a100专题

A100 显卡关键参数
全局视图 首先看top图,A100包含有108个SM,每个SM最大可以容纳1024个threads. SM视图 下面是一个SM的视图: 算力 算力: 加工工艺 工艺采用的是7nm工艺: 关键参数 实际测量参数 下面是关键参数: device properties : name : NVIDIA A100-PCIE-40GBtotalGlobalMem : 422

“华为Ascend 910B AI芯片挑战NVIDIA A100:效能比肩,市场角逐加剧“
华为自主研发的人工智能芯片——Ascend 910B,近期在世界半导体大会及南京国际半导体博览会上由华为ICT基础设施管理委员会执行董事、主任王涛发表声明称,该芯片在训练大规模语言模型时的效率高达80%,与NVIDIA的A100相比毫不逊色,且在具体测试性能上更是超出NVIDIA A100 AI GPU约20%之多。这表明华为在AI芯片领域取得了重大突破,直接挑战行业领军企业NVIDIA。 As
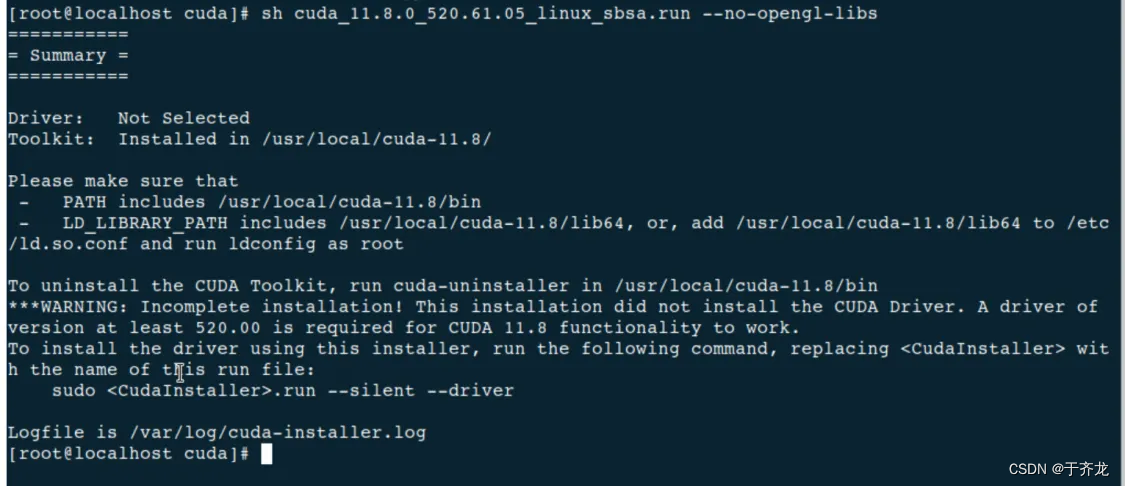
离线环境下安装NVIDIA驱动、CUDA(HUAWEI Kunpeng 920 + NVIDIA A100 + Ubuntu 20.04 LTS)
文章目录 前言 一、基础环境 1.1、处理器型号 1.2、英伟达显卡型号 1.3、操作系统 1.4、软件环境 二、取消内核自动升级 2.1、查看正在使用的内核版本 2.2、查看正在使用的内核包 2.3、禁止内核更新 三、配置本地apt源 3.1、挂载iso镜像文件 3.2、配置apt源 3.3、更新apt源 四、安装NVIDIA驱动 4.1、查看显卡型号 4.2、

centos7.9安装A100 GPU卡对应的cuda11.4环境
centos7.9安装A100 GPU卡对应的cuda11.4环境 #!/bin/bash#1.安装cuda11.4.3function installCuda(){yum-config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel7/x86_64/cuda-rhel7.rep

