本文主要是介绍High-Speed Recursion Architectures for Turbo Decoders,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
High-Speed Recursion Architectures for MAP-Based Turbo Decoders
作者:Zhongfeng Wang
机构:Oregon State University, Corvallis, USA
期刊:IEEE TRANSACTIONS ON VERY LARGE SCALE INTEGRATION (VLSI) SYSTEMS
时间:APRIL 2007
摘要
最大后验概率(MAP)算法以其优异的性能被广泛应用于Turbo解码中。然而,由于固有的递归计算,设计高速映射解码器是非常具有挑战性的。提出了两种新的基于MAP的Turbo解码器的高速递归结构。算法转换、近似和架构优化被结合到建议的设计中,以减少关键路径。仿真结果表明,当应用于Turbo解码时,这两种设计都没有明显的解码性能损失。综合结果表明,所提出的基-2递归体系结构可以实现与最先进的递归(基-4)体系结构相当的处理速度,同时具有显著的低复杂度,而所提出的基-4体系结构比现有设计快32%。
关键词
纠错码;高速设计;最大后验概率解码器;Turbo码;超大规模集成电路
文章目录
- High-Speed Recursion Architectures for MAP-Based Turbo Decoders
- 摘要
- 关键词
- 一. 介绍
- 二. 高级的高速基-2递归结构或MAP解码器
- 三. MAP解码器的改进基-4架构
- 四. 性能比较
- 五. 结论
- 参考文献
一. 介绍
Turbo码[1]发明于1993年,因其卓越的性能在学术界和工业界都引起了极大的关注,在无线和卫星通信中可以找到丰富的应用[2],[3]。实用的Turbo解码器通常采用串行解码架构[4],以提高面积效率。因此,Turbo解码器的吞吐率高度受限于时钟速度和要执行的最大迭代次数。为了便于迭代解码,Turbo解码器需要软输入软输出解码算法,其中最大后验概率(MAP)算法[5]因其优异的性能而被广泛采用。
