architectures专题

翻译论文的关键部分 | Parallel Tiled QR Factorization for Multicore Architectures
SSRFB DTSQT2 DLARFB DGEQT2 1, 对角子矩阵分解 DGEQT2 这个例程被开发出来,用于针对对角Tile子矩阵: ,执行不分块的QR分解。 这个运算产生: 一个上三角矩阵 一个酉下三角矩阵,这个矩阵包含 b 个 Householder 反光面、 一个上三角矩阵 ,在WY技术中,这个矩阵被定义用来累计Householder变换。 和 能够写进 所占据的内存空间,

Architecture,Valid architectures,Build Active Architecture Only
目前ios的指令集有以下几种: armv6 iPhone iPhone2 iPhone3G 第一代和第二代iPod Touch armv7 iPhone4 iPhone4S armv7s iPhone5 iPhone5C arm64 iPhone5S 机器对指令集的支持是向下兼容的,因此armv7的指令集是可以运行在iphone5S的,只是效率没那么高而已~ ===

RNN学习笔记:Understanding Deep Architectures using a Recursive Convolutional Network
reference link:http://blog.csdn.net/whiteinblue/article/details/43451383 本文是纽约大学Yann LeCun团队中Pierre Sermanet ,David Eigen和张翔等在13年撰写的一篇论文,本文改进了Alex-net,并用图像缩放和滑窗方法在test数据集上测试网络;提出了一种图像定位的方法;最后通过一个

Pods was rejected as an implicit dependency for 'libPods.a' because its architectures 'x86_64' didn'
引入cocoaPods后,第一次编译报这个错误 Pods was rejected as an implicit dependency for 'libPods.a' because its architectures 'x86_64' didn't contain all required architectures 'i386' 查了些资料,在网上有一种解决方法是去设置pod工程的 v

isscc2024 short course4 In-memory Computing Architectures
新兴的ML加速器方法:内存计算架构 1. 概述 内存计算(In-memory Computing)架构是一种新兴的机器学习加速器方法,通过将计算能力集成到存储器中,以减少数据移动的延迟和能耗,从而提高计算效率和性能。这种方法特别适用于需要大量数据处理的深度学习任务。 出现存内计算的原因 IMC与数字电路的优势 2. 内存计算的优势 减少数据移动:在传统计算架构中,数据在处理器和

