本文主要是介绍OFA: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Fr,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Paper name
OFA: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
Paper Reading Note
URL: https://proceedings.mlr.press/v162/wang22al/wang22al.pdf
代码 URL: https://github.com/OFA-Sys/OFA
TL;DR
- ICML 2022 文章,探索了一种多模态预训练模型结构 OFA (One For All),实现统一架构、任务和模式的目标,用统一的模型在 image captioning, visual question answering, visual entailment, referring expression comprehension 等多个任务上实现了 SOTA 结果
Introduction
背景
- 在人工智能界,构建一个能处理与人类一样多的任务和模式的万能模型是一个很有吸引力的目标。实现这一目标在很大程度上取决于能否仅用少数几种或单一模态来统一和管理各种各样的模态、任务和训练
- 目前一些能促进大一统模型的研究
- transformer 架构
- pretrain-finetune 的范式在很多领域取得高精度结果
- few-/zero-shot 领域,prompt tuning 效果显著
- 作者认为大一统模型需要具备的 3 个性质
- Task-Agnostic (TA):统一的任务表示,以支持不同类型的任务,包括分类、生成、自监督任务等,并且对预训练或微调兼容
- Modality-Agnostic (MA):在所有任务之间共享统一的输入和输出表示,以处理不同的模式
- Task Comprehensiveness (TC):足够的任务种类,以稳健地积累泛化能力
- 现有的模型或多或少不满足上述限制,比如 BERT 有 task-specific heads。一些模型在训练和 finetune 时有不同的任务定义和训练目标。在模态统一方面,目前很多方法(VL-BERT、Oscar 等) 依赖目标检测模型来对图片进行处理,这些目标检测模型在 open-domain 数据上不一定可靠
本文方案
- 探索了一种多模式预训练的全模型,并提出了 OFA (One For All),实现统一架构、任务和模式的目标,并满足上述三个大一统模型的性质
- 通过手工指令在统一的序列到序列抽象中制定预训练和微调任务,以实现任务不可知
- 采用 Transformer 作为模态不可知计算引擎,其约束条件是不会向下游任务添加可学习的任务或模态特定组件
- 可以在所有任务的全局共享多模态词汇表中表示来自不同模态的信息
- 通过对各种单模态和跨模态任务的预训练,支持任务综合性.
- 在 20M image-text pairs 的规模数据集上训练就能实现多个任务的 SOTA 结果,包括 image captioning, visual question answering, visual entailment, referring expression comprehension 等
- 作为一种多模态预训练模型,它在语言或视觉上与SOTA预训练模型在单模态任务上的性能相当,比如
- 自然语言理解中的 RoBERTa, ELECTRA, DeBERTa
- 自然语言生成中的 UniLM, Pegasus and ProphetNet
- 图像分类中的 MoCo-v3, BEiT and MAE
Dataset/Algorithm/Model/Experiment Detail