由于映射算法固有的递归计算,传统的流水线技术不适用于提高有效处理速度,除非使用一个MAP解码器来处理一个以上的Turbo码块或子块,如[6]所述。在[6]–[10]中的各种高速递归架构中,[7]和[10]中的设计最具吸引力。在[7]中,采用偏置-加-比较-选择(OACS)架构[8]来代替传统的加-比较-选择-偏置(ACSO)架构。此外,查找表(LUT)被简化为只有1位输出,并且通过引入两个竞争路径度量的反向差来避免绝对值的计算。据报道,与传统的基-2 ASCO体系结构相比,速度提高了大约17%。通过一步超前操作,基-4的ACSO体系结构可以被导出。如[9]和[10]中给出的实用基-4架构,总是涉及近似值,以实现更高的有效加速。例如,在[10]中采用了以下近似:
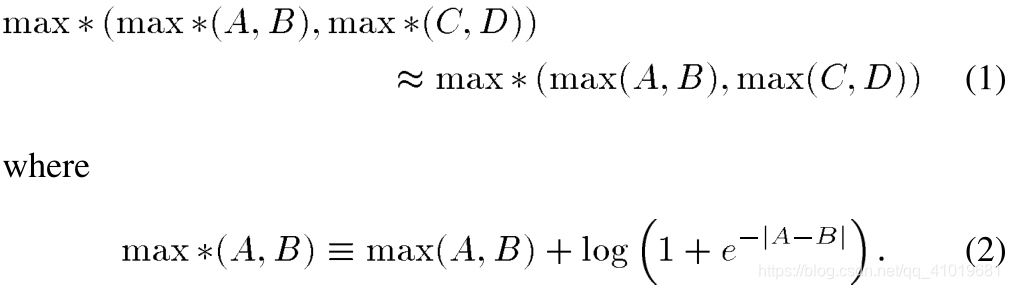
与传统的基-2架构相比,这种基-4架构通常可以将处理速度(等于其时钟速度的两倍)提高40%以上,并且在文献中发现的所有现有(MAP解码器)设计中,它实际上具有最高的处理速度。然而,与传统的ACSO [7]架构相比,硬件将增加近一倍。
本文的贡献包括以下几个方面:1)基于算法转换、近似和体系结构级优化的先进基-2递归体系结构,其处理速度与当前最先进的基-4设计相当,但复杂度显著降低;2)改进的基-4体系结构,其速度比现有最佳方法快32%。
本文组织如下。第二节介绍了一种先进的基-2递归结构的MAP解码器。第三节研究了一种改进的基-4递归体系结构。第四节介绍了原始MAP算法和各种近似算法在Turbo解码中应用时的误码率性能比较。本节还提供了各种架构的硬件复杂性和处理速度的综合结果。
二. 高级的高速基-2递归结构或MAP解码器
为了方便后面的讨论,我们想在这一节的开头简单介绍一下基于MAP的Turbo解码器结构。MAP算法一般在对数域实现,因此称为对数-MAP算法。基于MAP的Turbo解码器通常采用滑动窗口方法[11],以便减少计算延迟和用于存储状态度量的存储器。正如在[4]中所解释的,对数-MAP解码器需要三个递归计算单元: α \alpha α、 β \beta β、pre- β \beta β。本文主要研究高速递归计算单元的设计,因为它们是高速电路设计的瓶颈。
从对数-MAP算法可知,所有三个递归单元都具有相似的体系结构。因此,我们将重点讨论 α \alpha α单元的设计。图1示出了 α \alpha α计算的传统设计,其中ABS块用于计算输入的绝对值,LUT块用于实现非线性函数 l o g ( 1 + e − x ) log(1 + e^{-x}) log(1+e−x),其中x > 0。为简单起见,只画一个分支(即一个状态)。假设溢出方法[14]像常规Viterbi解码器中那样用于状态度量的正规化。
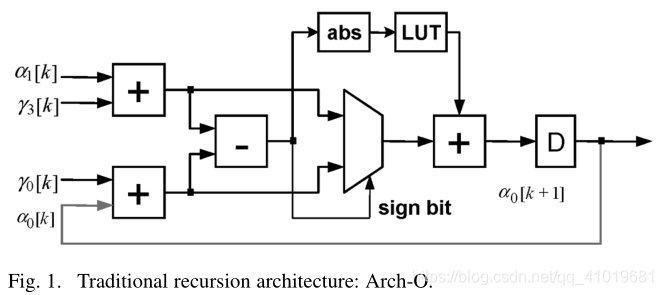