Lightweight Enterprise Architectures
版权声明:原创作品,允许转载,转载时请务必以超链接形式标明文章原始出版、作者信息和本声明。否则将追究法律责任。 http://blog.csdn.net/topmvp - topmvp This book provides a methodology and philosophy that organizations can easily adopt without the pitfalls
Wireless Mesh Networking: Architectures, Protocols and Standards
版权声明:原创作品,允许转载,转载时请务必以超链接形式标明文章原始出版、作者信息和本声明。否则将追究法律责任。 http://blog.csdn.net/topmvp - topmvp This is the first book to provide readers a comprehensive technical guide covering recent and open issues
Broadband Network Architectures: Designing and Deploying Triple-Play Services
版权声明:原创作品,允许转载,转载时请务必以超链接形式标明文章原始出版、作者信息和本声明。否则将追究法律责任。 http://blog.csdn.net/topmvp - topmvp *An in-depth introduction to next-generation triple-play services: components, integration, and business
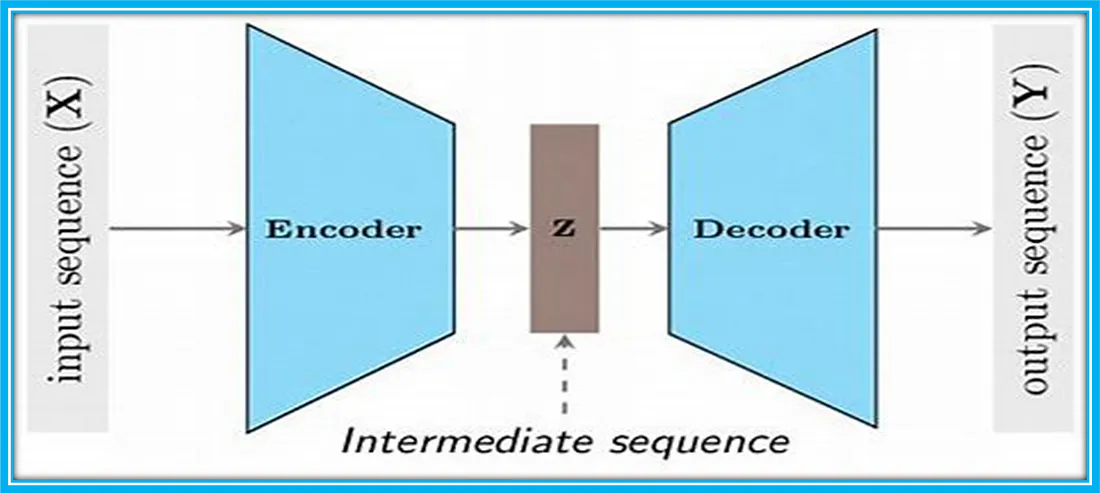
深度学习体系结构——CNN, RNN, GAN, Transformers, Encoder-Decoder Architectures算法原理与应用
1. 卷积神经网络 卷积神经网络(CNN)是一种特别适用于处理具有网格结构的数据,如图像和视频的人工神经网络。可以将其视作一个由多层过滤器构成的系统,这些过滤器能够处理图像并从中提取出有助于进行预测的有意义特征。 设想你手头有一张手写数字的照片,你希望计算机能够识别出这个数字。CNN的工作原理是在图像上逐层应用一系列过滤器,每一层都能够提取出从简单到复杂的不同特征。初级过滤器负责识别图像中的基

IOS No architectures to compile for (ARCHS=i386, VALID_ARCHS=armv6 armv7)错误
我在xCode4.0版本上写了一个程序,然后觉得4.0运行太慢了,装了xCode4.2版本,在4.2版本上运行程序 报了一个:No architectures to compile for (ARCHS=i386, VALID_ARCHS=armv6 armv7)的错误。 上网上搜了下, 解决方法如下: 在Bulid Settings选项下
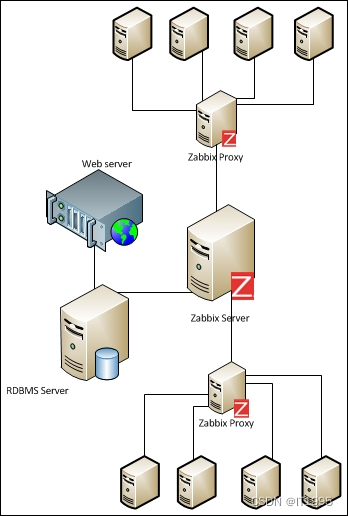
Zabbix文档阅读笔记-Zabbix architectures
Zabbix是一个分布式监控系统,这个系统使用集中式Web界面。他主要特点如下: Zabbix有一个集中式web管理页面;服务端能在大多数Linux、Unix操作系统上运行;监控系统的本地代理可以在Unix、Linux、Windows操作系统上运行;Zabbix很容易和其他系统进行集成,Zabbix提供了不同语言的API;Zabbix可使用SNMP(v1,v2,v3)、IPMI、JMX、ODBC

机器学习-Learning Deep Architectures for AI -1
随着计算机信息的发展,希望用计算机来model真实的物理过程,为了更精确地分析物理过程,计算机中关于物理过程的输入信息越多越好。让计算机储存/读取物理过程的所有信息是及其艰巨的,因此使用learning algorithm来不断学习获取物理过程的大部分有用信息。 人工智能方面,寻找合适的学习算法是最大的挑战。 我们假设为了表达复杂的物理过程,需要非常复杂的数学模型,例如高度非线性。面对非常复杂

