本文主要是介绍论文解读---一种基于半脑不对称性的脑电情绪识别神经网络模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文地址:A Novel Neural Network Model based on Cerebral Hemispheric Asymmetry for EEG Emotion Recognition
本文解读的是一篇发表于IJCAI-18的论文,文章提出了一种新的深度神经网络模型-BiDANN模型,该模型考虑了训练和测试数据之间的分布差异和大脑左右半脑的不对称性,以处理两种常见的脑电情绪识别任务。文章在SEED数据集进行验证,达到了state-of-the-art的水平。
一、研究动机
源域(训练集)和目标域(测试集)数据分布存在较大的差异,主要体现在不同被试和同一被试在不同实验条件下采集的脑电信号之间。因此,我们应该找到一个特征表征空间,以减小源域和目标域的数据分布差异。
虽然人类大脑的解剖结构看起来是对称的,但左右半脑并不完全对称,其在结构和功能上均存在差异性。因此,从神经科学的角度看,在脑电情绪识别模型的构建中,考虑大脑的本质或特征对于情绪识别更有价值。
二、网络结构及思想
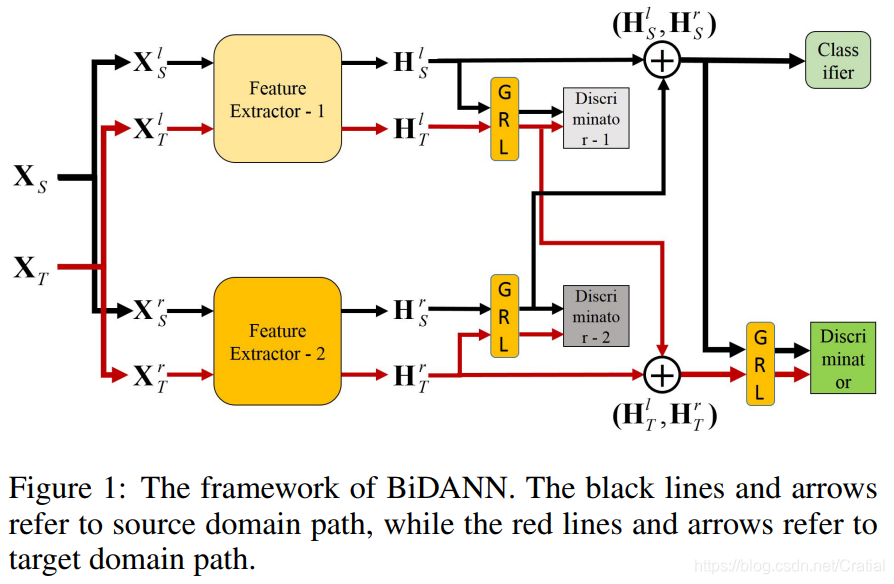
从上述两个研究动机出发,作者提出了一种叫做双半球领域对抗性神经网络(bi-hemispheres domain adversarial neural network, BiDANN)用于脑电情绪识别。BiDANN的基本思想是将左右半脑的脑电图数据分别映射到判别特征空间中,使数据表示易于分类。为了进一步精确地预测测试数据的类标签,文章使用了一个全局和两个局部域判别器来缩小训练和测试数据之间的分布差异。
2.1 网络主要结构
特征提取器(Feature Extractor):该网络包含两个特征提取器,分别用于学习大脑半脑的内部信息,将原始脑电图数据映射到具有更多识别性情感信息的深层特征空间。
分类器(Classifier):通过将特征映射到标签空间来预测情绪标签。
领域判别器(Discriminator):全局领域判别器用于区分输入来自哪个域(训练数据或测试数据),从而减小分布差异,两个半脑的局部判别器用于进一步缩小左右半脑源域和目标域脑电数据特征分布差异。
梯度反向层(gradient reversal layers, GRL)的作用是在网络正向传播时保持输入不变,在反向传播时将梯度乘以一个负标量,从而使判别器的损失最大化。
网络学习目标是对特征提取器的参数进行优化,以使分类器的损失最小,领域判别器的损失最大,这将产生分类器和领域判别器之间的对抗性学习,从而使网络学习到与情绪相关但与领域无关的判别信息。
BiDANN的目标函数
