本文主要是介绍用合成数据训练语义分割模型【裂缝检测】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近,我们推出了合成裂缝分割数据集,在本文中,我们将深入探讨应用于合成数据生成过程的改进和启发式方法。 阅读完这篇文章后,你将了解我们如何设法创建一个数据集,该数据集可以像使用真实数据一样高效地训练模型。

在线工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器
1、数据集创建过程的快速回顾
让我们回顾一下我们在本文中详细讨论的合成数据集创建过程的总体思路。
我们首先收集现实世界的纹理,例如沥青、墙壁和混凝土。 想象一下你在这些纹理上绘制裂缝,就像在绘画程序中使用画笔一样。 然而,这仅仅是开始。 我们将更进一步,使用一些合成和后处理技术将这些绘制的裂缝转换为真实的裂缝。 在以下部分中,我们将更深入地探讨合成和后期处理的世界。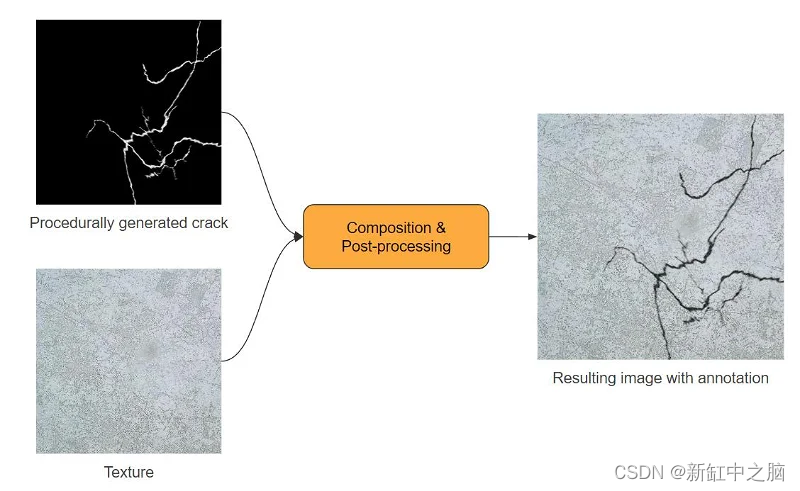
2、以数据为中心 vs. 以模型为中心
在机器学习和人工智能领域,增强模型性能主要有两种理念:以数据为中心和以模型为中心的方法。 以模型为中心的方法主要集中于改进模型的架构、大小和训练技术。 相反,以数据为中心的理念强调提高训练数据的质量、多样性和相关性。 基本信念是,即使模型的架构保持不变,卓越的数据也会带来卓越的模型。 在此背景下,我们坚持以数据为中心的方法。 在整个实验过程中,我们保持相同的模型架构、模型大小和超参数。 你可以在本文的结论部分找到有关架构和培训的详细信息。
让我们探索所有用于创建合成数据的逐步增强和启发式方法,这些数据能够训练与真实数据训练的模型相当的模型。
3、合成数据生成器
生成器是我们合成数据创建过程的核心。 生成器的设计应能够模拟实际裂缝的复杂且多样的结构。 这种初步的表示作为进一步处理和细化的基础,使合成图像更接近现实。
