本文主要是介绍语义分割综述A SURVEY ON DEEP LEARNING-BASED ARCHITECTURES FOR SEMANTIC SEGMENTATION ON 2D IMAGES,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
A SURVEY ON DEEP LEARNING-BASED ARCHITECTURES FOR SEMANTIC SEGMENTATION ON 2D IMAGES
https://arxiv.org/pdf/1912.10230.pdf
Irem Ulku
语义分割的一篇综述,了解下该领域。
语义分割的第一步是对每个pixel给予class label标注。
(这跟目标检测似乎很像。目标检测里面也是对每个方格进行分类吧,class1~n,留一个class0作为无对象)
CV里一项重要工作是在语义层面上理解一张图片包含了什么信息。
出于实际考虑,本文只讨论2-D图片上基于深度学习的语义分割工作。
同时检查(exam)为了解决该问题被提出的常见数据集。
同时回顾(review)一些现有的evaluate方法。
同时propose了一种能揭示现有不足、引领未来发展的分类法(taxonomy of methods)。
1. Introduction
1.1 Surveys on Semantic Segmentation
批评了一顿最近出来的该领域surveys。
它们一部分过度专注于specific task,若离开具体任务不谈,则并没有揭示该领域的未来方向问题。
另一部分提供了领域的一般性概论,但缺乏对基于深度学习方法的模型的分析深度,就是嫌你分析的太浅。
考虑到虽然20多年前就有人在搞语义分割,但是该领域真正有价值的发展是近年来尤其是全卷积FCN被提出来之后,而后续工作都可以看做是FCN的extension版本,所以如果想做该领域综述,不去细致分析FCN是“学术不严谨的”(lack the necessary academic rigour)。
而某些survey通常只在一小节里讨论这个,且为了凸显作者自己的contribution,对相关资料的分析犹为简洁,以免喧宾夺主。作者批这些survey根本不合格,夹带私货。
然后夸了一下“Alberto Garcia-Garcia, Sergio Orts-Escolano, Sergiu Oprea, Victor Villena-Martinez, and José García Rodríguez. A review on deep learning techniques applied to semantic segmentation. CoRR, abs/1704.06857, 2017.”这篇写的好。但是太早了,之后的成果没人总结。他就来了。
2
2.1图像数据集与挑战
深度学习大跃进后,特征不再为数据而构造,而是由数据来构造。于是数据集不再担任客体(object),而荣升为主体(subject)。
2-D数据集主要分为2大branch,其一为通用数据集,其二为面向无人驾驶定制的城市街景数据集(urban street image sets)。
如前言所述,本文排除了depth-based and 3D-based semantic segmantation datasets。
(查了一下depth-based,大概是指对图片中的物品进行深度区分,比如照片里有铅笔放在白纸上,我们可以认为白纸的深度大于铅笔,铅笔的Z轴更接近高层。这样本质是一种类3D视角,跟传统2D有所不同。)
通用数据集
1. PASCAL VOC(Visual Object Classes)系列
最早有PASCAL VOC 2005,后面扩展了一版PASCAL VOC 2010。此外还有很多衍生版本。
这个数据集对许多图像任务都有用,并非专为语义分割打造。
2.COCO (Common Objects in Context) http://cocodataset.org/
同上,入门必接触的就是PASCAL和COCO2家了。COCO相对来说更新更大。
3.其他数据集。
- YouTube-Objects数据集,主要由低分辨率 (480×360)视频快照和10k像素级别标注组成。
- SIFT-flow数据集,同样低分辨率(256×256),33个类别标签,2,688张图片。
这两个数据集与其他远古(primitive)数据集一样,都被现代智人抛弃了。因为规模太小,分辨率太低。
