本文主要是介绍GPU 编程 CPU 异同点_时代变了!NVIDIA A100 GPU推理性能237倍碾压CPU-NVIDIA,A100,推理,人工智能,安培 ——快科技(驱动之家旗下媒体)-...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
MLPerf组织今天发布最新的推理基准测试(Benchmark)MLPerf Inference v结果,总共有23个组织提交了结果,相比上一个版本(MLPerf Inference )的12个提交者增加了近一倍。

结果显示,今年5月NVIDIA(Nvidia)发布的安培(Ampere)架构A100 Tensor Core GPU,在云端推理的基准测试性能是最先进Intel CPU的237倍。
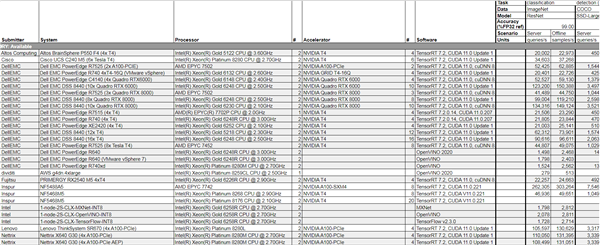
MLPerf Inference V部分结果截图
最新的AI推理测试结果意味着,NVIDIA未来可能在AI推理和训练市场都占据领导地位,给云端AI推理市场拥有优势的Intel带来更大压力的同时,也将让其他追赶者面临更大挑战。
MLPerf推理基准测试进一步完善的价值
与2019年的MLPerf Inference 版本相比,最新的版本将测试从AI研究的核心视觉和语言的5项测试,扩展了到了包括推荐系统、自然语言理解、语音识别和医疗影像应用的6项测试,并且有分别针对云端和终端推理的测试,还加入了手机和笔记本电脑的结果。
扩展的测试项从MLPerf和业界两个角度都有积极意义。

MLPerf Inference 测试项
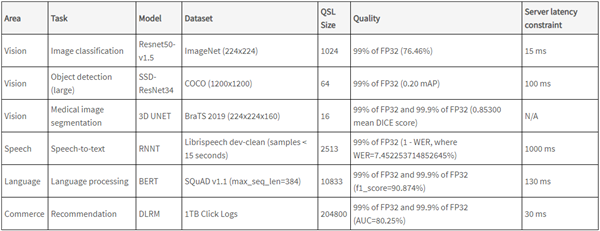
MLPerf Inference v数据中心测试项
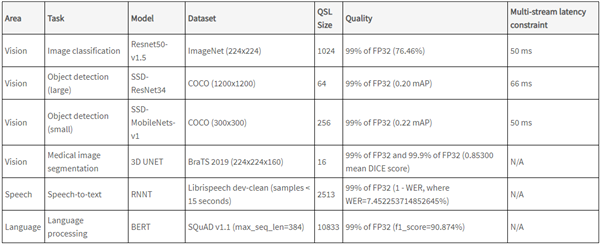
MLPerf Inference v边缘端测试项
任何一个基准测试都需要给业界具有参考价值的指标。MLPerf基准测试是在业界缺乏对AI芯片公认的评价标准的2018年诞生,因此,MLPerf组织既需要给出各方都认可的成绩,还需要根据AI行业的发展完善评价标准。
不过,AI行业发展迅速,AI模型的参数越来越多,应用的场景也越来越广泛。评价AI芯片和系统的推理性能需要涵盖可编程性、延迟、准确性、模型大小、吞吐量、能效等指标,也需要选择更具指导价值的模型和应用。
此次增加的推荐系统测试对于互联网公司意义重大。在王喆的《深度学习推荐系统》一书中提到,2019年天猫“双11”的成交额是2684亿元,假设推荐系统进行了优化,整体的转化率提高1%,那么增加的成交额大约为亿元。
另外,MLPerf Inference v中增加医疗影像3D U-Net模型测试与新冠大流行以及AI在医疗行业的重要性与日俱增密切相关,比如一家初创公司使用AI简化了超声心电图的采集工作,在新冠大流行初期发挥了作用。