\begin{array}{l}{L\left(\mathbf{X}_{\mathcal{R}} ; \theta_{f}^{l}, \theta_{f}^{r}, \theta_{c}, \theta_{d}^{l}, \theta_{d}^{r}, \theta_{d}\right)=L_{c}\left(\mathbf{X}_{\mathcal{S}} ; \theta_{f}^{l},\theta_{f}^{r}, \theta_{c}\right)} \\ {\quad-L_{d}^{l}\left(\mathbf{X}_{\mathcal{R}}^{l} ; \theta_{f}^{l}, \theta_{d}^{l}\right)-L_{d}^{r}\left(\mathbf{X}_{\mathcal{R}}^{r} ; \theta_{f}^{r}, \theta_{d}^{r}\right)-L_{d}\left(\mathbf{X}_{\mathcal{R}} ; \theta_{f}^{l}, \theta_{f}^{r}, \theta_{d}\right) .(1)}\end{array}
这里\(\mathbf{X}\)表示电图序列。\(\mathcal{R} \in(\mathcal{S}, \mathcal{T})\),S, T分别表示源域和目标域。\(L_{c},L_{d}^{l},L_{d}^{r}\)和\(L_{d}\)是分类器、左右半脑局部判别器和全局判别器的损失函数,\(\theta_{c},\theta_{d}^{l},\theta_{d}^{r},\theta_{d}\)为相应的学习参数。\(\theta_{f}^{l}\)和\(\theta_{f}^{r}\)是左右半脑特征提取器的参数。l和r分别表示左右半脑。
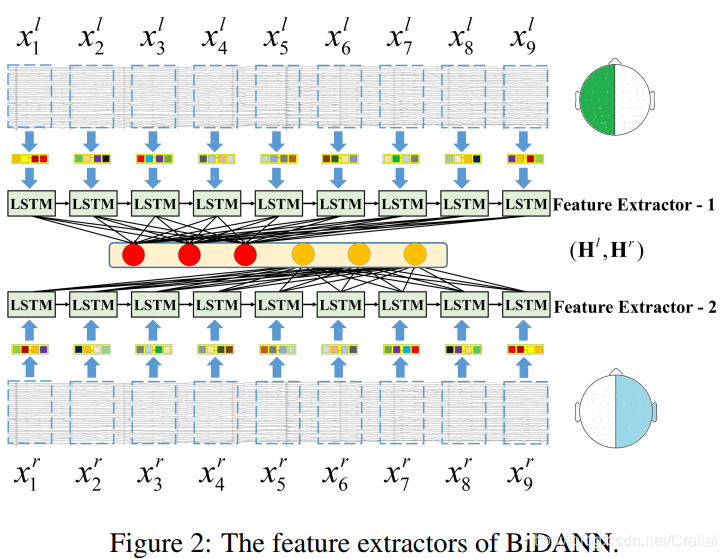
2.2 左右半脑特征提取过程
为了充分利用序列的时间依赖性,文章构造了一个长短时记忆(LSTM)框架来学习上下文信息,并将输入映射到另一个更有效的特征空间。具体描述如下:
设\(\mathbf{X}=\left\{\mathbf{x}_{1}, \cdots, \mathbf{x}_{t-1}, \mathbf{x}_{t}, \cdots, \mathbf{x}_{T}\right\} \in \mathbb{R}^{d_{x} \times T}\),其中\(d_{x}\)为序列的维数,T为序列的长度。t时刻的输入\(\mathbf{x}_{t} \in\mathbb{R}^{d_{x} \times 1}\)在隐层的输出为\(\mathbf{h}_{t}^{f}\in \mathbb{R}^{d_{h} \times 1}\),\(d_{h}\)表示隐层神经元个数。