城市街景数据集
Cityscapes,摄影于超过50个城市,全天四季全覆盖,30种类别标签。既有pixel-level也有instance-level标注的challenge。超过100项条目(100-entries)可以挑战,是街景相关数据集中最受欢迎的。https://www.cityscapes-dataset.com/benchmarks/
其他数据集,如CamVid , KITTI , and SYNTHIA。
2.2 评价方法
主要有accuracy与Computational Complexity2种评价尺度。
Accuracy评价
1.ROC-AUC,适用于2分类任务,或者类别标签较为平衡时。但事实上现在的主流数据集类别标签并不平衡,因此被弃用。
2.Pixel Accuracy,又称global accuracy,简记PA,=真阳性数量/全部pixel数量。mPA则是在单类别里算PA后,再跨类别取均值。
3.Intersection over Union (IoU),又称Jaccard Index,交并比。这个是pixel-level的交并比,感觉算起来会比较费力,跟目标检测那边四个坐标减减加加就能算不同。同样的,还有单类别先算再取均值的mIOU。以及Frequency-weighted IOU,FwIOU,按类别的频次给予不同权重的加权均值。
4.PRC曲线相关,Precision-Recall Curve (PRC)-based metrics。精确度=真阳/(真阳+假阳),召回率=真阳/(真阳+假阴)。
- Fscore: Also known as the ‘dice coefficient’,精确率与召回率的调和平均(harmonic mean)。
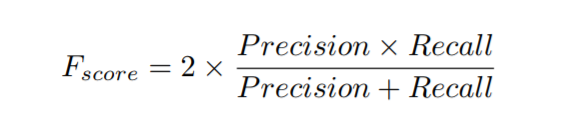
- PRC-AuC,PRC曲线下的面积。
- Average Precision (AP)。均匀摘取recall,提取相应precision,求均值。同样mAP是在单类别上这样操作后求均值。
In order to calculate AP, using the PRC, for uniformly sampled recall values (e.g., 0.0, 0.1, 0.2, ..., 1.0), precision values are recorded. The average of these precision values are referred to as the average precision. This is the most commonly used single value metric for semantic segmentation. Similarly, mean average precision (mAP) is the mean of the AP values, calculated on a per-class basis.
总的来说,IoU变种,与AP系列在语义分割里用的最多。
Computational Complexity评价
Execution time
Memory Usage
3.全卷积网络出来之前的历史
又可分为deep learning出来之前的历史,和早期DL历史。
3.1Pre-Deep Learning Approaches
语义分割和传统图像分割的最大区别在于,语言信息对过程起着重要作用。
传统分割法,例如二值化(thresholding)、聚类(clustering)、区域增长算法(Region growing,聚合灰度相等像素相连的区域),使用人工特征(边缘、气泡)来定位目标的边界。
这些传统方法遇到特殊场景,例如多物体互相重叠,效果就不行了。
早期的人们采用马可夫随机场MRF,或者条件随机场CRF,以及forest-based(又称‘holistic’)方法。
那个时期的主要思路是,通过观察相邻像素的依赖关系得到推论。
换句话说,这些远古模型将图片中的语义信息建模为邻接像素间的先验信息。(these methods modelled semantics of the image as a kind of ‘a priori’ information among adjacent pixels)
他们认为纯粹基于图像的方法有这种潜力,经常在论文里采用所谓的"超级像素化"(‘super-pixelisation)来建模abstract regions.
