本文主要是介绍isscc2024 short course4 In-memory Computing Architectures,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
新兴的ML加速器方法:内存计算架构

1. 概述
内存计算(In-memory Computing)架构是一种新兴的机器学习加速器方法,通过将计算能力集成到存储器中,以减少数据移动的延迟和能耗,从而提高计算效率和性能。这种方法特别适用于需要大量数据处理的深度学习任务。
出现存内计算的原因


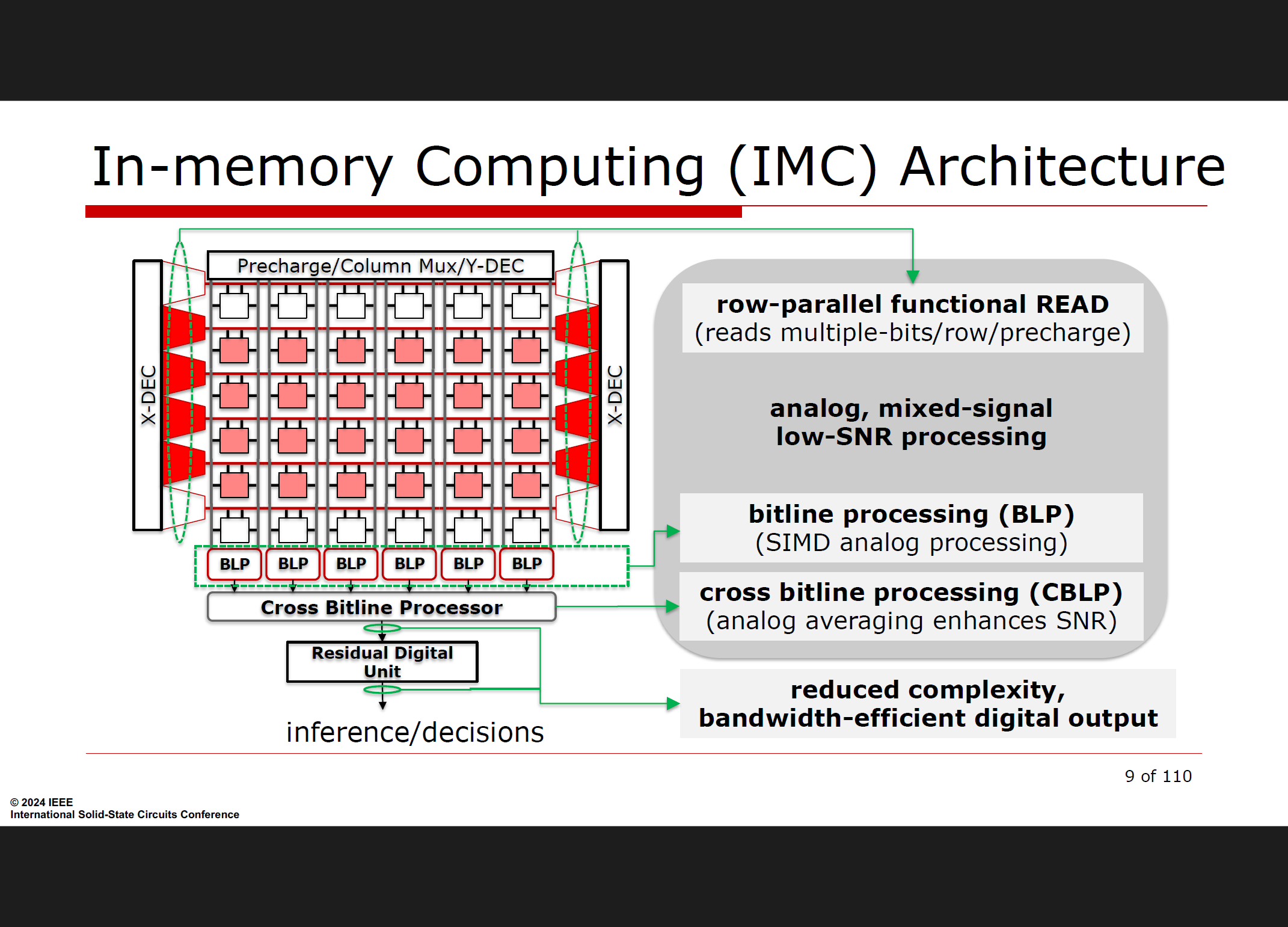
IMC与数字电路的优势

2. 内存计算的优势
- 减少数据移动:在传统计算架构中,数据在处理器和存储器之间频繁移动,导致延迟和能耗增加。内存计算通过在存储器内进行计算,显著减少了数据移动,提高了能效。
- 提升计算效率:将计算单元直接集成到存储器中,可以在数据被读取的同时进行计算,减少了数据传输的时间开销。
- 适应性强:内存计算架构可以适应多种计算任务,包括矩阵乘法、卷积操作等常见的深度学习计算任务。
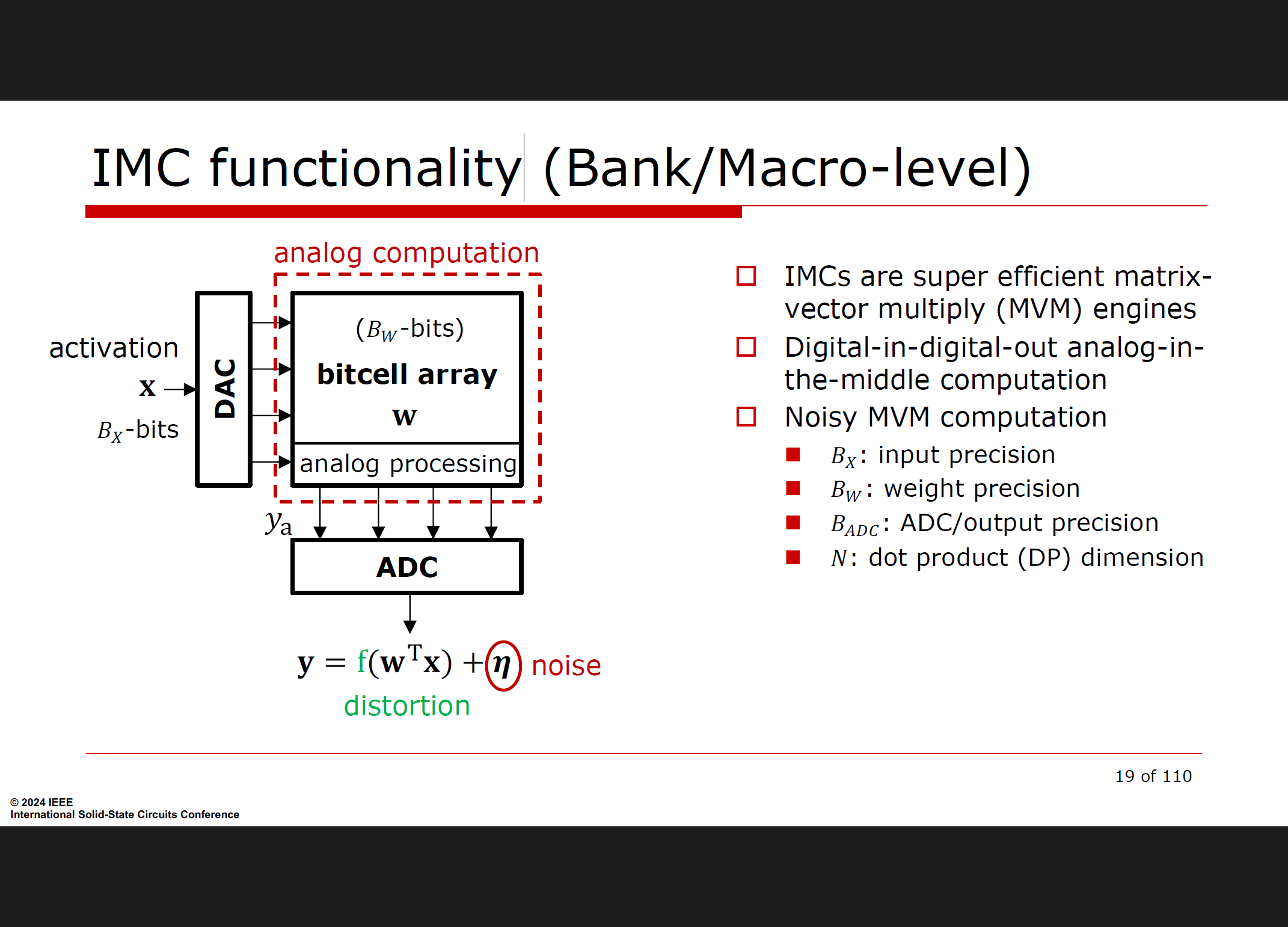
高效的矩阵-向量乘法 (MVM) 引擎:
IMC架构特别擅长执行矩阵-向量乘法操作,这是许多机器学习算法中的核心计算任务。
通过在存储器阵列内部进行计算,IMC可以大幅减少数据在处理器和存储器之间的移动,从而降低能耗和提高性能。
数字-数字-模拟混合计算:
