本文主要是介绍极大缩短resnet训练时间并达到极高准确率的一些tricks,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1、模型复杂度与泛化能力的关系
- 2、DAWNBench
- 3、Some Tricks
- 4、实验效果
- 5、展望
1、模型复杂度与泛化能力的关系
例如对于VGG而言,有11,13,16,19四种深度的模型对应着四种不同的模型复杂度,当然层数越多模型越复杂。大部分人一开始肯定会觉得模型越复杂它所具有的函数拟合能力越强,肯定效果会更好,理论上应该是这样的。但是对于那些追求极致泛化能力的人做了很多实验,发现可能这个结论并不是那么绝对,比如下面这张图
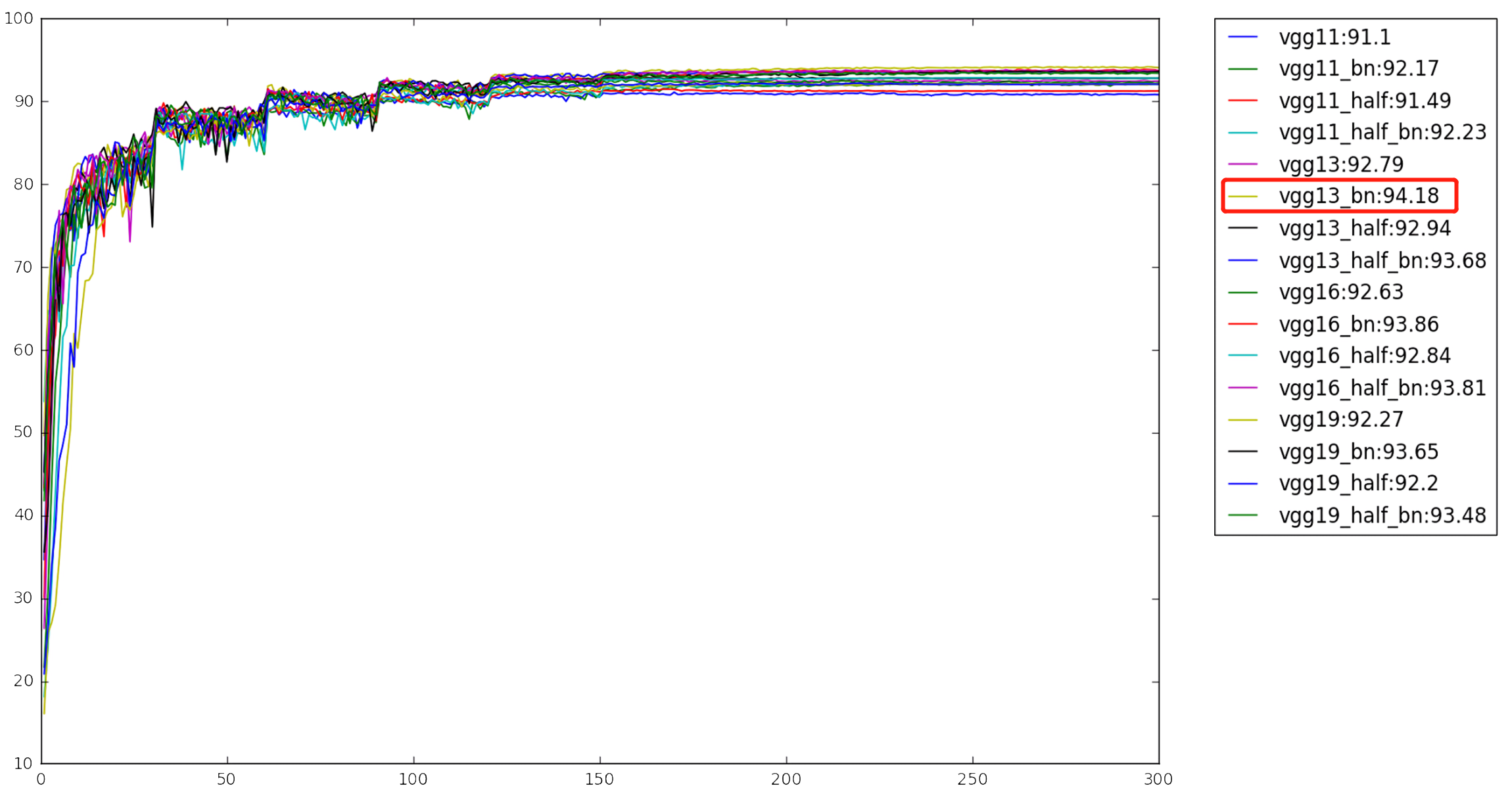
用VGG训练CIFAR-10达到94%的准确率已经很高了,但是这个最大值并不是出现在VGG19而是VGG13。
2、DAWNBench