可惜在大数据集上,这些方法从来没有成功可行地实施过。
直到这个大数据集上的实施问题被deep CNN解决。
另一些工作,被称为“层次模型”('Layered models'),使用几个独立的预训练好的detectors组合,来提取图片中的语义信息。
这些模型,一方面受制于独立的detector本身性能瓶颈,另一方面因为手工挑选detector,能预测的class数量天然被这一篮子detector限定死了,与当今的sota模型一比,表现实在堪忧。
3.1.1补充:refinement 方法
所谓refinement就是后处理。
Deep CNN方法能很好的找出图中的local features,但却无法利用好全局context information,(and accordingly cannot model interactions between adjacent pixel predictions)。
与之相反,在CNN出来之前那些远古graphic models却精于此道。
因此,哪怕如今迈入DL时代,远古模型依然没有真正消失,而是退化成为Deep Learning网络里的一个后处理层。
作者配图能轻松理解。
图b是深度模型产出的结果,虽然能比较好地找出图中主体,对于主体与地面interact的部分却不能很好学到。

而图c是用CRF-based方法搞了后处理的结果,属于地面的部分就被干掉了。
一般而言,现在CRF-based后处理方法用的比较多,其他方法当然也存在。
3.2 Early Deep Learning Approaches
在2014年全卷积FCN出来之前。在ReLU被提出之前,早期神经网路一般用tanh或者其他类似的连续函数做激活函数,这使得计算相对不友好,尤其是大规模数据上。【注:FCN was officially published in 2017. However the same group first shared the idea online as pre-printed literature in 2014】
早期有些学者使用全连接层FC layers,不但效果差,运算还慢。
后来慢慢有人拒绝使用全连接,而是改用其他结构,比如RNN。
or using labelling from a family of separately computed segmentations。
经过多种替代FC的方案实验后,他们第一次感受到了应该找到一种类似后来问世的全卷积结构的必要性的蛛丝马迹。
【这就是所谓的,历史的必然性?】
所以毫不奇怪的,后来全卷积一出世就大获成功。
但由于他们的分割结果注定不会令人满意,当时的研究大量采用refinement处理。
现如今,refinement仍广泛被后全卷积(post-FCN)方法采纳,主要用于提高不同类别交界处的pixels的标签准确度。
4.全卷积在语义分割中的应用
在2017的这篇“Fully convolutional networks for semantic segmentation”(Evan Shelhamer)中,作者提出了拆除deep-CNN网络中的全连接层。
主要目标是将传统的分类网络如AlexNet,VGG等,转变为全卷积网络,然后将网络学到的特征表达进行fine-tuning。
插播备注,以AlexNet为例的分类网络,基本上是最后连一个全连接层Linear(input, num_classes),然后sigmoid或者softmax,进行分类。
由该文章产生的最知名的成果包括,‘FCN-32s’, ‘FCN16s’, and ‘FCN8s’,都是从VGG那边改过来的。
FCN的进步在于。
1)没有fc层,参数减少,全卷积,每张图片的推断速度快了。
2)分辨率制约解除。因为卷积层不关心输入与输出的尺寸问题。而通过 deconvolutional 与 upsample能把图片放缩到任意需要的分辨率。
3)引入了跳接,skip connections,或者说skip architectures。
跳接结构允许信息跨层流动,但信息也会被pooling、dropout这种结构抹消。
所以一般跳接加在池化层之前,先完成流动,再进行差别抹消。
池化的好处在于可以获得特征金字塔,缺点在于信息有损,比如一些位置信息(这些恰巧对分割任务非常重要)。
这点我在做关键点定位任务的时候也感受到了,在小尺度上进行预测,还原到大尺度的时候,除了*scale倍数,还需要预测个offset偏差,来补足位置信息的缺失。否则偏差,极大。
所以有时候可以利用跳接来部分补足池化之后更深layer缺失的信息。
这种指导思想,最终演变成了语义分割中的encoder-decoder结构,下文会详细介绍。
吐槽,encoder-decoder好多好多领域都有在用。这是搬运工把其他领域成果搬过来的缘故呢,还是本来诸多任务就存在客观的共性,存在某种共同规律?