某些IMC设计采用数字-数字-模拟(Digital-Digital-Analog, DDA)计算模型,其中模拟计算可以在数字域之间执行,以利用模拟电路的高并行性和低能耗特性。
带噪声的MVM计算:
IMC计算可能会引入噪声,这需要在设计时考虑。例如,模拟计算可能会受到电路噪声的影响。
设计者需要在计算精度和能耗效率之间做出权衡。

定点数表示(Fixed-point Data Representations):
无符号数(Unsigned): 用于表示非负数,可以转换为有符号数。
二进制补码(2’s Complement): 用于表示有符号整数,是计算机中最常用的表示法。
双极性编码(Bipolar Encoding): 使用+1和-1来表示数值,适用于某些特定的硬件实现。
浮点数表示(Floating-point Data Representations):
标准浮点数:在GPU和CPU中常用的表示法,具有动态范围和精度。
BFloat:一种新的浮点数格式,旨在提供比标准浮点数更高的性能和效率。
Posit:一种新的浮点数表示法,旨在减少复杂性并提供更好的精度。
输入调制格式(Input Modulation Formats):
脉宽调制(Pulse-width modulation, PWM): 调制脉冲的宽度来表示信息。
脉幅调制(Pulse-amplitude modulation, PAM): 调制脉冲的幅度来表示信息。
脉密度调制(Pulse-density modulation, PDM): 调制脉冲的密度来表示信息。
二进制(归零)调制(binary (RZ) modulation): 最常见的调制方式,使用二进制值来表示数据。