斯坦福大学提出了DAWNbench,它是一种用于端到端深度学习的基准,用于在不同的优化策略、模型架构、软件框架、云和硬件条件下量化训练时间、训练成本、推理延迟和推理成本。下面我们主要来关注一下各路大神对于CIFAR-10数据集的效果
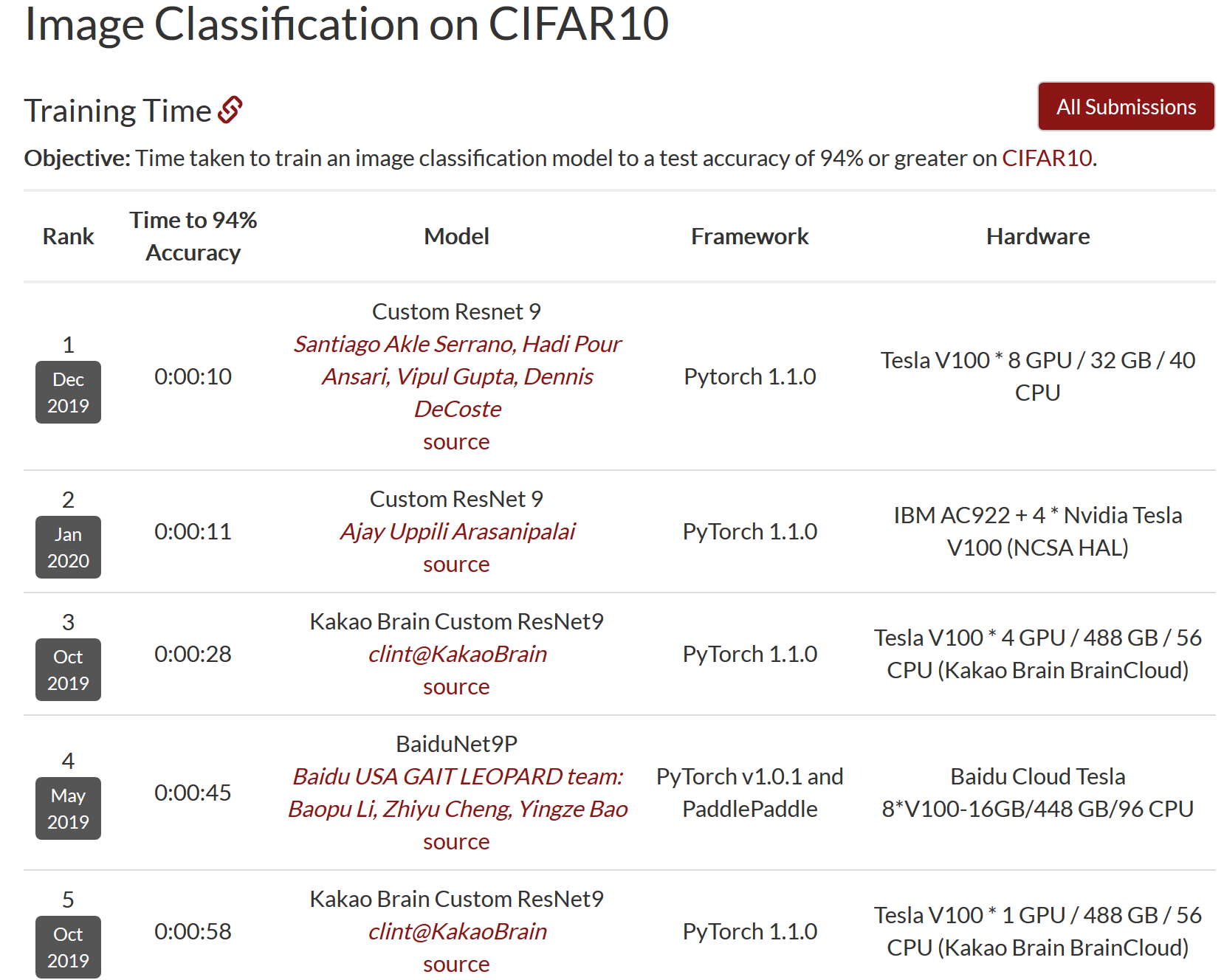
第一名用了10s就将CIFAR-10的准确率训练到了94%以上,很惊人的结果。当然现阶段硬件上和别人是有差距的,他们用了8块TeslaV100,而我们现在用的云服务器只有1块TeslaM40,但是依然可以从这个结果上发现很多我们可以利用的地方。
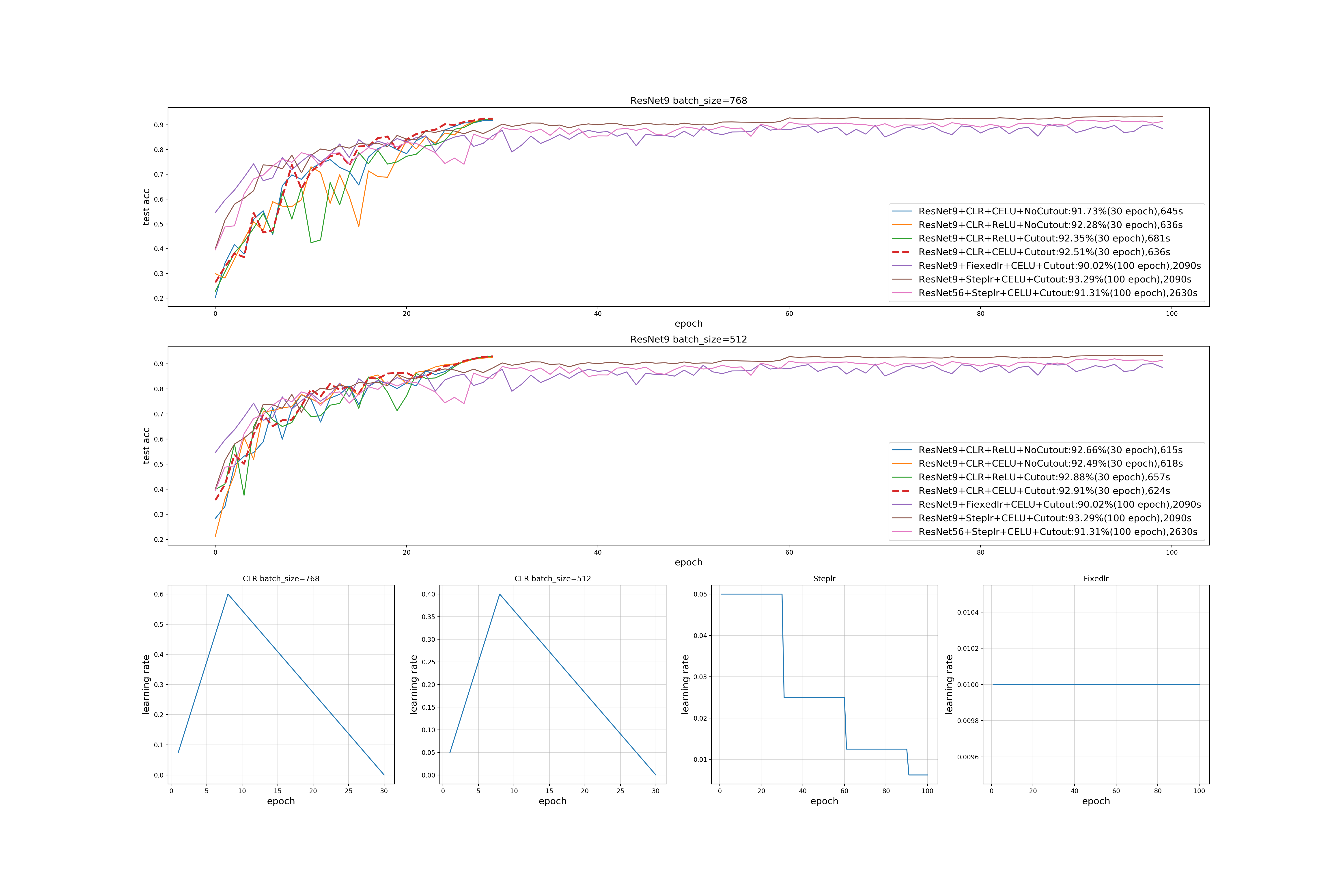
- 我们知道ResNet也有很多种(18,50,101…),但是他们这里用的是比原作者提出的最小的模型还要小的一个模型,其中一个参赛者提出的具体模型架构如下图(将下图保存在自己电脑上可以查看具体每一层的参数设置)。仅仅使用9层就达到了我自己之前做ResNet作业56层都达不到的一个效果。