5. 后全卷积道路 Post-FCN Approaches
(相对于methods译为'方法',这里的approaches应该是某一类方法的总称)
由于FCN问世后,后续工作基本是基于FCN产生的,所以可以比较严谨地说,在语义分割任务上,FCN的出现成功地终止了全连接层的存在。
另一方面,FCN系列的ideas也扩展了许多改进深度语义分割模型的机会。
综合而言,FCN的弊端在于。
1)在特征层次体系(feature hierarchy)中的位置信息损失。
2)无力处理全局情景信息 (global context knowledge)
3)缺乏多尺度处理能力 (个人观感而言,虽然全卷积不对输入图像作尺寸限制。但是对某次具体的训练任务而言,我们还是需要把所有输入图像,裁剪或缩放到相同的尺寸,不然都构不成一个batch。当然下一次训练就可以换尺寸了。但是本质上还是一次一种尺寸。)
故而后FCN时代,研究者们的工作基本围绕着这几个问题展开。
对这些issues的分析,我们会在下文"fine-grained localisatio"这个标题内展开。
在罗列sota methods之前,我们准备先把techniques分类,再分析一下解决这些issues的不同approaches。
之后我们还会讨论语义分割语境下的尺度不变性(scale invariance)。
最后以目标检测改进过来的模型(object detection-based approaches)收尾。
5.1 Techniques for Fine-grained Localisation
据定义,语义分割是一种dense procedure(密集过程?),所以对类别标签的精确定位有像素级的要求。
举例而言,在机器人手术中,像素级的误差可能会致人以死。
此外,由于pooling带来的定位信息损失,加之FCN本身对全局信息不敏感,定位显得尤为困难。
由于这两个问题天然的复杂,下文将分2段讨论一些解决方案。
5.1.1 Encoder-Decoder Architecture
简称ED,或称U-nets。
encoder逐渐减少维度,decoder则反之恢复维度。
每个decoder仅接受与自己同尺寸的encoder产物,运用跳接技术。
故而ED结构能较好地产生abstract hierarchical features(中文翻译过来别扭懂意思就行)。
U-Net与Seg-Net是两个很好的例子。
在这些结构中,从相邻的低分辨率layer传来的强相关语义信息,需要通过一些额外的中间层,才能抵达对应尺寸的decoder。
这通常会招致一定程度的信息延迟。(This usually results in a level of information decay.)
个人理解,这个decay说的是,走蓝线和红线的延迟。红线跳接显然更快。

然而实践却证明,U-Net在许多任务上表现良好,例如卫星图像处理。
5.1.2 SPP(Spatial Pyramid Pooling)
这个比上面的ED就更熟悉了,极度对称的ED结构现在用的少,而SPP还算常见。
CVPR2006 "Spatial pyramid matching for recognizing natural scene categories"这篇提出了构筑固定尺寸的空间金字塔,为了避免词袋系统(a Bag-of-Words system)丢失了特征间的位置依赖关系。
随后IEEE PAMI( IEEE Transactions on Pattern Analysis and Machine Intelligence)上的一篇"Spatial pyramid pooling in deep convolutional networks for visual recognition."引进了这种思想到CNN中, 构建了SPP-Net。
SPP解决了输入尺寸不统一的问题,无论输入是什么大小的图片,最终在决策层之前,加入一个池化层。
这个pooling采用适应性的stride,最终能把图片转化为固定尺寸。
说一下个人理解。
我见过的SPP代码是这样操作的,以out_channel作为新的size。
举例,无论是什么H,W的图片,经过一堆CNN之后,统一变成(H*,W*,256)。我们不在乎H*与W*是什么,我们只在乎outchannel一致。