基准测试从到v,能够为要选用AI芯片和系统的公司提供更直观和有价值的参考是MLPerf基准测试的价值所在,比如,帮助金融结构的会话式AI更快速回答客户问题,帮助零售商使用AI保证货架库存充足。
与此同时,这也将促进MLPerf组织在业界的受认可程度,从接近翻倍的提交成绩的组织就能看出来。
GPU云端推理性能最高是CPU的237倍
过去几年,云端AI训练市场NVIDIA拥有绝对优势,云端AI推理市场被Intel赚取了大部分利润是事实。这让不少人都产生了GPU更适合训练而CPU更适合推理的认知,但MLPerf最新的推理测试结果可能会改变这一观点。
MLPerf Inference V的测试结果显示,在数据中心OFFLINE(离线)测试模式下,赛灵思U250和IntelCooper Lake在各个测试模型下与NVIDIAT4的差距不大,但A100对比CPU、FPGA和自家的T4就有明显的性能差距。
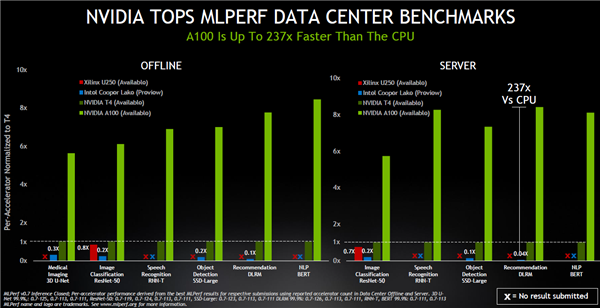
在SERVER模式下的推荐系统DLRM模型下,A100 GPU对比IntelCooper Lake有最高237倍的性能差距,在其他模型下也有比较显著的差距。值得注意的是,Intel的Cooper Lake系统的状态还是预览,其余三款芯片的系统都已经可用。
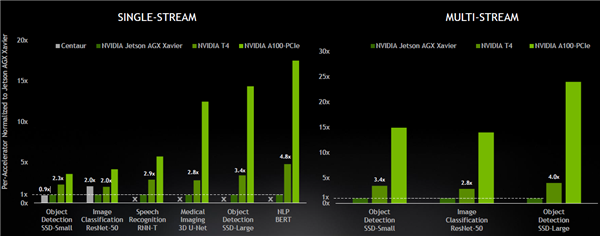
A100 GPU的优势也在边缘推理中也十分明显。在单数据流(Singel-Stream)测试中,A100对比NVIDIAT4和面向边缘终端的NVIDIAJetson AGX Xavier有几倍到十几倍的性能优势。在多数据流(Multi-Stream)测试中,A100对比另外两款自家产品在不同AI模型中有几倍到二十多倍的性能优势。
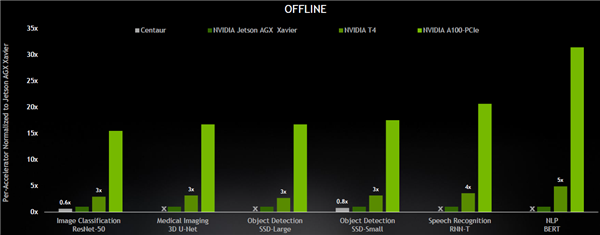
在边缘OFFLINE模式下,A100对比T4和Jetson AGX Xavier也有几倍到二十多倍的性能优势。
这很好地说明A100的安培架构以及其第三代Tensor Core优势的同时,也表明了NVIDIA能够覆盖整个AI推理市场。
在此次提交结果的23家公司中,除了NVIDIA外还有11家其合作伙伴提交了基于NVIDIA GPU的1029个测试结果,占数据中心和边缘类别中参评测试结果总数的85%以上。
从提交结果的合作伙伴的系统中可以看到,NVIDIAT4仍然是企业的边缘服务器推理平台的主要选择。A100提升到新高度的性能意味着未来企业边缘服务器在选择AI推理平台的时候,可以从T4升级到A100,对于功耗受限的设备,可以选择Jeston系列产品。