- 硬件虽然达不到别人的要求但是我们可以从他们的代码中学到一些快速训练的tricks,例如在他们训练中都用到了Cycle Learning Rate、大batch_size(512,768)、ReLU换成CELU、数据增强用到了Cutout…后面会展示实验对比。
3、Some Tricks
- CLR(Cycle Learning Rate)第一次提出是在2017年的一篇WACV上,这个想法还是很新颖的。

我们最开始接触深度学习的时候设置学习率可能会默认SGD设置为0.01,Adam设置为0.001;到了后来学的东西多了了解了一些scheduler可能就是从一个较大的lr开始随着epoch开始分段递减。但是这个文章给出了一种循环设置学习率的思想,他将学习率设置为周期变化,由小变大再由大变小,如下图所示
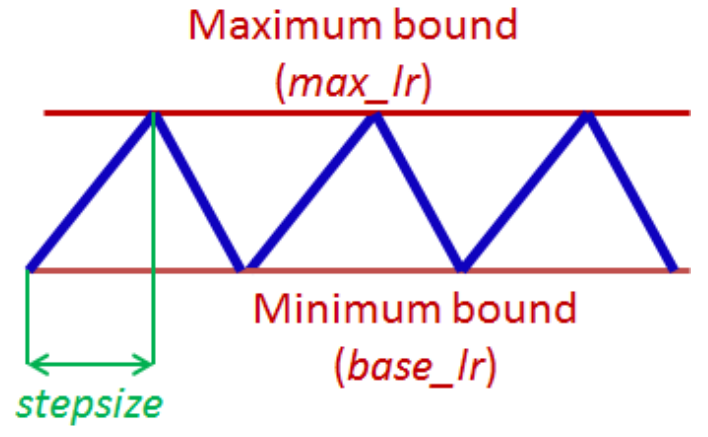
我自己复现了一下发现效果是有的,但是精度上不去很高,不过也有可能是因为我没有太理解作者这篇文章中三个超参数(max_lr,base_lr,stepsize)的设置方法,就不了了之了。