然后经过一个maxpooling(),得到(1,1,256)。
flatten展开就变成一个(256)的一维特征向量,这样一来,最终产物与输入尺寸的确大不相干。
缺点在于,这个无脑的maxpooling到1x1,会损失很多信息。
所以通常SPP的outchannel会设的比较大,以尽量在不同channel上保留足够多的信息。
论文里的原配图看看就好,还是那句不懂的人看了也不懂,懂的不需要看。
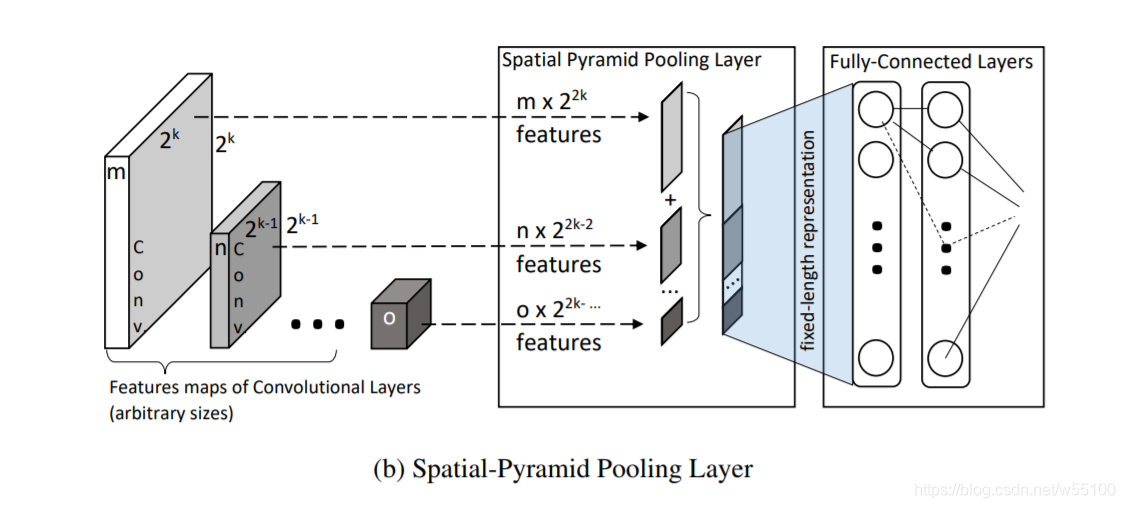
SPP并非一种真正的scale-invairance结构。虽然它看起来允许任意H*,W*图像作为输入。
实际上呢,如果训练集里含有不同分辨率图像,我们还是得把它们先缩放/裁剪到同一尺寸,才能作为模型输入。
也就是说,利用SPP我们至少稍微松弛了一点我们遇到的困难。
我们可以将图像统一缩放到某个我们自己喜欢的(H*,W*),而不必调整网络结构。
(放在有全连接层的Net里就不一样了,一旦调整H*,W*,全连接层的参数就得相应变动。)
这与我们真正追求的scale-invairance还有一定差距。
5.1.3 Feature Concatenation
特征拼接,或者说特征融合(feature fusion)。
举了2篇文章,‘DeepMask’和‘SharpMask’,都是用跳接把高层特征传给了前馈神经网络( feed-forward )。
后来又出现了 ‘ParseNet’,它把CNN产出的特征和其他全局特征拼在一起。
尽管理论上讲特征融合是个很novel的idea,但这些方法会导致混合结构,所以训练起来比较难。
5.1.4 空洞卷积Dilated Convolution
增加卷积的范围。卷积核不再是实心矩阵,而是稀疏矩阵。
有个很形象的比喻就是“花洒”。 (想到如月雨露...)
空洞卷积在语义分割领域被提出被运用,为解决语义分割问题而生,其他领域似乎见的比较少。
传统的连续性卷积核的感受视野是线性增长的,(经过k层后增加O(k))
而带孔的空洞卷积核的感受视野是指数增长的。
相应的,对GPU容量的要求和算力要求都大大提高。
5.1.5 CRF Conditional Random Fields
前文已经说过,CRF系列现在主要作为refinement用。
5.1.6 Recurrent Approaches
部分采用RNN结构的工作。借助RNN对短期信息的处理能力,更好地做精细分割。
(以个人视角来看这个方向不是很主流。)
5.2 Scale-Invariance
Scale-Invariance,一般叫尺寸不变性。
其定义含2部分,一是模型的工作不依赖于input图像的分辨率,二是模型的工作不依赖于目标物体相对原图的 relative scale(相对尺寸)。
同时满足这两点才是真正的"尺寸不变"。
前者似乎在FCN结构中已经近乎被攻克,虽然train的时候需要统一batch内的分辨率,infer时却可以一张一张来,完全不需要考虑分辨率。
后者似乎还很棘手,我们对图像中占据面积较大的主要目标的检测性能良好,小目标物体却无法被准确识别。
然而事实上,前者也并没有被完全解决。
目前主流的数据集使用的图像都具有较大的scale,
在主流数据集上跑出来的模型,如果喂一些小分辨率图片,性能又会不尽人意。
如此一来,严格地说模型还是依赖于输入图像的分辨率。
个人补充。常见数据集里,比如汽车、人等主要目标,会占据100x100pixel,60x60pixel这类scale的区域。
但是对于一些15x15pixel的易拉罐,远处空中的飞鸟,就很难检测到。
这种scale既与image_shape相关,又不相关。
2000x3000的图片,也可以有15x15的人影。
但总体而言,largescale的image,总是更容易有largescale的object。
5.3 Object Detection-based Methods
以目标检测的方法为基础做的模型。
这个领域最著名的先驱者RCNN(Regions with CNN features)。
早期结构的缺陷在于,很难正确知道一张图片中应该检测出多少个目标。(detect an unknown number of images within an image)