为何NVIDIA DGX A100在市面上如此抢手?
NVIDIA DGX A100:引领AI算力的高性能系统 前言 在当今快速发展的人工智能领域,算力成为了推动技术进步的关键因素。随着AI模型的不断壮大和复杂化,对高性能计算资源的需求也日益增长。在这样的背景下,NVIDIA A100 GPU应运而生,以其卓越的性能和广泛的适用性,迅速成为算力市场的热门选择。那么它为何会如此的火爆呢?它有着哪些优势?我们继续往下看。 DGX
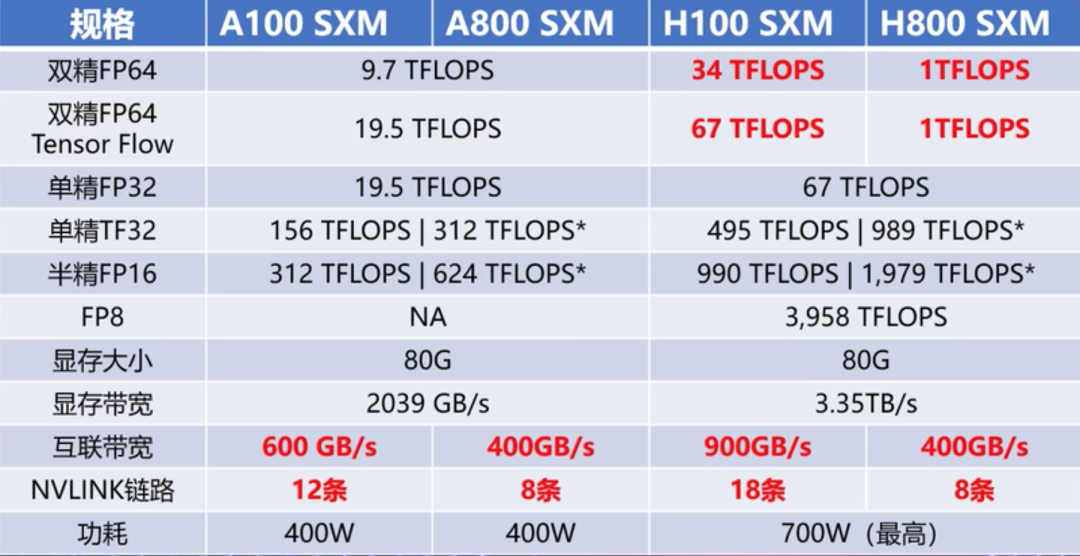
英伟达 V100、A100/800、H100/800 GPU 对比
近期,不论是国外的 ChatGPT,还是国内诸多的大模型,让 AIGC 的市场一片爆火。而在 AIGC 的种种智能表现背后,均来自于堪称天文数字的算力支持。以 ChatGPT 为例,据微软高管透露,为 ChatGPT 提供算力支持的 AI 超级计算机,是微软在 2019 年投资 10 亿美元建造一台大型顶尖超级计算机,配备了数万个 NVIDIA A100 GPU,还配备了 60 多个数据中心总共部
【AI绘画】免费GPU Tesla A100 32G算力部署Stable Diffusion
免责声明 在阅读和实践本文提供的内容之前,请注意以下免责声明: 侵权问题: 本文提供的信息仅供学习参考,不用做任何商业用途,如造成侵权,请私信我,我会立即删除,作者不对读者因使用本文所述方法而导致的任何损失或损害负责。 信息准确性: 本文提供的信息可能随时更改,作者不保证文中所述方法在未来的软件更新中仍然有效。 个人风险: 读者在按照本文提供的方法操作时,应该自行承担风险。作者不对读者因
nvidia a100-pcie-40gb环境安装
1.conda create --name torch_li python=3.8 2. conda install pytorch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2 cudatoolkit=11.0 -c pytorch 环境测试:torch.cuda.is_available() 3.conda remove -n torch_li --
AI时代显卡如何选择,B100、H200、L40S、A100、H100、V100 含架构技术和性能对比
AI时代显卡如何选择,B100、H200、L40S、A100、H100、V100 含架构技术和性能对比。 英伟达系列显卡大解析B100、H200、L40S、A100、A800、H100、H800、V100如何选择,含架构技术和性能对比带你解决疑惑。 近期,AIGC领域呈现出一片繁荣景象,其背后离不开强大算力的支持。以ChatGPT为例,其高效的运行依赖于一台由微软投资建造的超级计算机。这台超

Linux脚本练习之script001-在 `/home` 目录中创建一百个目录,目录名依次为 `a1,a2,...,a100`。
script001 题目 在 /home 目录中创建一百个目录,目录名依次为 a1,a2,...,a100。 分析 本题考查的知识点: while 循环自定义函数local 声明局部变量字符串拼接mkdir 命令 思路: 首先从 1 循环到 100,根据前缀(如 a)和数字拼接目录名。然后再将 /home/ 与目录名拼接得到待创建目录的详细路径。最后根据路径创建对应的目录。循环 10