我们发现3种不同类型的算法的组合可以很好地充当生成器: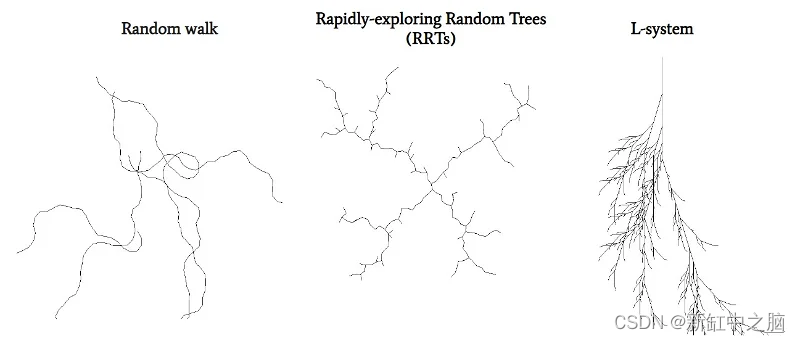
生成器
通过合并这些图案并按顺序分层,我们可以为预期裂缝生成复杂多样的结构。 生成器的输出由白色背景上的 1 像素轮廓组成,作为后续处理的蓝图。 对于随机游走,我们采用了逐渐改变的厚度来增强数据的多样性。
可以点击这里阅读有关每种算法的更多信息。
4、膨胀和腐蚀
首先,我们需要增加线条的粗细。 在 python 中,我们使用 cv2.dilate 来实现此目的。 需要调整一些参数,例如迭代次数、内核和 kernel_size。 我们将它们保持在某个随机范围内以增加多样性。 内核也可能是随机的。
腐蚀
我们想以某种方式破坏线路,可以使用 ImgAug 中的 iaa.ElasticTransformation:
弹性变换
我们还应用 iaa.PiecewiseAffine 来进一步扭曲图像:
逐点仿射变换
第一次训练:此时,生成的图像可能看起来相当令人信服,但在训练一个好的模型时,我们通常需要更高水平的真实感,尤其是在细节方面。 我们尝试过在此类图像上训练模型,但它立即过度拟合,导致在真实图像上表现不佳。
5、边缘平滑
经过仔细检查,很明显我们的裂缝呈现出切入背景的锋利边缘线。 这种细节级别对于训练模型来说可能显得人为,可能导致过度拟合,即模型在合成数据上表现完美,但在真实数据上表现不佳。 值得注意的是,这种细节水平虽然对人眼来说并不明显,但可能会给模型的泛化带来挑战。 为了缓解这个问题,我们以一定的概率应用 iaa.GaussianBlur 和 iaa.MotionBlur 的组合,为裂缝引入模糊效果: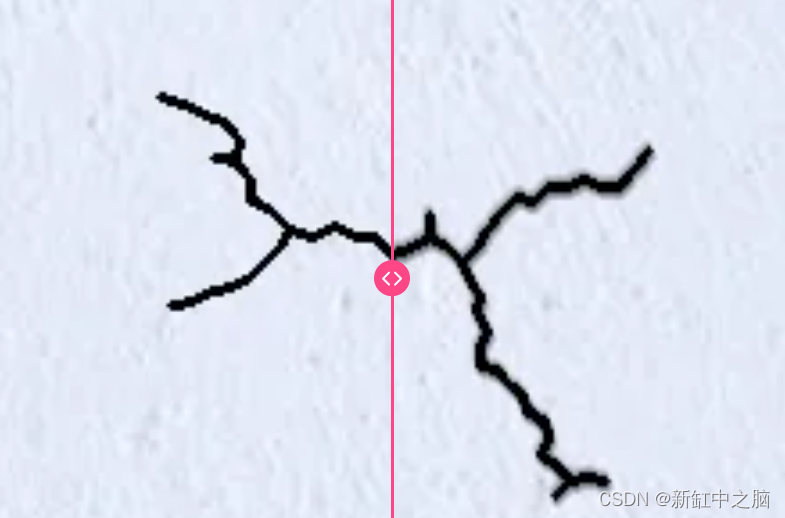
没有边缘平滑(左),有边缘平滑(右)
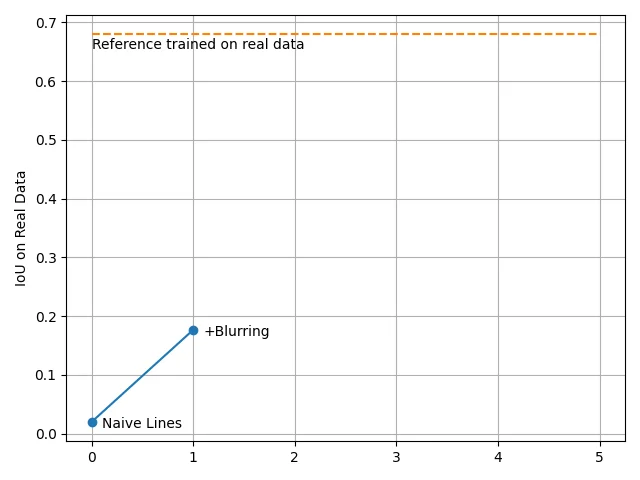
通过这个小技巧,我们成功地训练了一个没有过拟合的模型,但是真实图像上的 IoU 仍然远未达到令人满意的值:
6、轮廓纹理
目前,我们的线条采用鲜明、无瑕疵的黑色,与现实中的外观相去甚远。 我们的目标是为这些线条注入更丰富、更难以预测的质感。 这是我们发现的一个巧妙的技巧:我们偶尔会在生成器的裂缝上方添加一些模糊的噪点(即 1 像素线),而不是扩大线条。 这种噪声与 iaa.ElasticTransformation 的组合溶解了裂缝的像素,将它们展开,并且裂缝在不使用膨胀的情况下变得更厚。

轮廓纹理
7、上色
继续增强线条纹理,我们将为它们注入随机的深色阴影,并撒上一点杂色。 这个调整确保我们的裂缝不仅仅是平坦的。 这种变化肉眼几乎察觉不到,但对于模型来说可能很重要。 以下是一些值得注意的例子:

上色
在这一步训练模型进一步提升了性能:
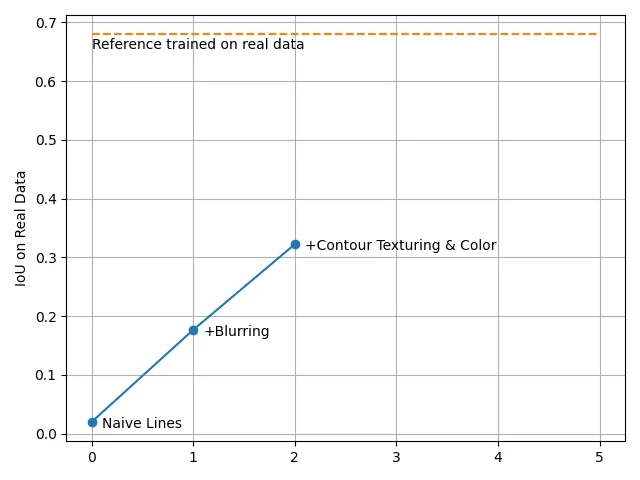
8、调整参数随机化
在我们的实验中,不断出现一个问题:我们如何确定噪声水平、线条粗细或模糊强度等参数的最佳值? 我们彻底检查了在每个参数选定范围的最高和最低极端情况下生成的图像。 在审查这些边缘案例时,我们偶尔会允许结果显得有些不切实际,超出了现实的范围。 这种方法有助于开发更具弹性和更有效的模型。
9、为什么假图像有用?
在研究中,特别是在机器人学中,这种技术称为域随机化(domain randomization)。 从本质上讲,域随机化是通过使其训练环境多样化来使模型具有适应性,而不是完善该环境的真实性。 我们的想法不是试图使合成数据完全真实(这是非常具有挑战性的),而是将合成数据的各个方面随机化,尤其是那些很难自然化的数据。 通过将模型暴露在大量不同的场景中,即使它们单独存在并不总是“现实”,模型也能学会更好地概括。
为什么它有效?
让我们面对现实吧,我们的合成数据并不能完全体现我们所追求的真实性。 然而,通过在我们的合成数据集中注入更多的多样性,我们可以训练一个擅长处理许多不同情况的模型。 经过无数随机领域的训练后,现实世界变成了模型的另一种变体。 本质上,它是关于训练模型以期待意外情况!