【读点论文】MobileDets: Searching for Object Detection Architectures for Mobile Accelerators,适配不同硬件平台的搜索方案
MobileDets: Searching for Object Detection Architectures for Mobile Accelerators Abstract 建立在深度方向卷积上的反向瓶颈层已经成为移动设备上的最新对象检测模型中的主要构件。在这项工作中,本文通过重新考察常规卷积的有效性,研究了这种设计模式在各种移动加速器上的最优性。本文发现,常规卷积是一个有效的组件,可以
Beyond Hadoop: Next-Generation Big Data Architectures(zz)
http://duanple.blog.163.com/blog/static/7097176720101118102636423/ After 25 years of dominance, relational databases and SQL have in recent years come under fire from the growing “NoSQL movemen
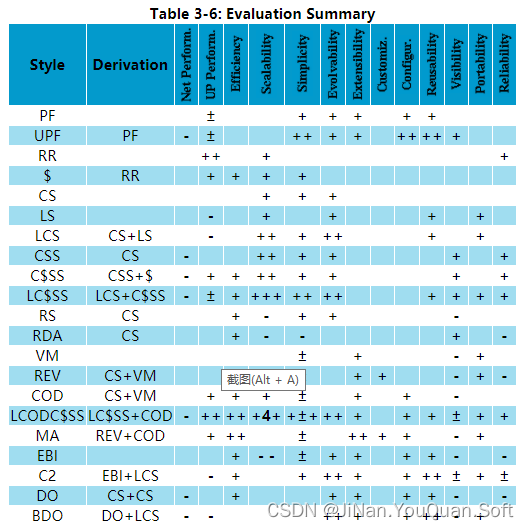
典籍翻译:Architectural Styles and the Design of Network-based Software Architectures
最近周末帮外甥女"小雪"补习英语,遴选了Fielding博士的毕业论文作文课外阅读资料,也借这个机会来重新梳理一下软件架构设计的相关理论。 译者序 本文拟对Fielding的博士论文<Architectural Styles and the Design of Network-based Software Architectures>进行翻译,按照"信、达、雅"的原则,在翻译过程中,力求尊

OFA: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Fr
Paper name OFA: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework Paper Reading Note URL: https://proceedings.mlr.press/v162/wang22al/wang22al.p
关于程序在64位系统上运行报错的问题:No architectures to compile for (ONLY_ACTIVE_ARCH=YES, active arch=x86_64, VALID_
报错信息: No architectures to compile for (ONLY_ACTIVE_ARCH=YES, active arch=x86_64, VALID_ARCHS=i386). 解决方案: 将build setting 中build active architecture only改成NO,architectures自定义添加armv7,armv7s,v

IoT Architectures 架构
IoT Architectures 架构 1. 记住IoT中的I(Internet) 2. TCP/IP堆栈和IP智能对象协议栈 3.Internet 协议 The Internet of Every Thing - st

iOS No architectures to compile for (ARCHS=i386, VALID_ARCHS=armv6 armv7)错误~解决方法
//联系人:石虎 QQ: 1224614774 昵称:嗡嘛呢叭咪哄 一、概念 iOS No architectures to compile for (ARCHS=i386, VALID_ARCHS=armv6 armv7)错误解决办法: 图1: 二、解决方法如下: 在Bulid Settings选项下面的Archi

语义分割综述A SURVEY ON DEEP LEARNING-BASED ARCHITECTURES FOR SEMANTIC SEGMENTATION ON 2D IMAGES
A SURVEY ON DEEP LEARNING-BASED ARCHITECTURES FOR SEMANTIC SEGMENTATION ON 2D IMAGES https://arxiv.org/pdf/1912.10230.pdf Irem Ulku 语义分割的一篇综述,了解下该领域。 语义分割的第一步是对每个pixel给予class label标注。 (这跟目标检

实体-关系联合抽取:Neural Architectures for Named Entity Recognition
文章地址:https://arxiv.org/pdf/1603.01360.pdf 文章标题:Neural Architectures for Named Entity Recognition(命名实体识别的神经结构)NNACL2016 代码地址: 1、LSTM-CRF:https://github.com/glample/tagger2、Stack-LSTM:https://github.