可以看出,递归循环的计算由三个多位加法、绝对值的计算和实现LUT的随机逻辑组成。由于每个递归循环中只有一个延迟元件,传统的重定时技术[12]不能用于减少关键路径。
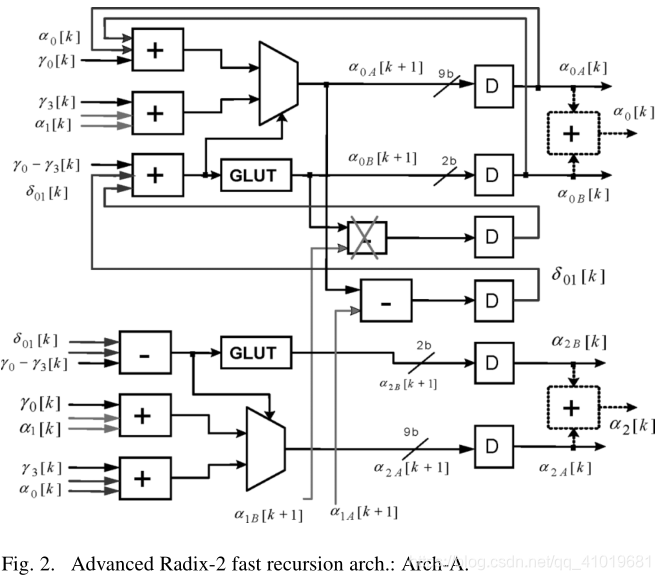
在本文中,我们提出了一个先进的基-2递归结构,如图2所示。这里,我们首先为每对竞争状态度量(例如,图2中的 α 0 \alpha_0 α0和 α 1 \alpha_1 α1)引入一个差异度量,以便我们可以同时执行前端加法和减法操作,从而减少循环的计算延迟。其次,我们采用了一个广义LUT(见图2中的GLUT),它可以有效地避免绝对值的计算,而不是像[7]那样引入另一个减法运算。第三,我们像OACS体系结构[8]一样,将最后的加法移到输入端,然后利用一级进位保存结构将三位数加法转换为两位数加法。最后,为了进一步减少关键路径,我们进行了智能近似。
对于图2中所示的递归计算,假设以下等式:
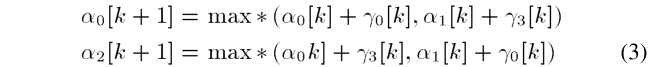
其中 m a x ∗ max* max∗函数在(2)中定义。
此外,我们将每个状态指标分为以下两项:
同样,相应的差异指标也分为以下两项:
这样,原始的相加和比较操作被转换为三个数字的相加,即
其中( γ 0 − γ 3 \gamma_0-\gamma_3 γ0−γ3)由分支度量单位(BMU)计算,为了简单起见,省略了时间索引 [ k ] [k] [k]。此外,来自两个GLUTs的两个输出之间的差异,即图中 δ 01 B \delta_{01B} δ01B,可以忽略不计。从广泛的模拟中,我们发现这种小的近似不会导致在AWGN信道或瑞利衰落信道下的Turbo解码中的任何性能损失。这个事实在下面简单说明。如果一个竞争路径度量(例如, p 0 = α 0 + γ 0 p_0 = \alpha_0+\gamma_0 p0=α0+γ0)明显大于另一个(例如, p 1 = α 1 + γ 3 p_1 = \alpha_1+\gamma_3 p1=α1+γ3),但由于它们的幅度小,GLUT输出无论如何都不会改变决策。另一方面,如果两个竞争路径度量非常接近,以致于添加或移除一个GLUT的小值输出可能会改变决策(例如,从 p 0 > p 1 p_0 > p_1 p0>p1到 p 1 > p 0 p_1 > p_0 p1>p0),则选择任何幸存者都不会有很大影响。
在输入端,采用图3所示的小电路将三个数相加转换为两个数相加,其中FA和HA分别代表全加器和半加器,XOR代表异或门, d 0 d0 d0 和 d 1 d1 d1 对应GLUT的 2bit 输出。在本例中,状态度量和分支度量分别用 9bit 和 6bit 表示。符号扩展仅适用于分支度量。应当注意,在将每个状态度量存储到 α \alpha α 存储器之前,可能需要额外的加法运算(参见虚线加法器框)来对其进行积分。