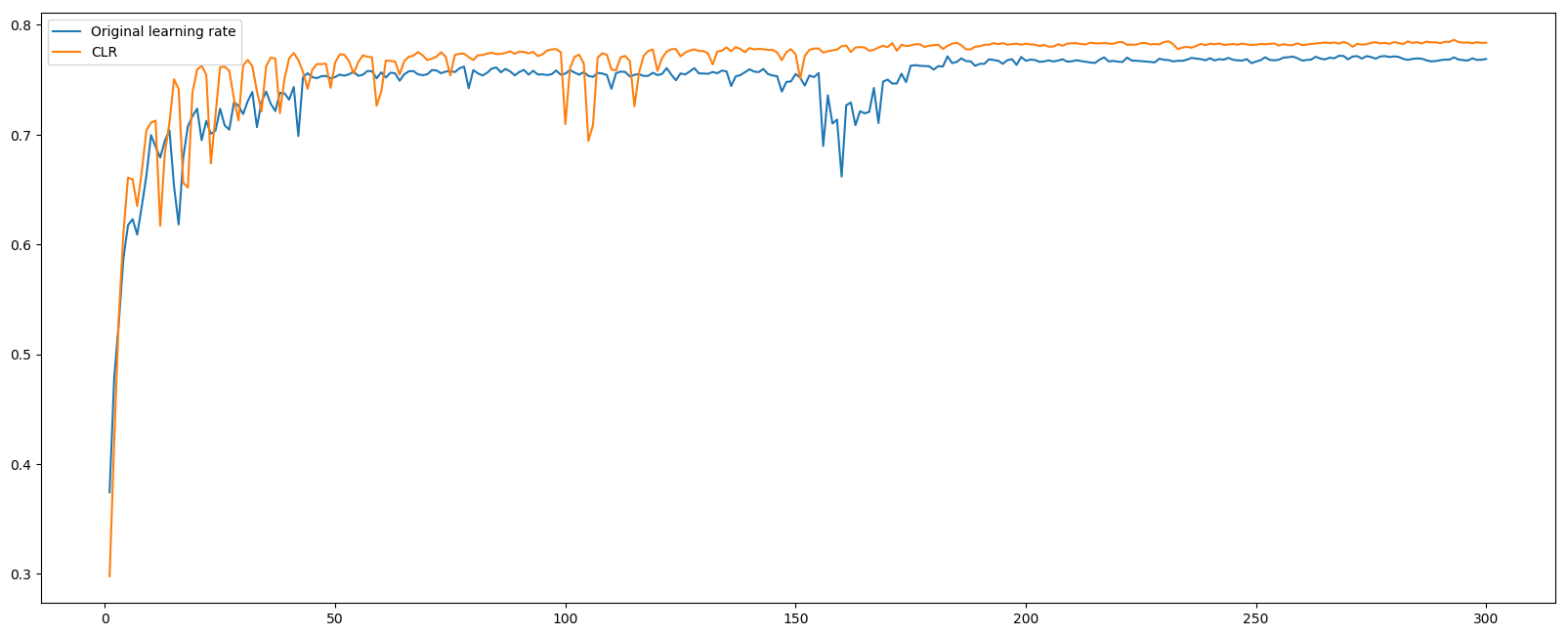
但是后来看到DAWNBench的各路大神们也用到了这个方法,就再一次聚焦到这个方法。但是有所不同的是DAWNBench里面用到这个方法没有让它循环很多次,而是一上一下就结束了(在后面的复现结果中会有展示)。
- 用到CLR就会发现,max_lr设置的很大,所以致使batch_size很大(512,786),自己做实验最大设置过128,没想过这么大的batch_size。而且如果GPU核数够大batch_size越大时间越小,但是现在我们用的效果不明显因为已经超过最大负荷了,所以时间都一样,都是要排队的。
- 将线性修正单元ReLU改为CELU,ReLU分段都是线性有折点,而CELU是全程非线性的并且无折点。
- 数据增强用到了pytorch中不自带的Cutout功能,随机将一张图片的一小部分”遮挡“,需要自己写函数完成。
4、实验效果
- 实验结果显示出有很大提升,之前完成VGG和ResNet作业跑100-300 epochs(快的话1-2 hours)才能达到的效果,运用上述方法在30 epochs(10 min)之内便可以达到93%左右的精度,并且如果GPU性能更好,在时间上节省会更多。
- 在实验设置上比较了四种学习率的设置,第一个是应对768 batchsize的CLR学习率设置,第二个是应对512 batchsize的CLR学习率设置,第三个是我自己之前一直用的效果也很好的每三十个回合学习率减半的设置,第四个是最普通的恒定学习率。模型上对比了ResNet9和ResNet56的收敛时间。也对比了trick之间的影响。
5、展望
- 其实最近也在学习apex进行精度混合训练,将pytorch默认的32位运算变成16位和32位自动混合运算,精度不会下降很多但是可以极大减小训练时间,并且显存也能降低。但是现阶段云端服务器不支持tensorcore,希望疫情过后早日回归大家庭,冲冲冲!
这篇关于极大缩短resnet训练时间并达到极高准确率的一些tricks的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




