本文主要是介绍机器学习笔记(二)梯度下降法实现对数几率回归(Logistic Regression),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 前言
- 一、 梯度下降法(Gradient Descent)
- 1.1 Python简单实现
- 二、对数几率回归模型
- 三、 梯度下降法实现对数几率回归
- 3.1 西瓜数据集展示
- 3.2 Python实践
- 3.2.1 数据准备
- 3.2.2数据处理
- 3.2.3模型训练
- 3.2.3模型展示
- 总结
- 参考文献
前言
在之前的机器学习笔记(一)对数几率回归模型(Logistic Regression)中详细介绍了对数几率回归模型,而本篇文章则是使用梯度下降法实现对数几率回归模型的实践。本文将详细介绍梯度下降算法的内容与知识点,以及使用其求解对数几率回归模型参数最优解的过程。
以下是本篇文章正文内容
一、 梯度下降法(Gradient Descent)
梯度下降算法是常用的一阶优化算法,是求解无约束优化问题最简单、也是最经典的数值优化算法之一。
考虑无约束优化问题:求解x使得 f ( x ) f(x) f(x)最小,其中 f ( x ) f(x) f(x)为连续可微函数,若能构造一个序列 x 0 , x 1 , x 2 , . . . x^{0}, x^{1}, x^{2},... x0,x1,x2,...满足
f ( x t + 1 ) < f ( x t ) , t = 0 , 1 , 2 , . . . (1.1) f(x^{t+1})<f(x^{t}),t=0, 1, 2, ... \tag{1.1} f(xt+1)<f(xt),t=0,1,2,...(1.1)
则不断执行该过程即可收敛到局部极小点,欲满足式(1.1), 根据泰勒展开式有
f ( x + Δ x ) ≃ f ( x ) + Δ x ∇ f ( x ) (1.2) f(x+\Delta x) \simeq f(x) + \Delta x \nabla f(x) \tag{1.2} f(x+Δx)≃f(x)+Δx∇f(x)(1.2)
于是欲满足 f ( x + Δ x ) < f ( x ) f(x+\Delta x)<f(x) f(x+Δx)<f(x), 可选择
Δ x = − γ ∇ f ( x ) \Delta x = - \gamma \nabla f(x) Δx=−γ∇f(x)
其中步长 γ \gamma γ是一个小常数, 这就是梯度下降法
1.1 Python简单实现
代码展示了使用python实现梯度下降法求解函数 f ( x ) = x 2 + 3 x − 1 f(x)=x^{2} + 3x - 1 f(x)=x2+3x−1最小值的完整过程。
class GradientDescent:def __init__(self, x0, step=0.01):self.x0 = x0self.step = stepdef function(self, x):return x * x - 3 * x - 1def fisrt_order(self, x):return 2 * x - 3def run(self):x = self.x0gradient = self.fisrt_order(x)while abs(gradient) > 1e-6:delta_x = -self.step * gradientx = x + delta_xgradient = self.fisrt_order(x)minimum = self.function(x)return minimumgd = GradientDescent(0)
minimum = gd.run()
二、对数几率回归模型
对数几率回归模型的相关知识已在机器学习笔记(一)对数几率回归模型(Logistic Regression)一章中详细展开描述, 这里笔者不加以赘述, 只列出模型优化过程中需要用到的主要公式.