GLUT结构如图4所示,其中绝对值的计算通过将符号位包括在两个逻辑块中来消除,即Ls2和ELUT,其中Ls2功能块用于检测输入的绝对值是否小于2.0,ELUT块是具有 3bit 输入和 2bit 输出的小LUT。可以推导出 Z = S ‾ b 7 , . . . , + b 1 + b ‾ + S ( b 7 , . . . , b 1 b 0 ) Z = \overline{S}~\overline{b_7,...,+b_1+b}+S(b_7,...,b_1b_0) Z=S b7,...,+b1+b+S(b7,...,b1b0)。据[13]报道使用LUT的两个输出值仅导致四态Turbo码的浮点仿真性能损失0.03dB。近似描述如下:
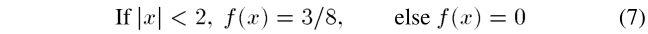
其中x和f(x)分别代表LUT的输入和输出。在这种方法中,我们只需要检查输入的绝对值是否小于2,这可以由图4中的Ls2块来执行。这种方法的一个缺点是,如果状态度量的小数部分只保留两位,其性能会显著下降,这是通常的情况。
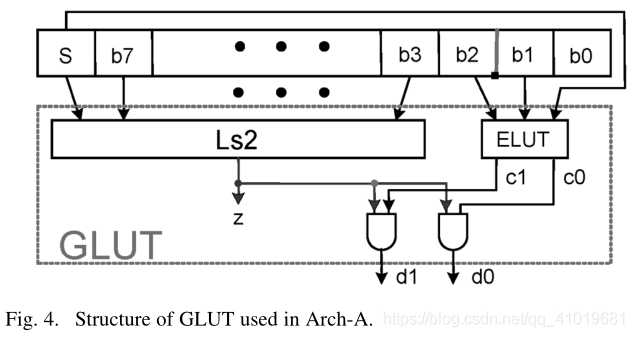
在我们的设计中,LUT的输入和输出都被量化为四个级别。细节如表1所示。ELUT的输入被视为一个 3bit 有符号二进制数。ELUT的输出与Ls2模块的输出相与。这意味着,如果输入的绝对值大于2.0,GLUT的输出为0。否则,ELUT的输出将是最终输出。ELUT可以用于高速应用的组合逻辑来实现。计算延迟小于Ls2块的延迟。因此,GLUT的总延迟几乎与前面讨论的简化方法相同,其总延迟由一个2:1多路复用器门延迟和逻辑块Ls2的计算延迟组成。

经过之前的所有优化,递归架构的关键路径减少到两个多位加法、一个2:1多路复用操作和一个1位加法运算,与传统的ACSO架构相比,节省了近两个多位加法器延迟。我们将在第四部分展示详细的比较。
三. MAP解码器的改进基-4架构
下面,我们讨论一个改进的基-4递归架构。 α 0 [ k + 2 ] \alpha_0[k+2] α0[k+2]的计算表示如下:
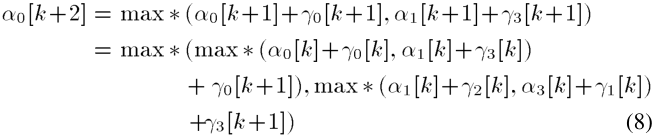