对于LSTM隐层的输出序列,文章通过一个映射矩阵\(\mathbf{G}^{c}=\left[\boldsymbol{G}_{i k}^{c}\right]_{T \times K}\)将其映射到另一个压缩序列\(\mathbf{H}^{c}=\left\{\mathbf{h}_{1}^{c}, \cdots, \mathbf{h}_{k}^{c}, \cdots, \mathbf{h}_{K}^{c}\right\} \in \mathbb{R}^{d_{h} \times K}\),该序列即表示特征数据。
\begin{equation}
\mathbf{h}_{k}^{c}=\sigma\left(\sum_{i=1}^{T} G_{i k}^{c} \mathbf{h}_{i}^{f}+\mathbf{b}^{c}\right), k=1,2, \cdots, K
\end{equation}
2.3 BiDANN优化过程

分类器和各判别器的优化目标和涉及的优化参数
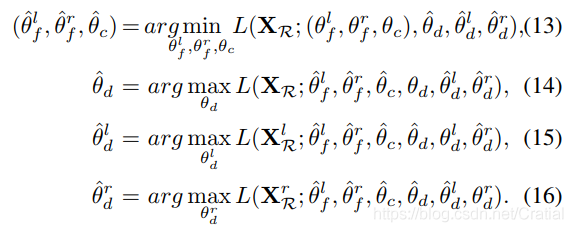
三、实验设计及结果分析
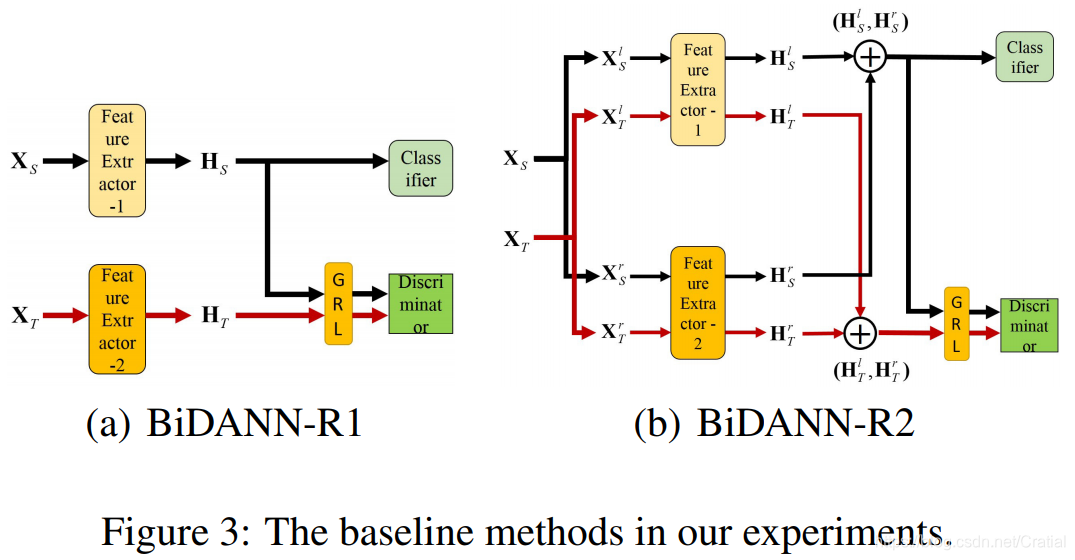
除了基准方法DANN[2]外,文章通过对BiDANN的变形设置了两个对比实验BiDANN-R1和BiDANN-R2。与BiDANN相比,BiDANN-R2减少了局部判别器,进一步,BiDANN-R1在提取源域和目标域特征时不再考虑左右半脑的数据分布差异。
作者在广泛用于脑电情绪识别研究的数据集SEED[3]上设置了两个实验:Conventional(subject-dependent)情绪识别实验和Personalized(subject-independent)情绪识别实验。输入数据\(\mathbf{X}=\left\{\mathbf{x}_{1}, \dots, \mathbf{x}_{i}, \ldots, \mathbf{x}_{T}\right\} \in \mathbb{R}^{d_{x} \times T}\),T=9, dx=310,\(\mathbf{X}_{\mathcal{S}}^{l}, \mathbf{X}_{\mathcal{S}}^{r}, \mathbf{X}_{\mathcal{T}}^{l}, \mathbf{X}_{\mathcal{T}}^{r} \in \mathbb{R}^{155 \times 9}\)
两种实验设置下,BiDANN均取得了最佳识别效果。
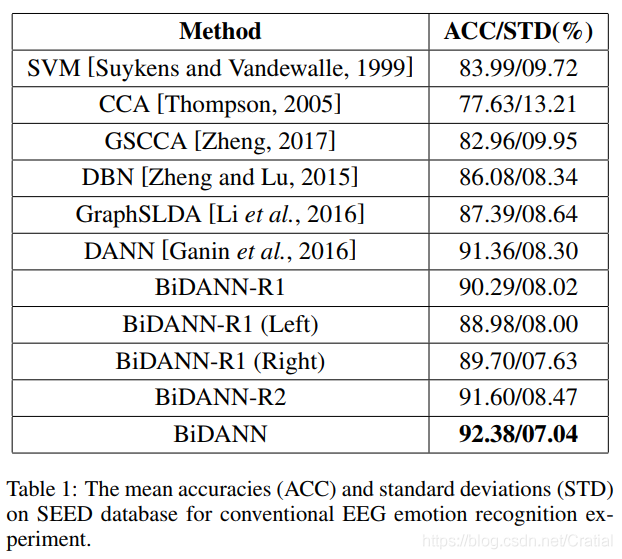
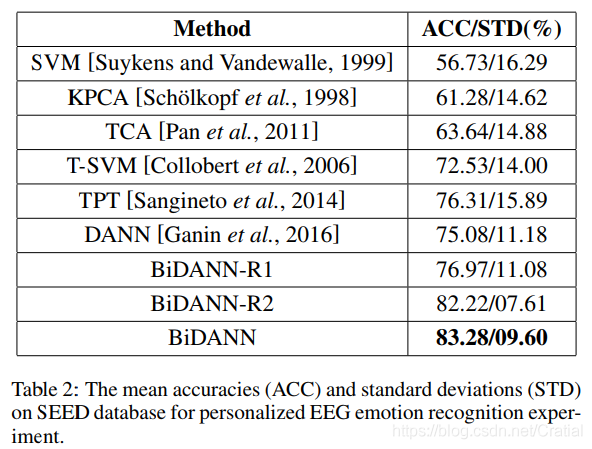