对率函数中 ω \omega ω和 b b b是我们需要进行优化并算出最优值的参数, 如式2.1所示
y = 1 1 + e − ( ω T x + b ) (2.1) y = \frac{1}{1+e^{-(\omega^Tx+b)}} \tag{2.1} y=1+e−(ωTx+b)1(2.1)
式2.2是关于 β \beta β的高阶连续可导凸函数, 其中 β = ( ω ; b ) \beta=(\omega;b) β=(ω;b), 在这里使用梯度下降法求其最优解, 即可确定参数 ω \omega ω和 b b b最优值
l ( β ) = ∑ 1 m − y i ⋅ β T x ^ i + l n ( 1 + e β T x ^ i ) (2.2) l(\beta)=\sum_{1}^{m}-y_{i}\cdot\beta^{T}\hat{x}_{i} + ln(1+e^{\beta^{T}\hat{x}_{i}})\tag{2.2} l(β)=1∑m−yi⋅βTx^i+ln(1+eβTx^i)(2.2)
根据梯度下降法的数学原理,使用梯度下降法求解函数最优值时,需要对目标函数进行一阶求导以计算梯度,在这里,我们对式2.2中的 β \beta β进行一阶求导, 得到
∂ l ∂ β = − ∑ 1 m x ^ i ⋅ ( y i − e β T 1 + e β T x ^ i ) (2.3) \frac{\partial {l}}{\partial {\beta}} = -\sum_{1}^{m}\hat{x}_{i}·(y_{i}-\frac{e^{\beta^{T}}}{1+e^{\beta^{T}\hat{x}_{i}}}) \tag{2.3} ∂β∂l=−1∑mx^i⋅(yi−1+eβTx^ieβT)(2.3)
三、 梯度下降法实现对数几率回归
在这里笔者使用周志华老师《机器学习》一书中的西瓜数据集,作为训练数据集。使用西瓜数据集训练模型,建立通过西瓜的密度以及含糖率来预测西瓜是否为好瓜的对数几率回归模型。
3.1 西瓜数据集展示
| 编号 | 密度 | 含糖率 | 好瓜 |
|---|---|---|---|
| 1 | 0.697 | 0.460 | 1 |
| 2 | 0.774 | 0.376 | 1 |
| 3 | 0.634 | 0.264 | 1 |
| 4 | 0.608 | 0.318 | 1 |
| 5 | 0.556 | 0.215 | 1 |
| 6 | 0.403 | 0.237 | 1 |
| 7 | 0.481 | 0.149 | 1 |
| 8 | 0.437 | 0.211 | 1 |
| 9 | 0.666 | 0.091 | 0 |
| 10 | 0.243 | 0.267 | 0 |
| 11 | 0.245 | 0.057 | 0 |
| 12 | 0.343 | 0.099 | 0 |
| 13 | 0.639 | 0.161 | 0 |
| 14 | 0.657 | 0.198 | 0 |
| 15 | 0.360 | 0.370 | 0 |
| 16 | 0.593 | 0.042 | 0 |
| 17 | 0.719 | 0.103 | 0 |
注意:好瓜一列中为1则是好瓜,为0则是坏瓜。
3.2 Python实践
3.2.1 数据准备
这里笔者将3.1中的西瓜数据集,存储为csv文件,供程序读取和处理。
import numpy as np# load dataset
data_file = './watermelon_data.csv'
data = np.loadtxt(data_file, skiprows=1, delimiter=",")
print(data)
读取到的数据集如下图所示:
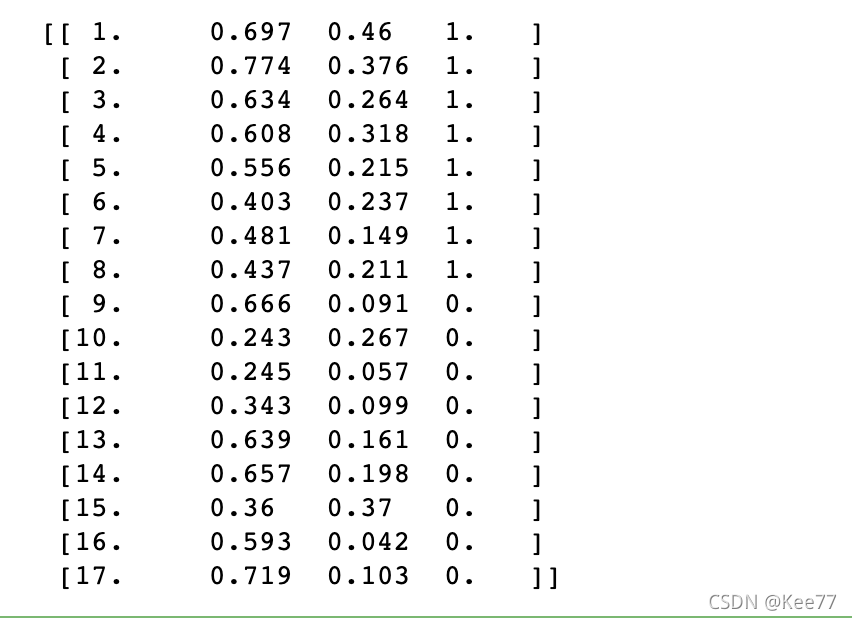
3.2.2数据处理
在数据处理这一步,需要将式2.2中的 x ^ i \hat{x}_{i} x^i和 y i y_{i} yi以矩阵的形式从数据集中分离开来。注意: x ^ i = ( x i ; 1 ) \hat{x}_{i}=(x_{i};1) x^i=(xi;1)
