本文主要是介绍使用机器学习来测量基因间的相关性:一个多特征模型(Using Machine Learning to Measure Relatedness Between Genes),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 摘要
测量一对基因间的条件亲缘关系是计算生物学的一项基本技术,也是一个重大的挑战。论文提出了一个新的机器学习模型—多特征相关性(MFR),通过将表达相似度和基于先验知识的相似度纳入评估标准,来准确地测量一对基因之间的条件相关性。
2. 介绍
基因之间的相互作用通常被建模为一对基因之间0/1(非相互作用/相互作用)的二元关系,而亲缘性则意味着一对基因之间的某种程度的关系。
相关性可以通过两种特征来衡量:表达相似度和基于先验知识的相似度。第一种特性通常是在一定条件下测量一对基因的共表达水平,第二种类型的特征通常是使用公共生物数据和功能注释数据库来测量基因的相关性。
论文提出的机器学习模型MFR,通过使用带线性核的支持向量机,整合表达相似度和基于先验知识的相似度,保留并推荐具有高表达相似性和高先验知识相似性的基因对,准确地测量基因间的条件相关性。
3. 材料和方法
3.1 MFR工作流程
如图1所示,MFR工作流程有5个步骤:
(i)从已发表的研究成果中收集基因对样本;
(ii)从GEO、GO和orthoDB数据库中提取基因特征,用于评估基于相似性的基因对功能;
(iii)利用4个基因特征和反应体数据库和HTRIdb数据库计算12个基于相似性的基因对特征
(iv)通过10倍交叉验证构建基于svm的模型。
(v)实验验证基因-基因相互作用,预测基因功能,并与其他模型和方法进行比较。
3.2 基因特征
MFR使用12个相似的基因对特征来评估一对基因之间的条件相关性。
表达数据。使用GEO数据库中的15679个样本作为表达数据源,进行预处理步骤,最终保留16,391个编码蛋白的基因,以供进一步的表达数据分析。
基因本体论数据。 GO注释使用GO数据库(共435975)中43340个与实验相关的生物学过程。
相应的数据。使用了5000多个物种的2200万个基因,其中包括20个物种的169376个人类同源基因。
亚细胞定位数据。从GO数据库中获得的人类基因的160537个细胞成分注释被用作亚细胞源来衡量一对基因之间亚细胞定位的相似性。
3.3 基因对特征计算
MFR中使用了12个基于相似性的基因对特征,定义如下。
7个基于表达相似性的特征:每个基因exp1和exp2的平均表达水平,PCC度量的线性共表达关系,SRC和MI用于测量的非线性共表达关系,MI度量的两个基因表达水平的联合分布与因子边际分布的产物相似性。
GO相似性(goSim),因为相互作用的基因被认为参与了类似的生物过程:
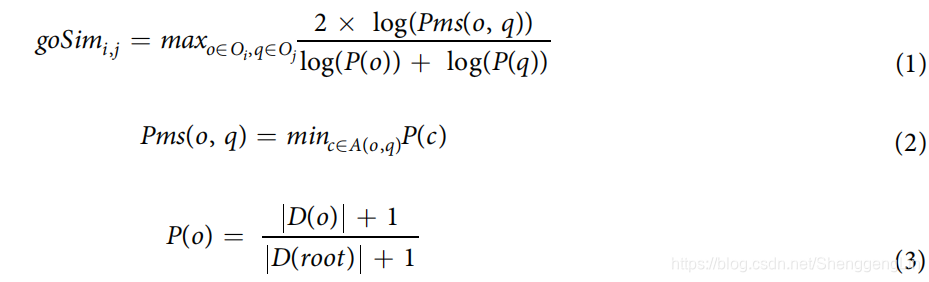
其中,Oi和Oj分别表示用于注释基因i和j的GO项集;A(o, q)是GO项o和q的共同祖先集;P(o)为GO项o实例注释的一个基因的概率;D(o)和D(root)分别表示GO项o的后代GO项集和根GO项集。
亚细胞定位相似度(lcSim),用来计算两个蛋白质编码基因出现在一个普通细胞器中的概率:

其中Li和Lj是由基因i和j编码的亚细胞定位组。
同源相似性(hgSim),使用改进的皮尔逊相关方法:

其中,ni和nj分别为基因组中包含i和j基因同源基因的物种数目;N =21 是我们使用的物种 的总数和,M为基因组中同时包含i和j基因同源基因的物种数量。
基因对的归一化距离(rxSim),从反应体途径得到的202772个基因-基因相互作用被用来构建一个未加权图,其中节点表示基因,边表示基因之间的相互作用:

其中disi,j为基因i与j之间的最短距离,dismax为图中最远的一对基因之间的最短距离。
基于转录调控相似度(trSim),如果有一个基因对有转录调控相互作用的记录,trSim为1,否则为0。
3.4 支持向量机模型
由于文章在服务器上,全文详见:
http://bbit.vip/service/main.php?version=1&type=article&id=87
这篇关于使用机器学习来测量基因间的相关性:一个多特征模型(Using Machine Learning to Measure Relatedness Between Genes)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