A100显卡+CUDA11.2+pytorch训练
1.直接用如下版本的torch1.9.1+torchvision0.10.1会报如下错误: 2.官网PyTorch未找到对应cuda11.2版本的,因此直接安装cuda11.3版本 pip download torch==1.10.1+cu113 torchvision==0.11.2+cu113 torchaudio==0.10.1+cu113 -f https://downl
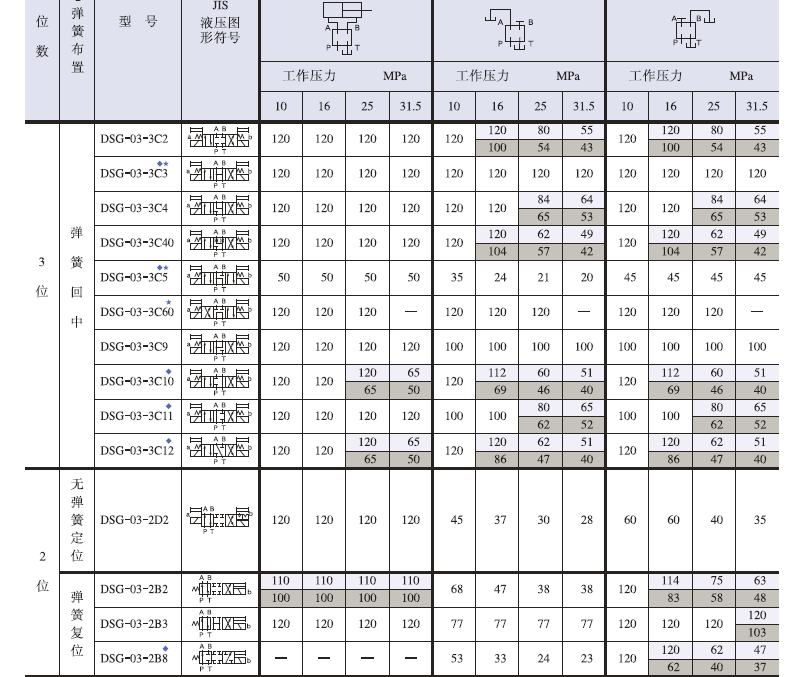
DSG-03-3C12-A100-50、DSG-03-2B3-A100-50日本油研电磁阀
电磁铁等各高压、大流量电磁阀。湿式电磁铁,寿命长,噪声低,无外部泄露。 具备有两种类型,插头式及接线盒式 标准型……高压(31.5MPa),大流量(120L/min)。 无冲击型……有效地减小阀芯换向引起的噪声和管道振动。 高吸力、强力弹簧保证了良好的稳定性。
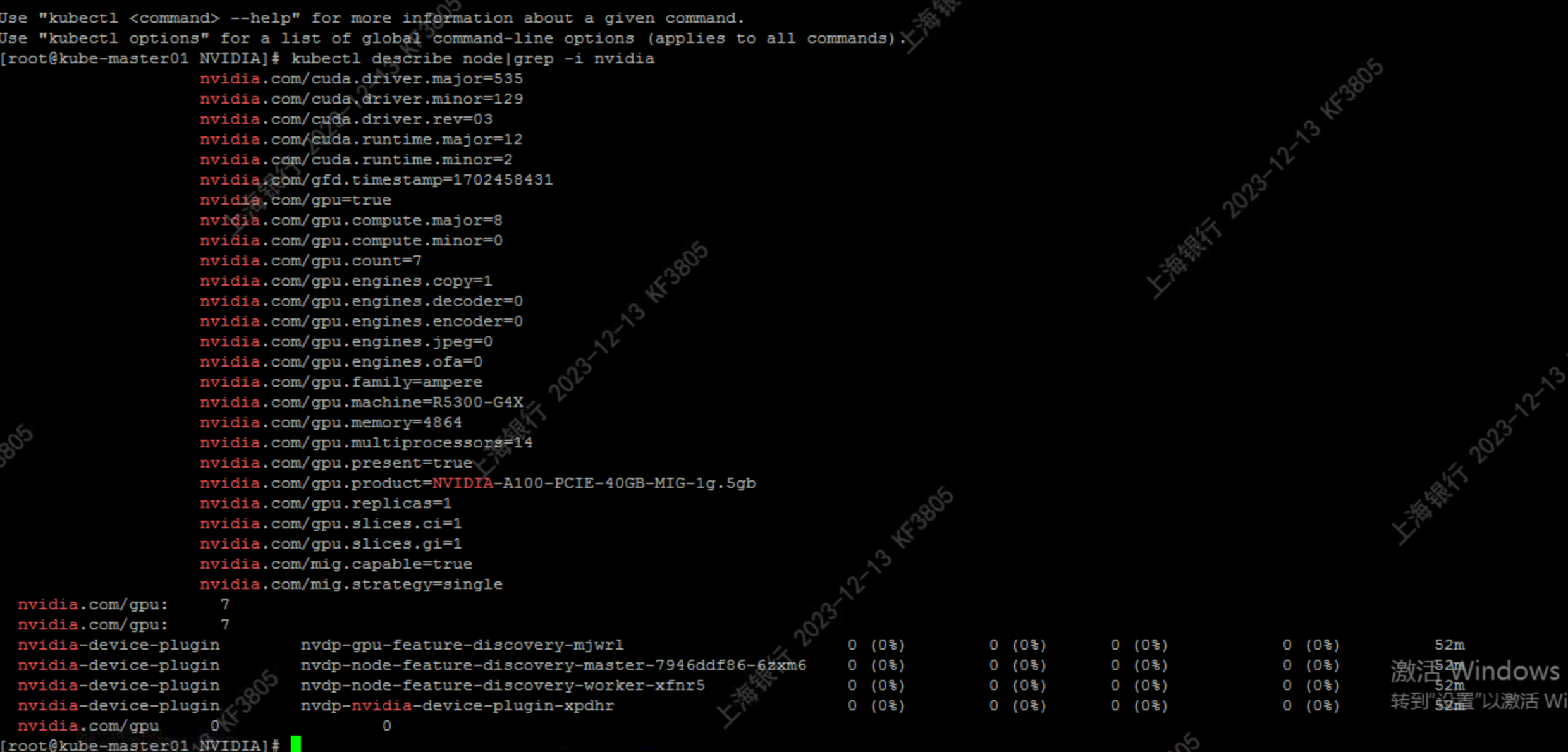
NVIDIA A100 PCIE 40GB k8s-device-plugin install in kubernetes
文章目录 1. 目标2. 简介2.1 英伟达 A100 技术规格2.2 架构优势2.3 显卡跑分对比2.4 英伟达 A100 与 kubernetes 3. 安装 NVIDIA A100 GPU 40G 硬件4. NVIDIA R450+ datacenter driver5. NVIDIA Container Toolkit6. 创建 runtimeclass5. MIG Strate
NVIDIA A100 PCIE 40GB k8s-device-plugin install in kubernetes
文章目录 1. 目标2. 简介2.1 英伟达 A100 技术规格2.2 架构优势2.3 显卡跑分对比2.4 英伟达 A100 与 kubernetes 3. 安装 NVIDIA A100 GPU 40G 硬件4. NVIDIA R450+ datacenter driver5. NVIDIA Container Toolkit6. 创建 runtimeclass5. MIG Strate
深度分析NVIDIA A100显卡架构(附论文源码下载)
计算机视觉研究院专栏 作者:Edison_G 英伟达A100 Tensor Core GPU架构深度讲解 上次“计算机视觉研究院”已经简单介绍了GPU的发展以及安培架构的A100显卡,今天我们就来更加深入讲解其高性能技术和结构,值得深度学习研究者深入学习,有兴趣加入我们学习群, 一起来讨论学习,共同进步! NVIDIA®GPU是推动人工智能革命的主要计算引擎,为人工智能训练和推理工作负载提供