X = data[:,1:3] # 取数据集中的密度和含糖率两列
y = data[:,3:] # 取数据集中的好瓜判断一列
X0 = np.ones(np.shape(X)[0]) # 生成相同行数的数据1
X = np.c_[X, X0.T] # 生成矩阵(xi, 1)
生成的 x ^ i \hat{x}_{i} x^i矩阵如图所示

生成的 y i y_{i} yi矩阵如图所示
3.2.3模型训练
def gradient_function_l(beta_T_X, X, y):"""对数几率回归模型中需要优化的函数l(β)的一阶导数"""p1 = np.exp(beta_T_X) / (1 + np.exp(beta_T_X))return -np.sum(X * (y-p1), axis=0, keepdims=True)def gradient_descent(tranning_times=500):"""梯度下降法求解函数l(β)最优时的β值"""dataset_n = np.shape(X)[0]# 设置步长为0.01alpha = 0.01# 初始化beta值beta = np.zeros((1,3))for i in range(tranning_times):# (x, beta)beta_T_X = np.dot(X, beta.T)# 计算梯度gradient = gradient_function_l(beta_T_X, X ,y)# 更新beta值beta = beta - alpha * gradientreturn beta
在这里笔者主要用python实现了使用数据集对对数几率回归模型进行训练,求出式2.2最小时的参数 β \beta β的值。
3.2.3模型展示
最后将训练得到的参数 β \beta β代入线性回归模型产生预测值
w1, w2, b = gradient_descent().tolist()[0]def function_y(x):return (-b-w1*x)/w2y_0 = y==0
y_1 = y==1plt.title('watermelon_dataset')
plt.xlabel('density')
plt.ylabel('sugar content')
plt.scatter(X[y_0[:,0],0], X[y_0[:,0], 1], label = 'low quality')
plt.scatter(X[y_1[:,0],0], X[y_1[:,0], 1], label = 'high quality')
left_point = function_y(0.1)
right_point = function_y(0.9)
plt.plot([0.1, 0.9], [left_point, right_point], label='y', color='green')
plt.legend(loc="upper left")
plt.show()
在这里笔者令线性回归模型 y = ω x + b = 0 y = \omega x+b=0 y=ωx+b=0, 并绘制出该线。在该线之上, 则表示该点代入线性回归模型预测值大于0, 分类为正例。在该线之下,则表示该点代入线性回归模型预测值小于0, 分类为反例。
使用梯度下降法做模型训练, 得到的分类结果如图所示:

总结
本文详细介绍了梯度下降算法的内容与知识点,以及使用python求解对数几率回归模型参数最优解的过程。作为在学习周志华老师《机器学习》一书中的读书以及实践笔记, 其中包含笔者对该内容的主观理解,若有错误之处,望读者指出。
参考文献
机器学习-周志华
泰勒公式-维基百科
梯度下降法-维基百科
对数几率函数(logistic function)-维基百科
这篇关于机器学习笔记(二)梯度下降法实现对数几率回归(Logistic Regression)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