标准浮点数:GPU和CPU中的标准,具有较高的动态范围和复杂性,但也带来了更高的精度。
BFloat:最近在IMC中采用的一种浮点数表示,它在保持较高动态范围的同时,比标准浮点数具有更高的复杂性和精度。
Posit:一种新的浮点数表示法,旨在在减少复杂性的同时提供更好的精度。Posit通过共享指数或张量共享指数来缓解量化过程中的稳定性问题,提供了更多的浮点级别来适应感兴趣的“区域”。
具体来说,浮点数表示法包括以下几个关键部分:
唯一指数(unique exponent):每个浮点数有自己的指数部分。
共享指数(shared exponent):一组浮点数共享同一个指数部分。
张量共享指数(tensor shared exponent):在更广泛的数据集中共享指数部分。
Posit数据格式通过牺牲一些精度来减少浮点数表示的复杂性,这对于IMC的使用尤其重要,因为它可以提高能效和性能。这种格式特别适合于AI和机器学习应用,这些应用可以容忍一定程度的近似计算。
请注意,浮点数表示法的选择会影响计算的精度和硬件实现的复杂性。在设计IMC架构时,需要根据应用的具体需求和硬件的性能目标来选择合适的浮点数表示法。
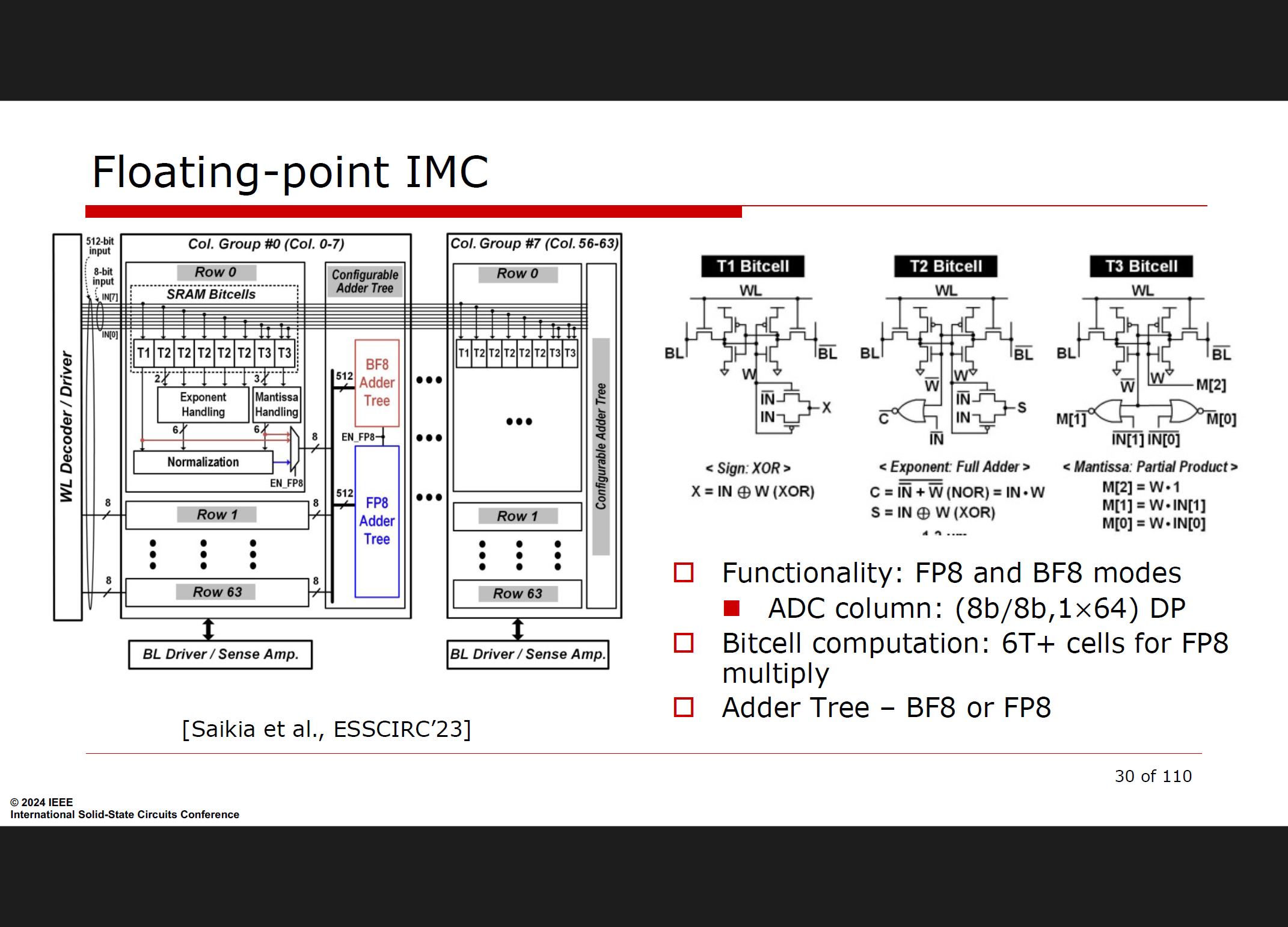
算术分解的几种方法
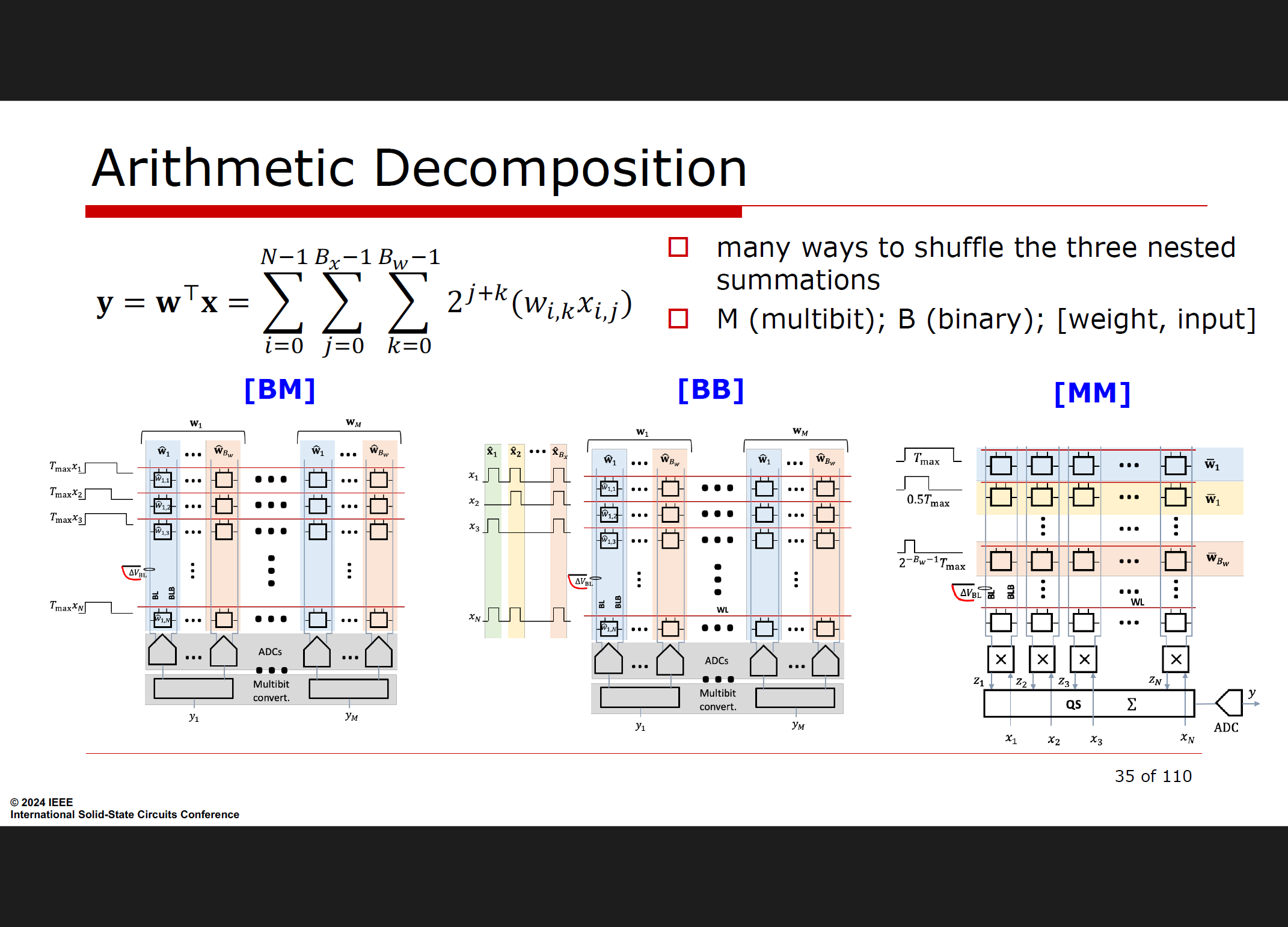

BM 分解 (Binary-Multibit):
这种方法结合了二进制表示的权重和多比特表示的输入(或反之),通过利用二进制和多比特算术的优点,实现更灵活和高效的计算。