GPU 编程 CPU 异同点_时代变了!NVIDIA A100 GPU推理性能237倍碾压CPU-NVIDIA,A100,推理,人工智能,安培 ——快科技(驱动之家旗下媒体)-...
MLPerf组织今天发布最新的推理基准测试(Benchmark)MLPerf Inference v结果,总共有23个组织提交了结果,相比上一个版本(MLPerf Inference )的12个提交者增加了近一倍。 结果显示,今年5月NVIDIA(Nvidia)发布的安培(Ampere)架构A100 Tensor Core GPU,在云端推理的基准测试性能是最先进Intel CPU的237

单个A100生成3D图像只需30秒,这是Adobe让文本、图像都动起来的新方法
2D 扩散模型极大地简化了图像内容的创作流程,2D 设计行业也因此发生了变革。近来,扩散模型已扩展到 3D 创作领域,减少了应用程序(如 VR、AR、机器人技术和游戏等)中的人工成本。有许多研究已经对使用预训练的 2D 扩散模型,生成具有评分蒸馏采样(SDS)损失的 NeRFs 方法进行了探索。然而,基于 SDS 的方法通常需要花费数小时来优化资源,并且经常引发图形中的几何问题,比如多面 Janu

a100高性能服务器,英伟达发布A100 PCIe计算加速卡
6月21日,据外媒报道,英伟达今天发布了采用PCIe接口的A100计算加速卡,与5月份发布的基于安培架构的SXM版本的A100计算加速卡规格相同,但采用了PCIe4.0接口,更适合主流标准服务器。 A100 PCIe使用的是今年五月英伟达发布的基于安培架构的GA100 GPU,拥有6912个CUDA内核和432个张量内核,配备了了40GB的HBM2e内存,TDP为250W。此前SXM版本为4

