本文主要是介绍为何NVIDIA DGX A100在市面上如此抢手?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
NVIDIA DGX A100:引领AI算力的高性能系统
前言

在当今快速发展的人工智能领域,算力成为了推动技术进步的关键因素。随着AI模型的不断壮大和复杂化,对高性能计算资源的需求也日益增长。在这样的背景下,NVIDIA A100 GPU应运而生,以其卓越的性能和广泛的适用性,迅速成为算力市场的热门选择。那么它为何会如此的火爆呢?它有着哪些优势?我们继续往下看。
DGX A100的优势

NVIDIA DGX A100,作为基于A100 GPU的高性能AI系统,专为满足各种AI工作负载而设计。它不仅能够处理分析、训练和推理等多样化的任务,还在6U紧凑的外形规格中集成了高达5 Petaflop的AI性能,重新定义了计算密度的标准。DGX A100的推出,标志着算力市场的一次革命性飞跃,为科研、工业、医疗等多个领域的AI应用提供了强大的支持。
适用于各种AI工作通用系统

NVIDIA DGXA100 是适用于所有 AI 工作负载,包括分析、训练、推理的通用系统。DGX A100 设立了全新计算密度标准,不仅在 6U 外形规格下封装了 5 Petaflop 的 AI 性能,而且用单个统一系统取代了传统的计算基础设施。
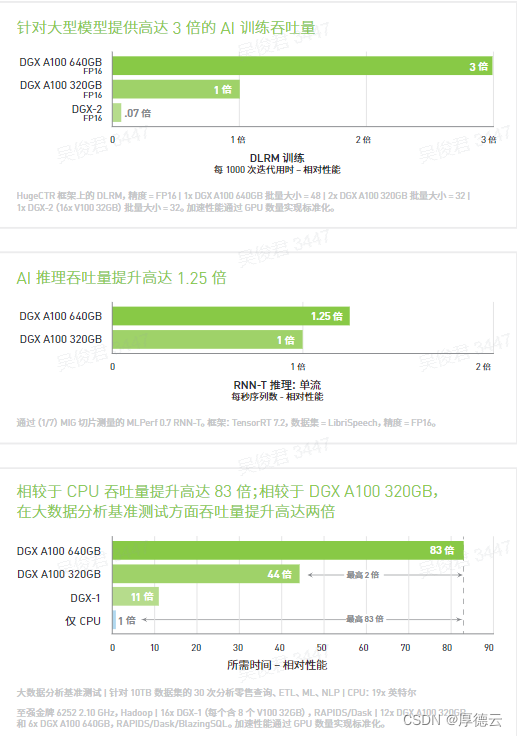
此外,DGX A100 实现了强大算力的精细分配。利用NVIDIA A100 Tensor Core GPU 中的多实例 GPU (MIG)功能,管理员可针对特定工作负载分配大小合适的资源。DGX A100 具有高达 640GB 的总 GPU 显存,可将大规模训练作业的性能提升高达 3 倍,并将 MIG 实例的大小增加一倍,从而从容应对颇为复杂的大任务,以及简单轻松的小任务。DGX A100 运行集成 NVIDIA NGC™优化软件的 DGX 软件堆栈,兼具密集算力与全面的工作负载灵活性,因而非常适合处理单节点部署以及使用 NVIDIA Bright Cluster Manager 部署的大规模 Slurm 和 Kubernetes 集群。
强大的支持能力
它基于全球最大的 DGX 集群 NVIDIA DGX SATURNV 积累的知识经验而建立,背后有 NVIDIA 数千名 DGXpert 支持。DGXpert 是一个拥有众多AI 从业者的团队,团队成员在过去十年间积累了丰富的专业知识和经验,可帮助您更大限度地提升 DGX 投资价值。DGXpert 有助于确保关键应用快速启动并保持平稳运行,从而大幅缩短获得见解的时间。
更快的解决问题
NVIDIA DGX A100 配备 8 个 NVIDIA A100 Tensor Core GPU,可出色完成加速任务,并针对 NVIDIA CUDA-X™软件和整套端到端 NVIDIA 数据中心解决方案进行全面优化。NVIDIA A100 GPU 引入 Tensor Float 32 (TF32)精度,即 TensorFlow 和PyTorch AI 框架的默认精度格式。TF32 的工作原理与 FP32 类似,但相较于上一代产品,TF32 可提供高达 20 倍的 AI 每秒浮点运算(FLOPS) 性能。
而最重要的是,实现此类加速无需改动任何代码。A100 80GB GPU 的 GPU 显存带宽比 A100 40GB GPU 增加了30%,以每秒超过 2 万亿字节的速度(2TB/s)达到全球领先水平。此外,与上一代 NVIDIA GPU 相比,A100 GPU 具有超大片内内存,包括 40 MB 的二级缓存,扩大近 7 倍,可更大限度地提升计算性能。
DGX A100 还推出第三代 NVIDIA®NVLink®,使 GPU 到 GPU 直接带宽提高一倍,直逼每秒 600 千兆字节(GB/s),几乎比 PCIe 4.0 高 10 倍。此外,新款NVIDIA NVSwitch™的速度是上一代的 2 倍。这种强大的性能可助力用户更快解决问题,以及应对此前无法解决的难题。
非凡的可扩展性
NVIDIA DGX A100 配备所有 DGX 系统中速度领先的 I/O 架构,是 NVIDIA DGX SuperPOD™等大型 AI 集群的基础构件。DGX A100 拥有8 个用于集群的单端口 NVIDIA ConnectX®-7 InfiniBand 网卡,以及最高 2 个用于存储和网络连接的双端口 ConnectX-7 VPI网卡,二者的速度均能达到 200 Gb/s。
将 ConnectX-7 与 NVIDIA Quantum-2 InfiniBand 交换机相连,即可用更少的交换机和线缆构建 DGX SuperPOD,从而节省数据中心基础设施的 CAPEX 和 OPEX。借助海量 GPU 加速计算与精尖网络硬件和软件优化的强强联合,DGX A100 可扩展至数百乃至数千个节点,从而攻克对话式 AI 和大规模图像分类等更艰巨的挑战。
总结

总而言之,NVIDIA DGX A100以其强大的算力、灵活的资源分配、优化的软件支持和卓越的可扩展性,也正因为这强大的算力才让它在AI行业有着如此地位。
如果你对AI算力方面感兴趣或者有需求的话,不妨点击链接https://www.houdeyun.cn进入厚德云官网看看!
厚德云是一款专业的AI算力云平台,为用户提供稳定、可靠、易用、省钱的GPU算力解决方案。海量GPU算力资源租用,就在厚德云。

这篇关于为何NVIDIA DGX A100在市面上如此抢手?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