实现方式
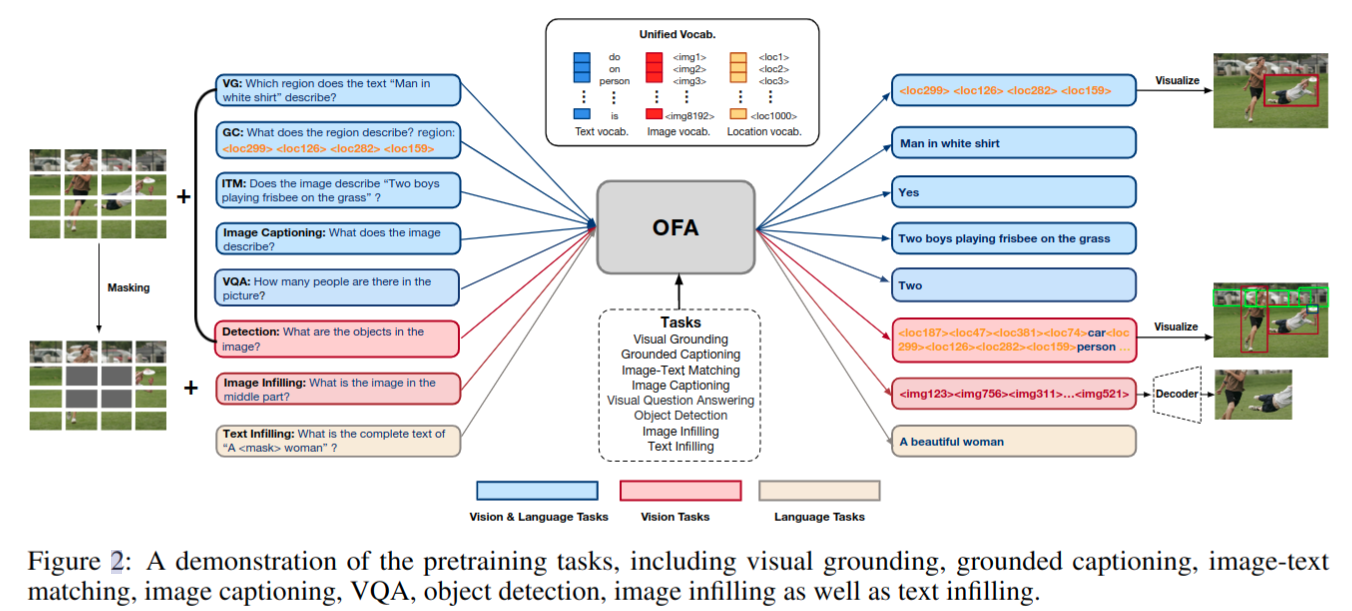
I/O & Architecture
- I/O
- 与复杂、资源和耗时的对象特征提取相比,本文追求简单,参考 SimVLM 与 CoAtNet,直接使用 ResNet 模块卷积将 xv∈R(H×W×C) 转换到 P 个 patch 特征
- 关于处理语言信息,参考 GPT 和 BART,对给定的文本序列应用字节对编码(BPE),将其转换为子单词序列,然后将其嵌入特征
- 离散化文本、图像和对象,并用统一词汇表中的 token 来表示它们。稀疏编码在减少图像表示的序列长度方面是有效的,分辨率为256×256的图像表示为长度为16×16的代码序列
- 除了代表图像,由于存在一系列与区域相关的任务,因此在图像中表示对象也是非常重要的。参考 Pix2seq,将对象表示为离散 token 序列。更具体地说:
- 对于每个目标,提取其标签和边界框
- 边界框的连续角坐标(左上和右下)统一离散为整数,作为位置标记〈x1,y1,x2,y2〉
- 至于对象标签,它们是独立的单词,因此可以用 BPE 标记表示
- 最终对所有语言和视觉标记使用统一的词汇表,包括子词、图像代码和位置标记
- Architecture
- 使用 encoder-decoder 的 transformer 作为统一 pretraining,finetuning 和 zero-shot 任务的模型架构
- encoder 包含 self attention 和 FFN,decoder 包含 self-attention、cross-attention 和 FFN
- 为了稳定训练,对 self-attention 加了 head scaling (也即 LN),每个 FFN 的第一层后加 LN