例如:BM 分解涉及位级操作和累加过程,处理不同的表示形式,优化特定硬件配置或计算效率 。
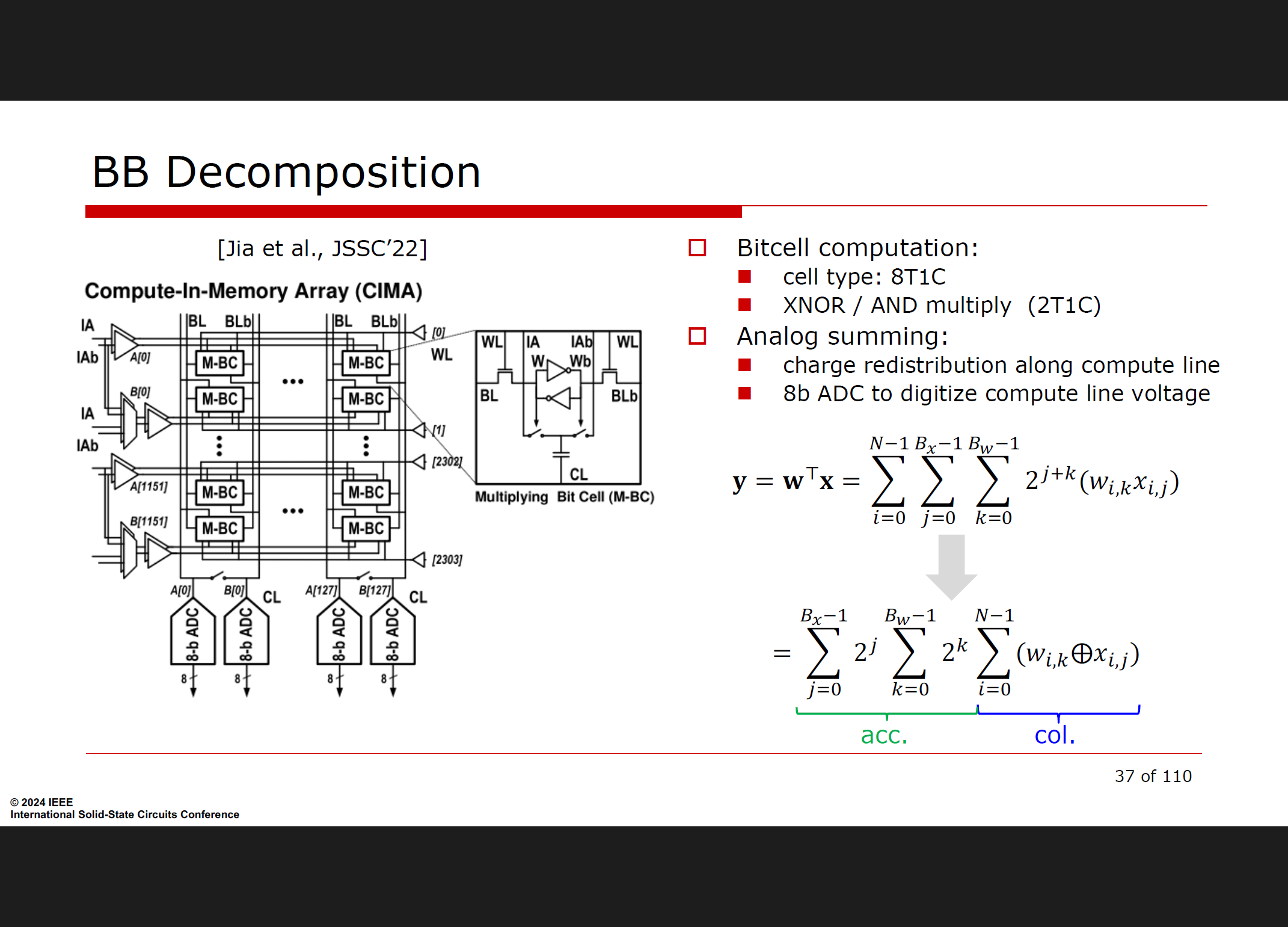
BB 分解 (Binary-Binary):
这种方法对权重和输入都使用二进制表示,通常涉及位级操作,如按位异或 (XOR) 和与 (AND) 运算。
例如:对于给定的输入和权重,BB 分解将使用 w ⨁ x(XNOR/AND 乘法)进行计算,结果在模拟方式下进行累加,然后通过模数转换器 (ADC) 数字化 。

MM 分解 (Multibit-Multibit):
在这种分解中,权重和输入都以多比特格式表示。通常用于需要更高精度的传统数字计算中。
例如:MM 分解方法涉及操作如 w * x,其中两个操作数都是多比特的,可能导致更高的精度和计算强度,但需要更复杂的硬件来有效处理多比特算术 。
每种分解方法在计算复杂度、硬件需求和效率方面都有不同的权衡,选择哪种方法取决于具体应用的需求和所使用的硬件架构 。

计算模型:
QS (Charge Summing): 电荷求和模型,采用标准6T位元存储器,通过行并行计算实现,但受制于电流和时间的变化、钳位、热噪声和读扰问题。
QR (Charge Redistribution): 电荷重分布模型,也称为“电荷域计算”,需要6T+位元存储器,准确性受到信号级别因子损失、电容不匹配、电荷注入和热噪声的限制。
IS (Current Summing): 电流求和模型,普遍应用于基于eNVM的IMC中,准确性和面积主要由电流感应读出决定,能耗相对较低。