其中 α 1 [ k + 1 ] = m a x ∗ ( α 2 [ k ] + γ 2 [ k ] , α 3 [ k ] + γ 1 [ k ] ) \alpha_1[k+1]=max*(\alpha_2[k]+\gamma_2[k],\alpha_3[k]+\gamma_1[k]) α1[k+1]=max∗(α2[k]+γ2[k],α3[k]+γ1[k])。
在[10]中,朗讯贝尔实验室提出了以下近似:
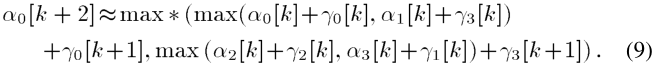
据报道,与原始对数-MAP算法相比,该近似算法的性能损失为0.04dB。为了方便后面的讨论,图5中示出了实现前面计算的体系结构。可以看出,关键路径由四个多位加法器延迟、一个广义LUT延迟和一个2:1多路复用器延迟组成(注意:LUT1块包括绝对值计算和一个正常的LUT运算;MAX模块包括一个减法器和一个2:1多路复用器)。
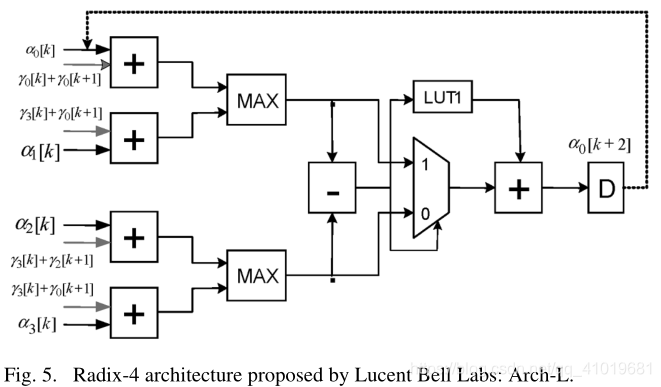
同样,我们可以采用如下替代近似值:
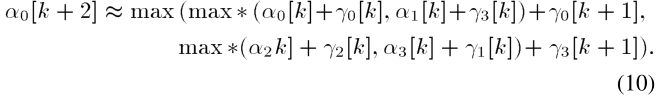
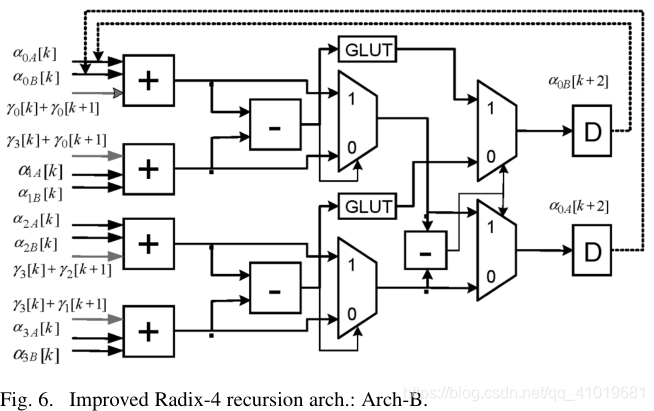
直观地,采用这种新近似的Turbo解码器应该具有与使用(8)相同的解码性能。虽然直接实现(10)不会给关键路径带来任何优势,但我们打算利用我们在第二节中开发的技术。细节如图6所示。这里,我们将每个状态度量分成两个项,并采用与之前相同的GLUT结构。此外,与Arch-A类似的近似也包含在内。在这种情况下,GLUT的输出不涉及最后一级比较操作。可以观察到,新架构的关键路径接近三位加法器延迟。为了补偿引入的所有近似值,由基于这种新的基-4架构的MAP解码器生成的外部信息应该以大约0.75的因子进行缩放。
四. 性能比较
为了定量比较硬件复杂度和处理速度,我们使用TSMC 0.18-μm标准单元来综合的一个 α \alpha α单元,对于六种不同的递归体系结构,即
1)传统的ACSO体系结构:Arch-O;
2)参考基-2架构,采用GLUT和OASC结构:Arch-R;
3)在[7]中提出的低精度基-2递归体系结构:Arch-U;
4)朗讯提出的Radix-4架构:Arch-L;
5)本文提出的高级的基-2递归体系结构:Arch-A;
6)改进的基数-4递归结构:Arch-B。
所有状态度量被量化为9位,而分支度量用6位表示。综合是针对速度进行优化的。详细结果列于表2。
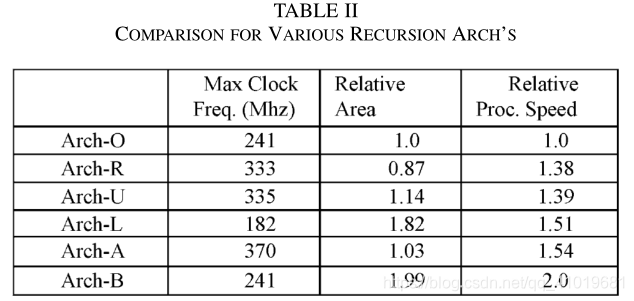