最简单的解决方案,就是先生成许多RoI(region of interest 感兴趣区域,不是投资报酬率。。)
之后再依次于每个RoI中依次应用CNN检测目标。
回顾上述过程,可以更深刻的理解到,目前的CNN多是单输入单输出的单线模型。
我们将选择RoI的结构称为RPN(Region Proposal Network)。
后续工作包括Fast-RCNN,Faster-RCNN,Mask-RCNN等。
RCNN系列的网络们,通常包含RPN,以及用来确定class与bbox位置(bounding box positions)的全连接层。
但我们上文又做过讨论,繁复冗杂的全连接层基本被FCN抛弃了。
RCNN也遭遇了类似的命运,被不使用全连接层的YOLO系列,以及SSD(Single Shot Detector)干掉了。
原文对SSD的全称是Single Shot Detector,但我了解到的SSD那篇论文应该是15年出的含Multibox的,即Single Shot Multibox Detector, https://arxiv.org/abs/1512.02325
YOLO系列不采用全连接层,直接用一个CNN就完成了类别概率预测,和bbox位置预测,所以能做到real-time。
SSD也类似的,在很多卷积层之后预测bbox。
速度上YOLO>SSD>RCNN。
经过类似的思想,后面产生了'Mask-YOLO','YOLACT'等实例分割的模型。
比如2019的最新工作YOLACT(You Only Look At CoefficienTs),https://arxiv.org/abs/1904.02689
直接在YOLO后面接

作者认为在语义分割之前,先找出图中有哪几个目标,是很符合直觉的很自然的事情。
所以看好在语义分割领域引入目标检测领域的一些模型方法。
5.4 Proposed Methods
本节介绍一些sota模型。
我看的时候偶然发现有人已经翻译好了。。。
借用@grayondream的翻译成果。
https://blog.csdn.net/GrayOnDream/article/details/103845647
| 方法 | 模型总结 | 分割类别 | 后处理 |
|---|---|---|---|
| Hier. Feat | 多尺度卷积网络与分割框架(超像素或基于CRF)并行融合。 | Object | “Parallel” CRF [55] |
| Recurr. CNN | 通过使用CNN的不同实例构建的递归体系结构,其中,每个网络实例都具有先前的标签预测(从先前的实例获得)。 | Object | None |
| FCN | 具有跳过连接的完全卷积编码器结构(即没有完全连接的层),可在最终决策层融合多尺度激活。 | Object | None |
| DeepLab.v1 | 具有扩张卷积的CNN,其后是完全连接的CRF(即密集的CRF)。 | Object | Dense CRF[42] |
| CMSA | 金字塔形输入的层被馈送到并行的不同比例的单独FCN。 这些多尺度FCN也串联连接,以同时提供按像素分类,深度和法向输出。 | Object | None |
| U-Net | 具有跳过连接的编码器/解码器结构,这些连接连接相同级别的ED和最终输入大小的分类层。 | Object | None |
| Seg-Net | 具有仅传输池索引的跳过连接的编码器/解码器结构(类似于U-Net)(与U-Net不同,跳过连接将同级激活串联在一起)。 | Object | None |
| DeconvNet | 编码器/解码器结构(即“转换/解码网络”),无需跳过连接。 网络的编码器(卷积)部分是从VGG-VD-16L [59]传输的。 | Object | None |
| MSCG | 仅使用膨胀卷积层的直角棱镜而不进行池化或二次采样层的多尺度上下文聚合,以执行像素级标记。 | Object | None |
| CRF-as-RNN | 全卷积CNN(即FCN),然后是CRF-as-RNN层,其中将迭代CRF算法表述为RNN。 | Object | CRF-as-RNN [73] |