- 对于位置信息,分别对文本和图像使用两个绝对位置嵌入。不是简单地添加位置嵌入,而是将位置相关性与 token embeddings 和 patch embeddings 解耦。对文本使用 1D 相对位置偏差,对图像使用 2D 相对位置偏差
- 使用 encoder-decoder 的 transformer 作为统一 pretraining,finetuning 和 zero-shot 任务的模型架构
Tasks & Modalities
- 所有的 pretraining, finetuning, and inference 都被统一为 Seq2Seq generation 任务
- 跨模态任务:
- visual grounding (VG), grounded captioning (GC), image-text matching (ITM), image captioning (IC), and visual question answering (VQA) 按照数据集规定的形式训练
- 单模态任务:
- image infilling:图像补全,instruction 使用 “What is the image in the middle part”
- object detection:目标检测,instruction 使用“What are the objects in the image”
- text infilling:参考 BART 的纯文本补全
数据集
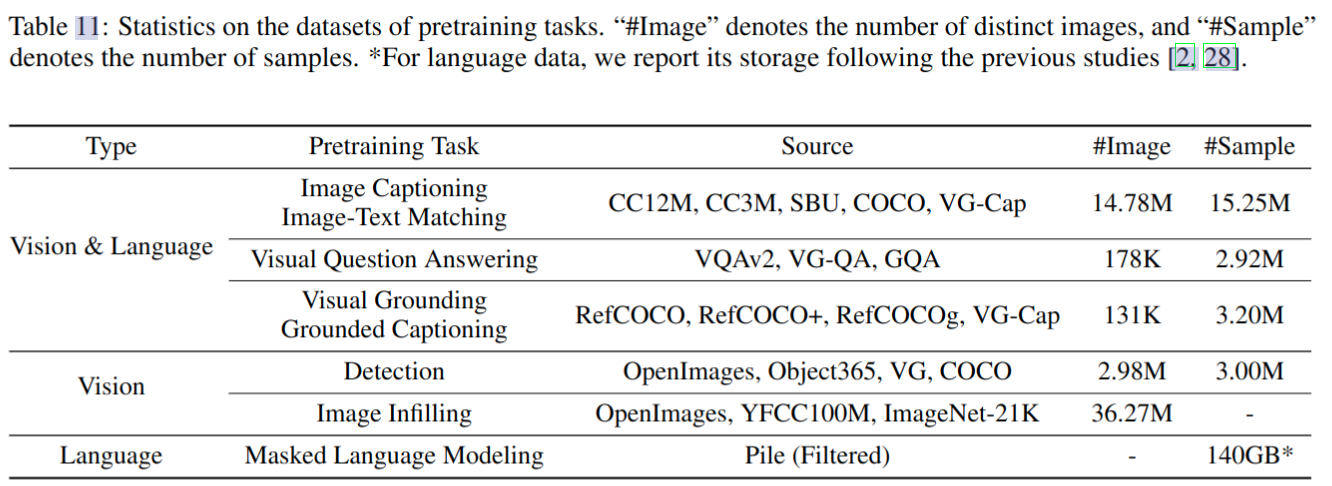
Training & Inference
-
training:使用 cross-entropy 损失优化模型
-
inference:使用 beam search 优化生成结果,这里为了不在分类上产生不良影响,提出了一种基于前缀树 (Trie) 的搜索策略,可以提升在分类任务上的精度
- 首先构造一个 Trie,其中节点用候选标签集中的标记进行注释