High-Speed Recursion Architectures for Turbo Decoders
High-Speed Recursion Architectures for MAP-Based Turbo Decoders 作者:Zhongfeng Wang机构:Oregon State University, Corvallis, USA期刊:IEEE TRANSACTIONS ON VERY LARGE SCALE INTEGRATION (VLSI) SYSTEMS时间:APR
XCode设置项之Architectures和Valid Architectures
本文所讲的内容都是围绕iPhone的CPU指令集,现在先说说不同型号的iPhone都使用的是什么指令集:Xcode中关于生成二进制包指令集相关的设置项有以下三个: iPhone指令集 本文所讲的内容都是围绕iPhone的CPU指令集(想了解ARM指令集的同学请点击 这里),现在先说说不同型号的iPhone都使用的是什么指令集: ARMv8/ARM64 = iPhone 5
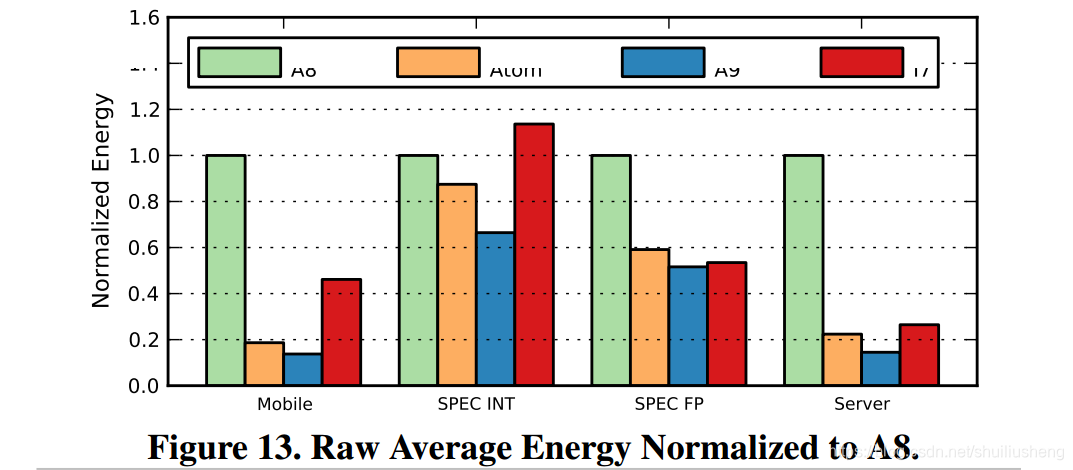
Power Struggles Revisiting the RISC vs. CISC Debate on Contemporary ARM and x86 Architectures
Power Struggles: Revisiting the RISC vs. CISC Debate on Contemporary ARM and x86 Architectures (2013) 摘要: RISC和CISC的争论在1980s激化,而当时芯片面积和处理器设计复杂度是主要的限制因素,并且当时台式机和服务器独占计算领域相比于1980s,现在能耗和功耗是主要的设计约束,计算领域

LLM应用架构 LLM application architectures
在本课程的最后一部分,您将探讨构建基于LLM的应用程序的一些额外考虑因素。首先,让我们把迄今为止在本课程中所见的一切汇总起来,看看创建LLM驱动应用程序的基本组成部分。您需要几个关键组件来创建端到端的应用程序解决方案,从基础设施层开始。该层提供了计算、存储和网络,以提供LLMs,并托管应用程序组件。您可以利用您的本地基础设施,或者通过按需和按使用量计费的云服务提供此基础设施。 接下来,您将包括