此外,从表1可以看出,使用右半脑数据进行识别的分类结果(BiDANN-R1(Right))比使用左半脑数据进行识别的分类精度(BiDANN-R1(Left))更好,说明右半脑在情绪识别过程中优于左半脑。
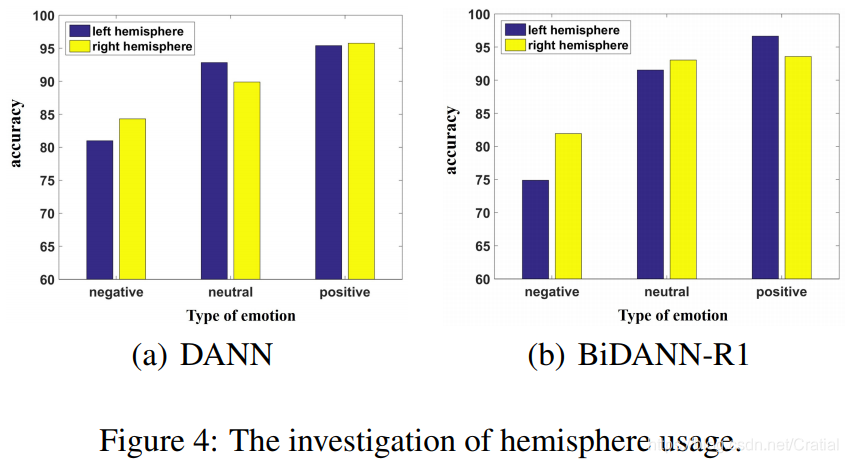
文章还使用DANN和BiDANN-R1方法研究了左右半脑对三种情绪识别的影响,并得到右半脑脑电信号有利于消极情绪识别,左半脑脑电信号有利于积极情绪识别的结论。
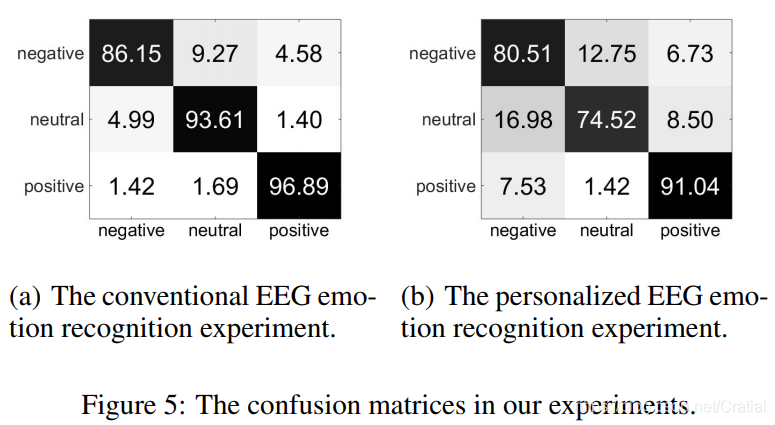
两种实验方法下BiDANN的混淆矩阵如下图,该网络对积极情绪的识别效果最好,消极情绪和中性情绪更容易发生混淆。
总结
文章的主要贡献为:
这是第一个在情绪识别研究中考虑左右半脑之间依赖关系的研究,并将神经科学关于大脑不对称的发现应用到深度学习模型中;
除了约束训练数据和测试数据之间的全局分布相似性外,文章还考虑了左右半脑的局部分布相关性。
不足之处:文章所用输入数据![]() (9s)比Zheng等人[3]所提方法中样本数据(1s)更长,可以考虑适当减小输入数据长度。
(9s)比Zheng等人[3]所提方法中样本数据(1s)更长,可以考虑适当减小输入数据长度。
参考文献
- Li Y, Zheng W, Cui Z, etal. A Novel Neural Network Model based on Cerebral Hemispheric Asymmetry for EEG Emotion Recognition[C]//IJCAI. 2018: 1561-1567.
- Ganin Y, Ustinova E, Ajakan H, et al. Domain-adversarial training of neural networks[J]. The Journal of Machine Learning Research, 2016, 17(1): 2096-2030.
- Zheng W L, Lu B L. Investigating critical frequency bands and channels for EEG-based emotion recognition with deep neural networks[J]. IEEE Transactions on Autonomous Mental Development, 2015, 7(3): 162-175.
更多与脑机接口和情绪识别相关的论文解读请访问专业论文解读与分享平台PaperWeekly.
这篇关于论文解读---一种基于半脑不对称性的脑电情绪识别神经网络模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







