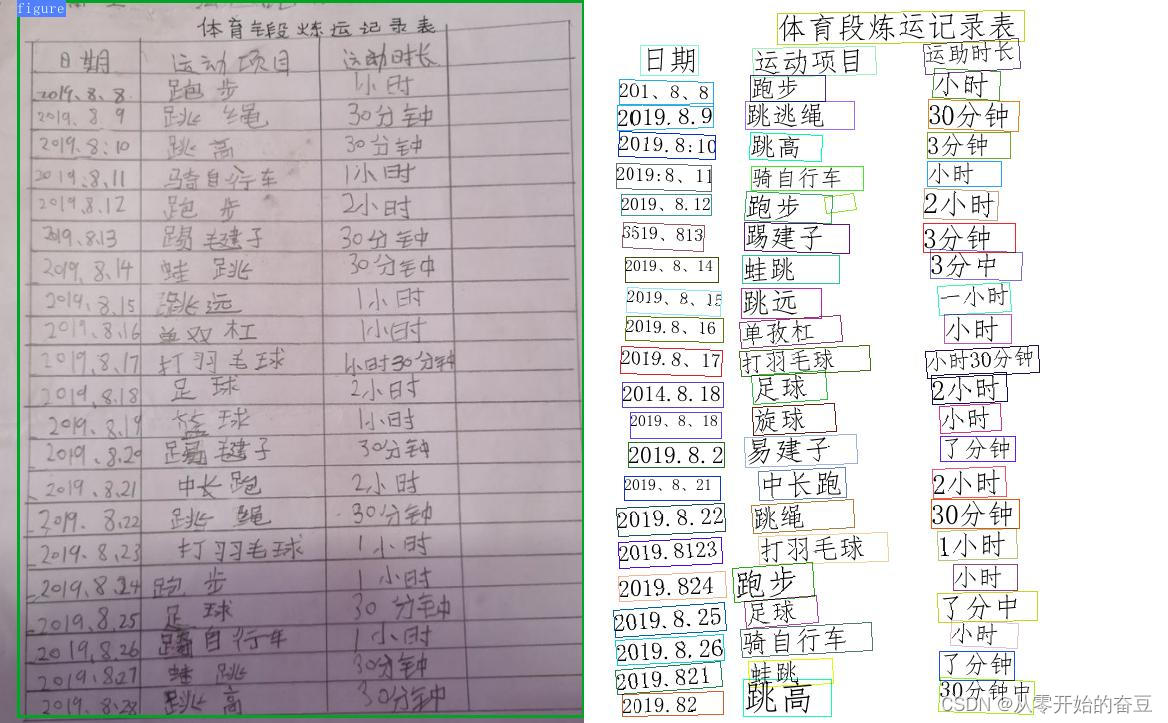
3.3表格识别
import os
import cv2
from paddleocr import PPStructure,draw_structure_result,save_structure_restable_engine = PPStructure(show_log=True)save_folder = './output'
img_path = 'BG.png'
img = cv2.imread(img_path)
result = table_engine(img)
save_structure_res(result, save_folder,os.path.basename(img_path).split('.')[0])for line in result:line.pop('img')print(line)from PIL import Imagefont_path = 'doc/fonts/simfang.ttf' # PaddleOCR下提供字体包
image = Image.open(img_path).convert('RGB')
im_show = draw_structure_result(image, result,font_path=font_path)
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
这篇关于深度学习(六):paddleOCR理解及识别手写体,手写公式,表格的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