特别值得注意的是,NVIDIA GPU首次在公有云中实现了超越CPU的AI推理能力。
临界点到来?AI推理芯片市场竞争门槛更高
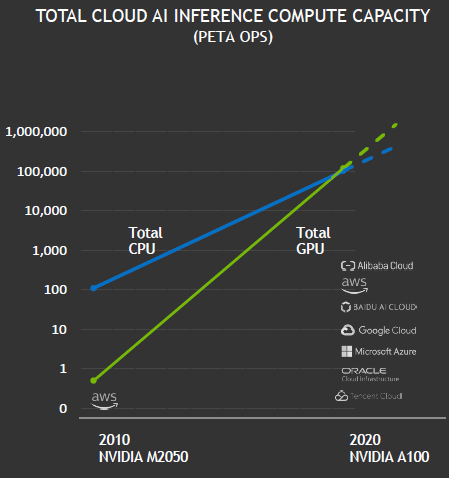
五年前,只有少数领先的高科技公司使用GPU进行推理。如今,NVIDIAGPU首次在公有云市场实现超越CPU的AI推理能力,或许意味着AI推理市场临界点的到来。NVIDIA还预测,基于其GPU的总体云端AI推理计算能力每两年增长约10倍,增长速度高于CPU。
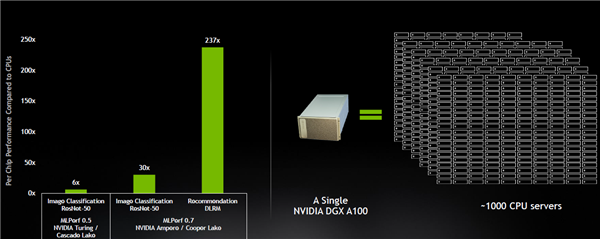
另外,NVIDIA还强调基于A100高性能系统的成本效益。NVIDIA表示,一套DGX A100系统可以提供相当于近1000台双插槽CPU服务器的性能,能为客户AI推荐系统模型从研发走向生产的过程,具有极高的成本效益。
同时,NVIDIA也在不断优化推理软件堆栈,进一步提升在推理市场的竞争力。
最先感受到影响的会是Intel,但在云端AI推理市场体现出显著变化至少需要几年时间,因为企业在更换平台的时候会更加谨慎,生态的护城河此时也更能体现出价值。
但无论如何,我们都看到NVIDIA在AI市场的强势地位。雷锋网七月底报道,在MLPerf发布的MLPerf Training v基准测试中,A100 Tensor Core GPU,和HDR InfiniBand实现多个DGX A100 系统互联的庞大集群DGX SuperPOD系统在性能上开创了八个全新里程碑,共打破16项纪录。
安培架构A100在MLPerf最新的训练和推理成绩表明NVIDIA不仅给云端AI训练的竞争者更大的压力,也可能改变AI推理市场的格局。
NVIDIA将其在云端训练市场的优势进一步拓展到云端和边缘推理市场符合AI未来的发展趋势。有预测指出,随着AI模型的成熟,市场对云端AI训练需求的增速将会降低,云端AI推理的市场规模将会迅速增加,并有望在2022年超过训练市场。
另据市场咨询公司ABI Research的数据,预计到2025年,边缘AI芯片市场收入将达到122亿美元,云端AI芯片市场收入将达到119亿美元,边缘AI芯片市场将超过云端AI芯片市场。
凭借强大的软硬件生态系统,NVIDIA和Intel依旧会是AI市场的重要玩家,只是随着他们竞争力的不断提升,其他参与AI市场竞争的AI芯片公司们面临的压力也随之增加。

- THE END -
#NVIDIA#显卡#人工智能
原文链接:雷锋网责任编辑:上方文Q
这篇关于GPU 编程 CPU 异同点_时代变了!NVIDIA A100 GPU推理性能237倍碾压CPU-NVIDIA,A100,推理,人工智能,安培 ——快科技(驱动之家旗下媒体)-...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