DG (Digital Summing): 数字求和模型,用于数字IMC,通过数字累加器替代了模拟求和,避免了ADCs(模数转换器)的使用,提高了准确性和可扩展性。
位元架构:
SRAM (T): 6T、10T、12T、18T位元存储器,通常用于QS模型,提供最高的面积密度。
SRAM (TC): 8T1C、10T1C位元存储器,用于QR模型,解决了读扰问题,支持更高的并行度。
SRAM (D): 6T+D、8T+D位元存储器,用于DG模型,转向数字IMC。
eDRAM: 1T1C、3T位元存储器,用于QR模型。
eNVM: 1T1R位元存储器,用于IS模型,通常与eNVM存储器配合使用。



IMC目前有基于SRAM digital和eNVM这三种结构
基于SRAM的IMC
优点:
高速读写:SRAM提供快速的数据访问速度,适合需要高吞吐量的应用。
易失性:SRAM是易失性的,断电后数据会丢失,但这也使得写入操作可以频繁进行。
缺点:
面积和成本:相比eNVM,SRAM在相同的存储密度下占用更多芯片面积,成本也更高。
功耗:由于需要持续刷新,SRAM的功耗相对较高。
数字(Digital)IMC
优点:
可预测性:数字电路的行为可预测,便于设计和验证。
灵活性:数字设计可以轻松适应不同的计算需求,具有很好的可编程性和灵活性。
缺点:
能耗:数字电路可能在执行某些操作时能耗较高,特别是当涉及复杂的逻辑运算时。
延迟:数字电路可能存在较高的延迟,尤其是在数据需要在多个阶段或模块间传递时。
基于eNVM的IMC
优点:
非易失性:eNVM能够在断电后保留数据,适合作为长期存储解决方案。