从表2可以看出,所提出的基-2体系结构明显快于传统的基-2体系结构。加速可归因于三个因素:1)使用GLUT来减少计算绝对值的延迟;2)将偏移加法移动到前端,并采用3到2压缩器来减少环路中的总加法延迟;以及3)引入差分状态度量以减少比较两个竞争路径度量的延迟。还可以观察到,无论是Arch-R,还是Arch-U的速度,都没有从第三个因素中获益。这就是为什么所提出的基-2架构比其他两个基-2架构更快。事实上,新的基-2架构具有与朗讯提出的基-4架构相当的处理速度,同时具有显著更低的复杂性。可以计算出,新的基-4架构比朗讯基-4架构快32%,硬件开销仅为9%。与整个Turbo解码器相比,这种额外的硬件量可以忽略不计。
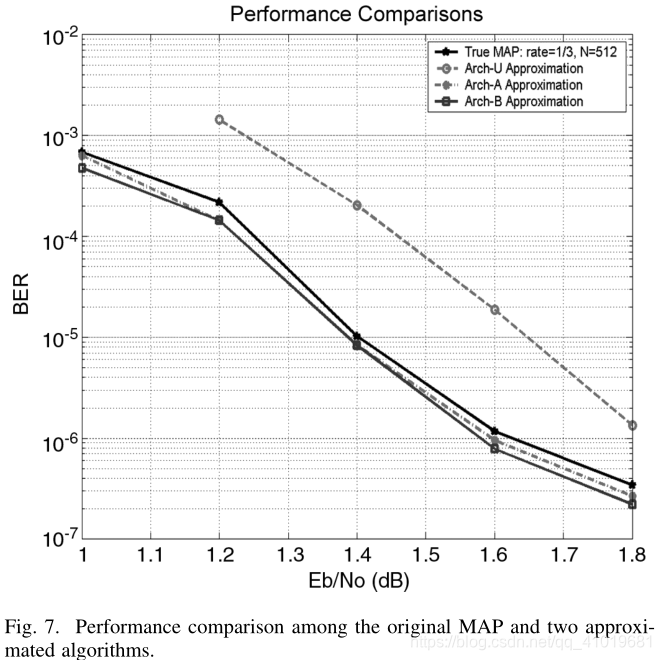
我们使用原始MAP和各种近似对Turbo码进行了广泛的仿真。图7示出了使用不同MAP架构的速率为1/3,8状态,块大小为512位的Turbo码的误码率性能。仿真是在AWGN信道和BPSK信令的假设下完成的。最多执行了八次迭代。在 E b / N o = 1.6 d B Eb/No=1.6dB Eb/No=1.6dB和 E b / N o = 1.8 d B Eb/No=1.8dB Eb/No=1.8dB的情况下,仿真了4000多万个随机信息比特。从图8中可以注意到,在真正的MAP算法和与所提出的递归体系结构相关联的两种近似方法之间没有明显的性能差异,而[7]中使用的近似导致了 0.2 – 0.25 d B 0.2–0.25dB 0.2–0.25dB的性能下降。
我们认为所提出的基-4递归结构对于高速MAP解码器是最优的。任何(显著地)更快的递归体系结构(例如,可能的基-8体系结构)都将以指数级增加的硬件为代价。另一方面,当目标吞吐量适中时,这些快速递归架构可以用来降低功耗,因为它们显著减少了关键路径。
五. 结论
通过为每对竞争状态引入差异度量,我们成功地减少了状态度量比较操作的计算延迟。在为每个状态度量重新安排最后的加法操作之后,通过在每个递归循环的前端使用进位保存结构,我们几乎节省了关键路径上的多位加法器延迟。在所提出的GLUT结构中,每个LUT操作的绝对值的计算已经被有效地消除。综合结果表明,所提出的基-2递归体系结构与最先进的基-4递归体系结构一样快,同时具有显著更低的复杂性,而改进的基-4体系结构比文献中的任何快速递归体系结构快32%。已经通过仿真验证了所提出的设计中涉及的近似不会导致任何(误码率)性能下降。
参考文献


这篇关于High-Speed Recursion Architectures for Turbo Decoders的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