10、通过风格迁移提高数据多样性
了解多样性在我们的数据集中发挥的关键作用,我们现在正在探索一种令人兴奋的方法:风格迁移。 风格转移是一种将一个图像的风格(称为“风格图像”)转移到另一个图像(称为“内容图像”)的技术。 目标是产生一个保留原始图像内容但具有风格图像艺术风格的新图像。 现在,如果我们将生成的裂纹图像之一并使用背景图片作为“样式图像”,则样式迁移的结果将如下所示:
选择特定的风格迁移模型不是我们主要关心的问题,因为我们的目标不是现实主义。 我们的目标只是在视觉上改变裂纹图像,同时保持相同的分割掩模(或地面实况)。 在我们的测试中,我们使用了 PaddlePaddle 中的任意风格迁移模型 。
我们再次训练模型,发现风格迁移显着提高了性能。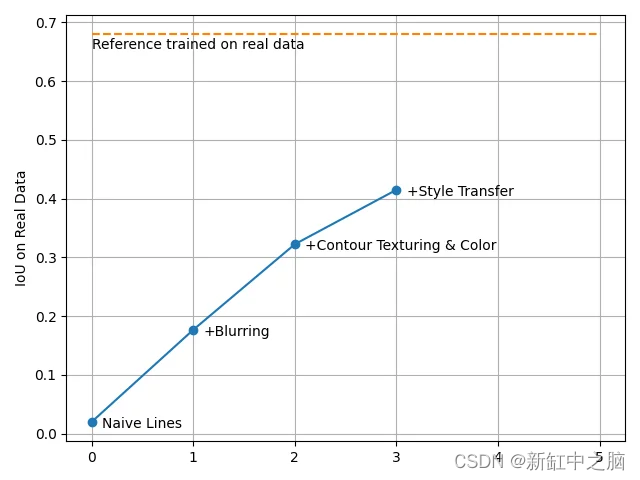
11、增强纹理的多样性
在这项研究开始时,我们的主要目标是分割道路裂缝。 这意味着我们的基础背景纹理主要由深色沥青组成。 为了增强模型的多功能性,我们引入了一系列新背景。 这些材料涵盖多种材料,包括混凝土、墙壁、瓷砖、砖块、大理石等。
这次扩张提出了新的挑战。 随着浅色背景的引入,我们最初设计的深色、轮廓分明的裂缝与它们形成鲜明对比,这一点变得很明显。 例如,白色或明亮表面上的裂缝不应该像深黑线一样突出——它们需要更无缝地融合。 这促使我们通过调整裂缝的自适应亮度来改进我们的方法,确保它们在每种背景下都显得自然。
左:没有自适应亮度,右:自适应亮度
通过这些修改,我们重新训练了模型并进一步提高了性能。
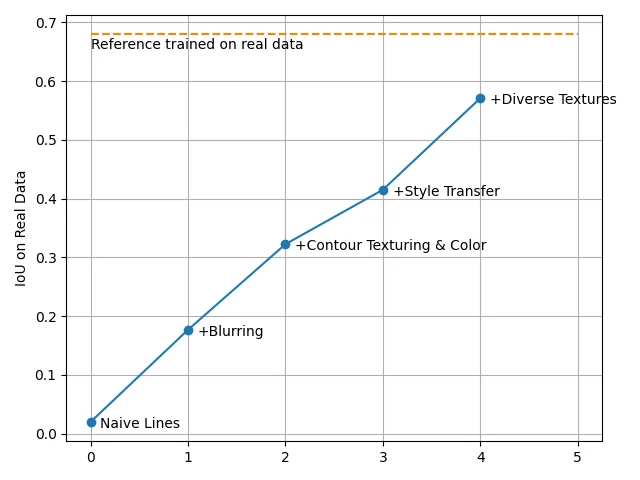
12、有效数据合成的关键考虑因素
总之,这里列出了需要你注意的数据合成的关键方面:
- 真实性,尤其是细节方面:确保合成数据在模式、变化和复杂性方面与现实世界的数据非常相似。 合成算法在创建细节时通常很粗糙。 这会导致数据中出现一些问题,这些问题对于人眼来说可能并不明显,但对模型至关重要,从而导致过度拟合和泛化不良。
- 多样性和变化:确保涵盖广泛的场景、条件和变化。 合成数据应包含尽可能多的潜在现实情况,以防止真实数据的过度拟合和不稳定的性能。
- 不完美和随机化:故意引入噪声、异常、模糊和失真,在极端情况下甚至可能看起来有点不切实际。 合成算法无法表达现实世界的所有复杂性和真实性,它们只能创建现实世界的简化和理想化版本。 因此,引入随机性和不完美性将有助于训练一个强大的模型,该模型可以在部署到现实场景中时处理意外或异常情况。
- 持续验证:定期根据真实数据验证合成数据。 这有助于揭示数据中可能妨碍模型良好泛化的问题。
13、结束语
经过一系列的实验,我们得到了一个值得注意的结果。 通过逐步完善我们的合成数据生成技术,我们有效地训练了一个模型,该模型的性能与专门针对真实世界数据训练的模型几乎相当。 在本博客系列的下一部分中,我们将介绍另一种使用合成数据进行训练的方法 - 该方法优于我们的参考模型。 这一部分将深入研究称为域适应的技术,进一步丰富我们的实验。
原文链接:用合成数据训练分割模型 - BimAnt
这篇关于用合成数据训练语义分割模型【裂缝检测】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