低功耗:相比SRAM,eNVM通常具有更低的功耗,特别是在保持数据状态时。
缺点:
写入限制:eNVM的写入次数有限,可能不适合频繁写入的应用。
读取放大:eNVM的读取操作可能涉及放大过程,这可能影响性能和能效。
异同点
相同点:
内存计算能力:所有这些IMC架构都旨在减少数据移动,直接在存储器中进行计算,以提高能效和性能。
并行处理:它们都能够支持一定程度的并行处理,适合执行机器学习等并行计算密集型任务。
不同点:
存储器类型:SRAM、数字和eNVM是三种不同的存储技术,它们在存储密度、速度、功耗和成本方面具有不同的特点。
计算模型:SRAM通常用于QS(电荷求和)模型,数字IMC可能使用DG(数字求和)模型,而eNVM适用于IS(电流求和)模型。
适用场景:SRAM IMC适合高速缓存和短期数据处理,数字IMC适合灵活的计算任务,eNVM IMC适合需要数据持久性的应用。
设计挑战:每种技术都有其设计挑战,如SRAM的高功耗,数字电路的延迟问题,以及eNVM的写入耐用性和读取放大问题。
3. 关键技术
- 嵌入式存储计算(Processing In Memory, PIM):在存储器芯片中集成计算能力,使数据可以在存储器内部直接进行处理,减少了数据传输的需求。
- 电阻式RAM(ReRAM)和相变存储器(PCM):这些新型存储技术不仅具有存储数据的功能,还可以通过改变存储单元的电阻或相态来执行计算操作。
- 混合存储架构:结合传统的DRAM和新型的非易失性存储器(如ReRAM、PCM),实现高效的存储和计算功能。
4. 设计挑战
- 存储器的可靠性和持久性:内存计算架构依赖于新型存储技术的可靠性,需要确保这些存储器在频繁读写操作下的稳定性和耐用性。