| FeatMap-Net | 输入到并行多尺度特征图(即CNNS)的金字塔输入的各层,然后融合在上采样/串联层中,以提供最终的特征图,馈入密集的CRF层。 | Object | Dense CRF [42] |
| DeepLab.v2 | DeepLab.v1的改进版本,带有附加的“扩张的(无用的)空间金字塔池”(ASPP)层。 | Object | Dense CRF [42] |
| PSPNet | CNN之后是类似于[67]的金字塔池层,但没有完全连接的决策层。 | Object | None |
| DeepLab.v3 | DeepLab.v2的改进版本,具有ASPP层超参数的优化,并且没有密集的CRF层,可实现更快的操作。 | Object | None |
| DIS | 一个网络预测标签映射/标签,而另一个网络使用这些预测执行语义分割。 两个网络都使用ResNet101 [71]进行初步特征提取。 | Object | None |
| Mask-RCNN | 对象检测器快速RCNN,后跟ROI池和卷积层,应用于实例分割(见图5.a)。 | Instance | None |
| GCN | 由最初的基于ResNet的[71]编码器提供支持,GCN使用大型内核以多尺度的方式融合高级和低级功能,然后是卷积边界细化(BR)模块。 | Object | Conv. BR Module [95] |
| DFN | 由两个子网组成:平滑网(SN)和边界网(BN)。 SN使用注意模块并处理全局上下文,而BN使用提炼块处理边界。 | Object | Refin. Resid. Block (RRB) [96] |
| MSCI | 通过长短期记忆(LSTM)链之间的连接来聚合来自不同比例的要素。 | Object | None |
| DeepLab.v3+ | DeepLab.v3的改进版本,使用具有扩展卷积的特殊编码器-解码器结构(不使用Dense CRF来加快操作速度)。 | Object | None |
| HPN | 紧随其后的是卷积的“外观特征编码器”,由LSTM组成的“上下文特征编码器”会生成超像素特征,并馈入基于Softmax的分类层。 | Object | None |
| EncNet | 提取上下文的完全连接结构由密集特征图(从ResNet [71]获得)提供,然后是卷积预测层。 | Object | None |
| PSANet | 使用两个卷积结构之间的注意模块,像素通过自适应学习的注意图相互连接以提供全局上下文。 | Object | None |
| ExFuse | GCN [95]的改进版本,用于特征融合,它将更多的语义信息引入低级特征,并将更多的空间细节引入高级特征。 | Object | Conv. BR Module [95] |
| EMANet152 | 两个CNN结构之间的新型注意模块将输入特征图转换为输出特征图,从而提供全局上下文。 | Object | None |
| KSAC | 允许不同接受域的分支共享同一内核,以促进分支之间的通信并在网络内部执行功能增强。 | Object | None |
| CFNet | 使用图像中给定目标的并发特征分布,可以学习细粒度的空间不变表示,并构造CFNet。 | Object | None |
| SDN | 由多个称为SDN单元的浅层反卷积网络组成,它们逐一堆叠以集成上下文信息并确保本地信息的良好恢复。 | Object | None |
| YOLACT | 对象检测器YOLO后跟类概率和卷积层,应用于实例分割(请参见图5.b)。 | Instance | None |
因为名字比较好听,我去看了一下这个YOLACT,真是简单暴力又实用。
看懂核心思想之后大喊nb。
一组mask+对应(-1,1)的系数,线性叠加。
这不是PhotoShop里的图层正片叠底模式混合?
准确度不高,胜在速度够快。
这篇关于语义分割综述A SURVEY ON DEEP LEARNING-BASED ARCHITECTURES FOR SEMANTIC SEGMENTATION ON 2D IMAGES的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