A100-PCIE-40GB with CUDA capability sm_80 is not compatible with the current PyTorch installation
Pytorch报错: 使用以下命令进行安装,成功安装运行: pip3 install torch==1.9.0+cu111 torchvision==0.10.0+cu111 torchaudio==0.9.0 -f https://download.pytorch.org/whl/torch_stable.html Reference: https://stackoverflow.c

英特尔AI芯片中国定制版发布!打的就是英伟达A100
丰色 发自 凹非寺量子位 | 公众号 QbitAI AIGC时代,谁说炼大模型就一定得用GPU? 英特至强CPU,运行扩散模型Stable Diffusion只需5秒就能出图。 而在这两天,专门搭载在该CPU上使用的AI加速器更是新鲜出炉。 它叫Gaudi2,面向中国市场发布,用于加速AI训练及推理,有了它,大规模部署AI便多了一种新选择。 性能上,它在MLPerf最新报告中的多种训练和推理基
本周AI热点回顾:英伟达A100训练速度可达V100的3.5倍;飞桨框架支持ONNX协议保存模型
点击左上方蓝字关注我们 01 不出所料,百度EasyDL市场份额还是第一 在 2020 年的中国机器学习平台市场,百度的 EasyDL 又拿了第一。 近日,全球权威咨询机构 IDC(国际数据公司)发布了中国《深度学习框架和平台市场份额》报告。调研数据显示,截至 2020 年 12 月,百度的「零门槛 AI 开发平台」EasyDL 以 22.80% 的市

滴滴云A100 40G+TensorFlow1.15.2 +Ubuntu 18.04 性能测试
今天拿到了滴滴云内测版A100,跑了一下 TensorFlow基准测试,现在把结果记录一下! 运行环境 平台为:滴滴云 系统为:Ubuntu 18.04 显卡为:A100-SXM4-40GB Python版本: 3.6 TensorFlow版本:1.15.2 NV编译版 系统环境: 测试方法 TensorFlow benchmarks测试方法:

a100高性能服务器,NVIDIA宣布50多款安培服务器:史上最大飞跃
NVIDIA今天宣布,NVIDIA与全球领先服务器制造商正在合作打造基于安培架构A100 GPU的高性能服务器,包括各种不同设计和配置,可以应对AI、数据、计算等领域最复杂的挑战。 迄今为止,A100服务器的数量已经达到50多款,其中30多款在今年夏天上市,另外20多款前年底前推出,品牌包括华硕、Atos、思科、戴尔、富士通、技嘉、惠与(HPE)、浪潮、联想、OSS(One Stop Syste
a100高性能服务器,NVIDIA宣布50多款安培服务器:史上最大飞跃
NVIDIA今天宣布,NVIDIA与全球领先服务器制造商正在合作打造基于安培架构A100 GPU的高性能服务器,包括各种不同设计和配置,可以应对AI、数据、计算等领域最复杂的挑战。 迄今为止,A100服务器的数量已经达到50多款,其中30多款在今年夏天上市,另外20多款前年底前推出,品牌包括华硕、Atos、思科、戴尔、富士通、技嘉、惠与(HPE)、浪潮、联想、OSS(One Stop Syste
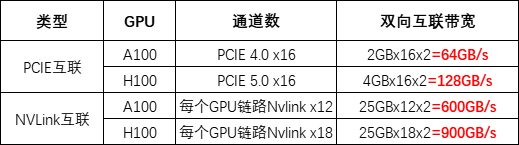
深度学习模型部署与优化:策略与实践;L40S与A100、H100的对比分析
★深度学习、机器学习、生成式AI、深度神经网络、抽象学习、Seq2Seq、VAE、GAN、GPT、BERT、预训练语言模型、Transformer、ChatGPT、GenAI、多模态大模型、视觉大模型、TensorFlow、PyTorch、Batchnorm、Scale、Crop算子、L40S、A100、H100、A800、H800 随着生成式AI应用的迅猛发展,我们正处在前所未有的大爆发时
深度学习模型部署与优化:策略与实践;L40S与A100、H100的对比分析
★深度学习、机器学习、生成式AI、深度神经网络、抽象学习、Seq2Seq、VAE、GAN、GPT、BERT、预训练语言模型、Transformer、ChatGPT、GenAI、多模态大模型、视觉大模型、TensorFlow、PyTorch、Batchnorm、Scale、Crop算子、L40S、A100、H100、A800、H800 随着生成式AI应用的迅猛发展,我们正处在前所未有的大爆发时