- 计算精度:在内存中进行计算时,如何保证计算的精度和准确性是一个关键问题,特别是在处理浮点运算时。
- 热管理:内存计算架构在存储器中集成了计算单元,增加了芯片的功耗密度,如何有效管理热量是设计中的重要挑战。
5. 实际应用
- 深度学习推理:内存计算架构特别适用于深度学习模型的推理阶段,通过减少数据移动和提升计算效率,可以显著提高推理速度和能效。
- 边缘计算设备:在资源受限的边缘计算设备中,内存计算架构可以提供高效的计算能力,同时保持低功耗。
总结
内存计算架构作为新兴的ML加速器方法,通过在存储器中集成计算能力,显著减少了数据移动的延迟和能耗,提升了计算效率。尽管面临可靠性、计算精度和热管理等设计挑战,但在深度学习推理和边缘计算设备中的应用前景广阔。通过不断的发展和优化,内存计算架构有望成为未来ML加速器的重要组成部分。
未来机遇
算法特定架构(Algorithm-Specific Architectures):
设计专门针对特定算法或一类算法的IMC架构,可以优化性能和能效。
为不同的机器学习任务定制硬件,以实现更高的计算效率。
工作负载映射(Workload Mapping):
研究如何将不同的计算工作负载映射到IMC架构上,以实现最佳的性能和能效。
包括数据流和精度匹配、MVM(矩阵-向量乘法)维度匹配以及片上网络设计。
调度和资源分配(Scheduling and Resource Allocation):
开发高效的调度算法,合理分配计算资源,以提高IMC架构的利用率。
优化计算任务的执行顺序,减少等待时间和提高吞吐量。