- 在微调期间,模型根据目标 token 在 Trie 上的位置计算其对数概率
- 如下图所示,当计算 token sky 的对数概率时,只考虑 sky 和 ocean 中的 token,并将所有无效 token 的对数强制设置为负无穷
- 在推理过程中,将生成的标签约束在候选集上
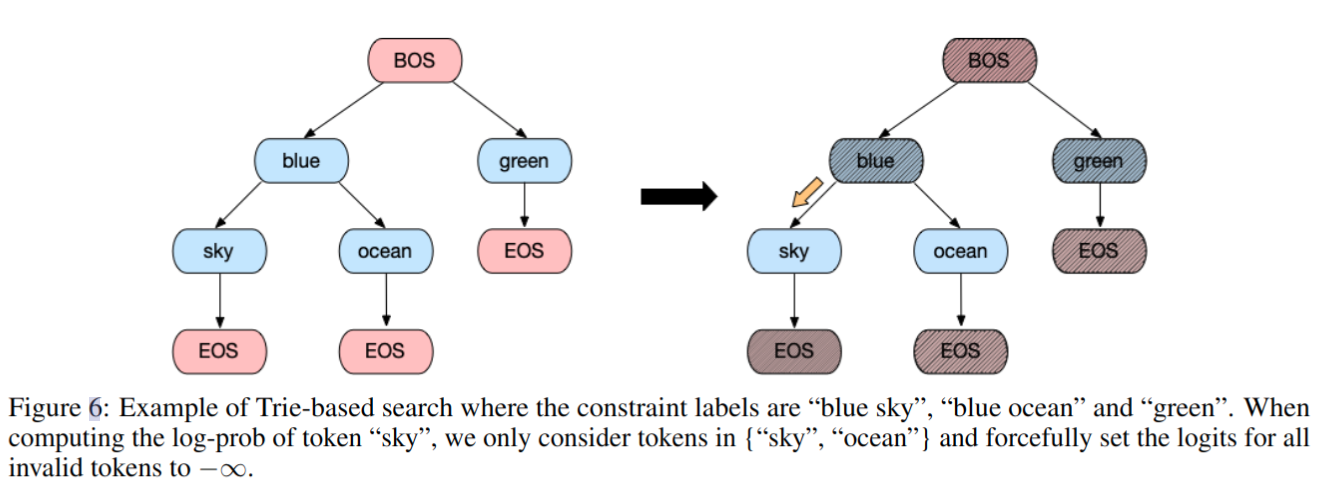
-
下游任务上的精度提升

Scaling Models
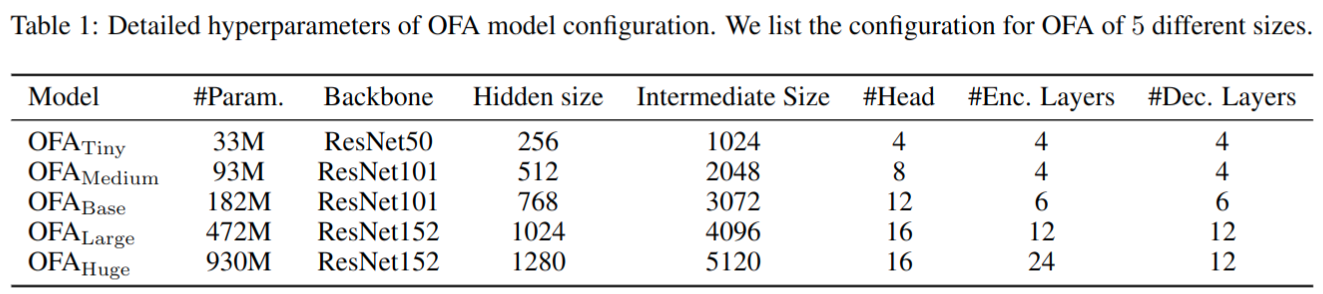
实验结果
Results on Cross-modal Tasks
- VQA 任务大模型精度略低于 BLIP2,作者强调小模型 O F A L a r g e OFA_{Large} OFALarge 是能在这个模型量级上达到 SOTA 效果
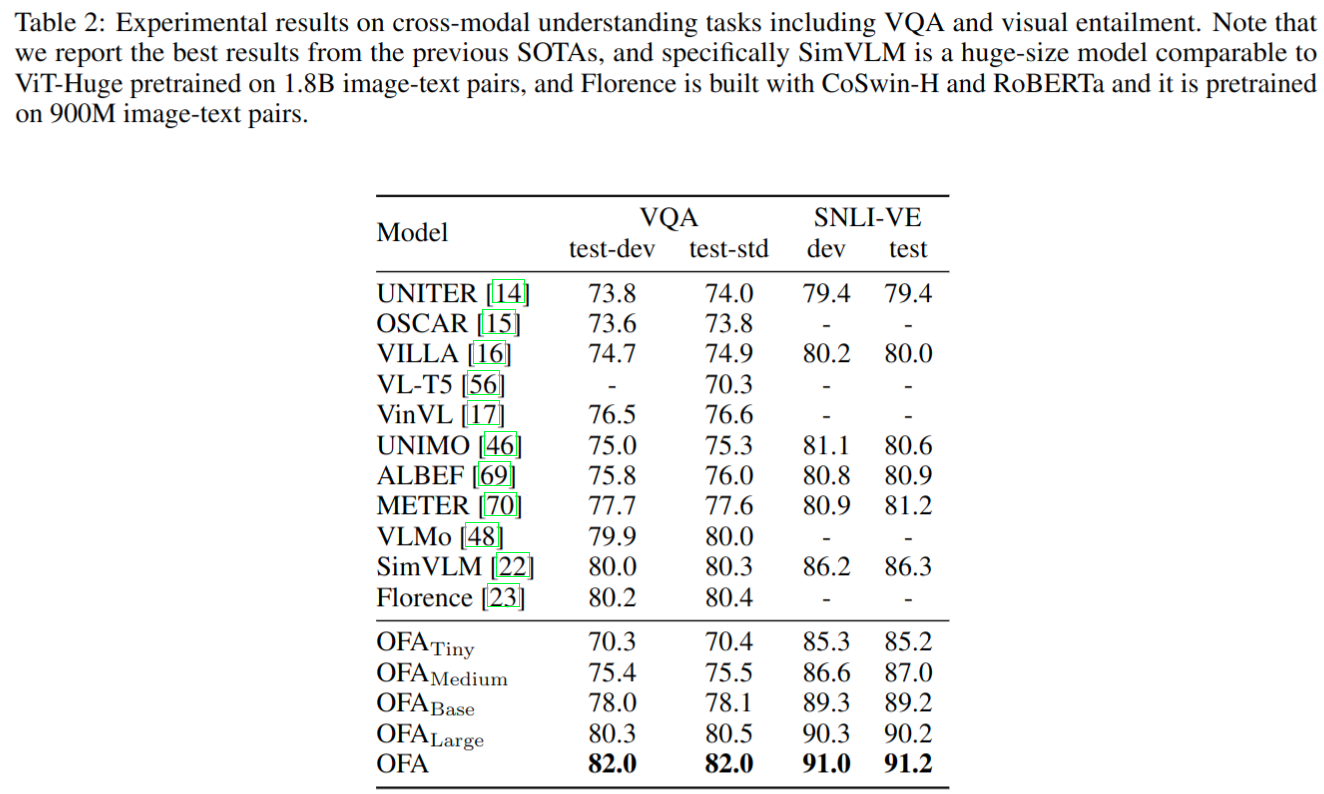
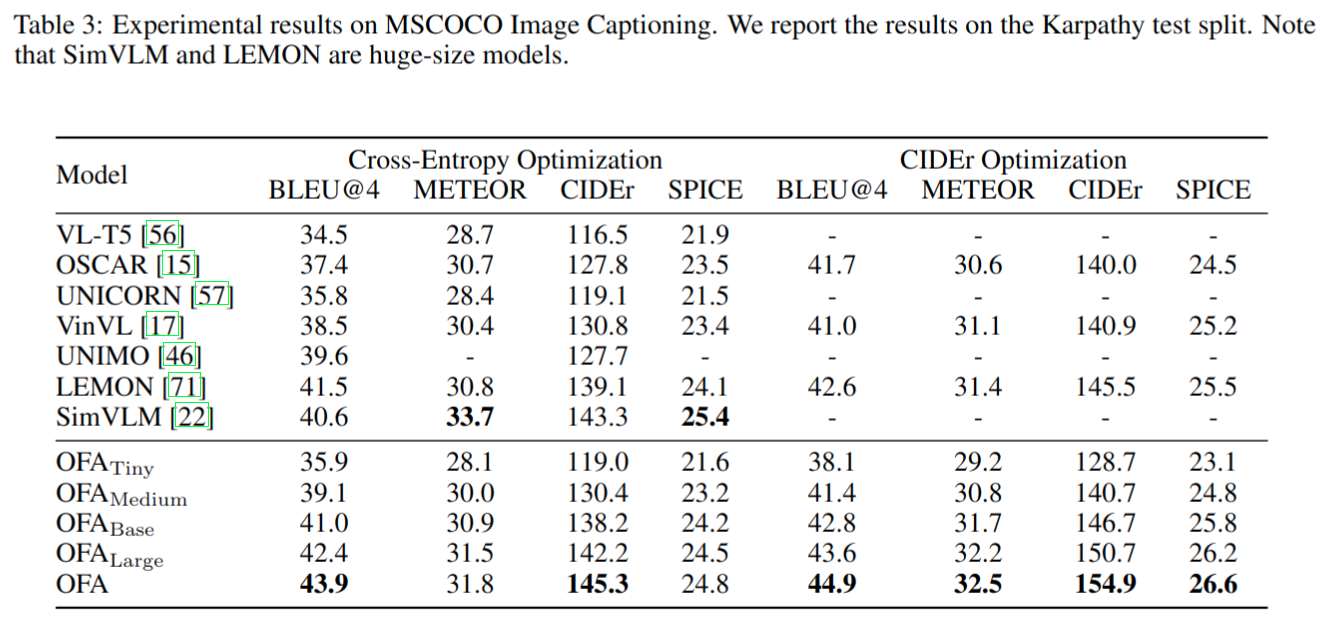
- image caption
文本生成图片任务
- 文本生成图片任务


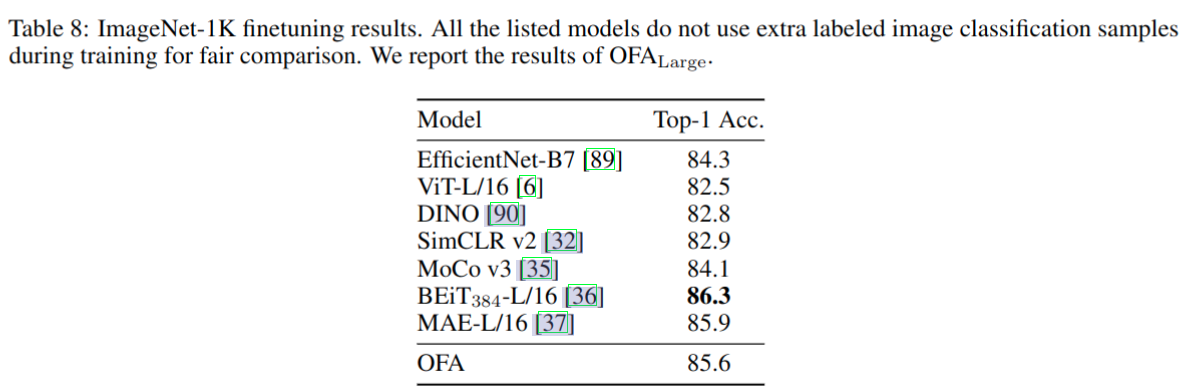
图像分类任务
可视化展示
-
unseen task grounded QA,有一定泛化性

-
unseen domain 上的 VQA

Thoughts
- 整体来看缝合了很多之前工作的技巧,实现了大一统的模型设计,文本等方面的设计设计思路和 T5 很像,文章重点主要是将图像也能转换到利于语言模型处理的 token 形式上,主要也是借鉴了之前的工作实现的
这篇关于OFA: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Fr的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