实现非MVM计算(Realizing Non-MVM Computations):
探索IMC架构在执行非矩阵-向量乘法操作时的应用,如神经网络中的非线性激活函数。
设计硬件以支持这些操作,可能需要结合数字和模拟计算技术。
混合IMC-数字处理器(Hybrid IMC-Digital Processors):
结合IMC和数字处理器的优点,创建混合架构,以处理不同的计算任务。
数字处理器可以处理高精度计算,而IMC部分可以处理大规模并行计算。
可扩展性和编程性:
研究如何提高IMC架构的可扩展性,使其能够适应不断增长的计算需求。
开发易用的编程模型和工具,使开发者能够充分利用IMC架构的优势。
新型存储器技术:
利用新兴的存储器技术,如RRAM(可变电阻存储器)、PCM(相变存储器)等,这些技术可能提供更高的存储密度和更低的功耗。
信号处理和通信:
在雷达信号处理、传感器应用、安全、大规模MIMO等领域探索IMC的应用。
针对这些领域开发专门的信号处理算法和通信协议。
跨学科合作:
促进算法、编译器、微架构、电路和设备研究人员之间的合作,共同推动IMC技术的发展。
集成到AI加速器空间:
将IMC技术集成到AI加速器的设计中,结合AIMC(模拟IMC)、DIMC(数字IMC)、数字处理阵列、GPU和CPU的优势,实现最佳的性能和能效。
这篇关于isscc2024 short course4 In-memory Computing Architectures的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!