本文主要是介绍R语言LDA、CTM主题模型、rjags 吉布斯gibbs采样文本分析论文摘要、通讯社数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近我们被客户要求撰写关于文本分析的研究报告,包括一些图形和统计输出。
摘要
主题模型允许对文档中的术语频率发生进行概率建模。拟合模型可用于估计文档之间以及一组指定关键字之间的相似性,这些关键字使用称为主题的额外潜在变量。R 包主题模型提供了基于文本挖掘包 tm 中的数据结构拟合主题模型的基本基础结构。
关键词: 吉布斯采样, R, 文本分析, 主题模型
1. 引言
在机器学习和自然语言处理中,主题模型是生成模型,它们为给定语料库中文档中的术语频率出现提供了概率框架。仅使用术语“频率”假定单词在文档中出现的顺序可以忽略不计。这个假设也被称为文档中单词的可交换性假设,这个假设导致了词袋模型。
2. 主题模型规范与估算
对于这两种模型(LDA 和 CTM),主题 k 的数量必须先验地固定下来。LDA 模型和 CTM 假设文档 w = (w1, . . , wN) 的以下生成过程,该文档包含来自由 V 个不同术语组成的词汇表中的 N 个单词,∈ 对于所有 i = 1, . . , N.
对于 LDA,生成模型由以下三个步骤组成。
步骤 1:术语“分布β由以下方式确定:

步骤 2:文档 w 的主题分布比例 θ 由下式确定

步骤3:对于N个单词中的每一个wi
(a) 选择一个主题 zi ∼ 多项式 (θ)。
(b) 从以主题 zi 为条件的多项式概率分布中选择一个词 wi:p(wi |子 , β)。
β是主题的术语分布,包含给定主题中单词出现的概率。
3. 应用:主要函数是LDA ()和CTM ()
包主题模型中用于拟合 LDA 和 CTM 模型的主要功能是 LDA() 和 CTM(),分别
LDA(x, k, method = "VEM", control = NULL, model = NULL, ...)
CTM(x, k, method = "VEM", control = NULL, model = NULL, ...)这两个函数具有相同的参数。x 是具有非负整数计数条目的合适文档术语矩阵,通常是从包 tm 获得的“文档术语矩阵”。
4. 示例:JSS论文摘要
在统计软件杂志(JSS)的摘要集合中进行了演示。
R> JSS_papers[, "description"] <- sub(".*\nAbstract:\n", "",
+ unlist(JSS_papers[, "description"]))为了结果的可重复性,我们仅使用截至2010-08-05发表的摘要,并省略摘要中包含非ASCII字符的摘要。
最终数据集包含 348 个文档。在分析之前,我们使用包tm将其转换为“语料库”。希腊字母,下标等摘要中的HTML标记使用包XML删除。
R> corpus <- Corpus(VectorSource(sapply(JSS_papers[, "description"],文档集使用函数文档术语矩阵从包 tm 导出到文档术语矩阵。使用控制参数对术语进行词干处理,并删除非索引字、标点符号、数字和长度小于 3 的术语。
R> JSS_dtm <- DocumentTermMatrix(corpus,R> dim(JSS_dtm)

包含此术语的文档上的平均术语频率-反向文档频率 (tf-idf) 用于选择词汇。
R> summary(col_sums(JS_dtm))R> summary(tem_tidf)R> summary(col_sums(J_dtm))


经过预处理后,我们有以下文档术语矩阵,其中包含减少的词汇量,我们可以使用它来适应主题m
R> dim(JSS_dtm)

在下文中,我们使用 (1) 具有估计α的 VEM、(2) 具有α固定的 VEM 和 (3) 具有 1000 次迭代的预烧的 Gibbs 采样以及记录 1000 次迭代的每 100 次迭代的 30 个主题的 LDA 模型。
在调查了性能后,我们将主题数量随意设置为30个,主题数量从2到200不等,使用10倍交叉验证。
为了比较拟合模型,我们首先研究拟合 VEM 的模型的α值,α估计的 VEM 和α固定的模型。
R> sapply(jss_TM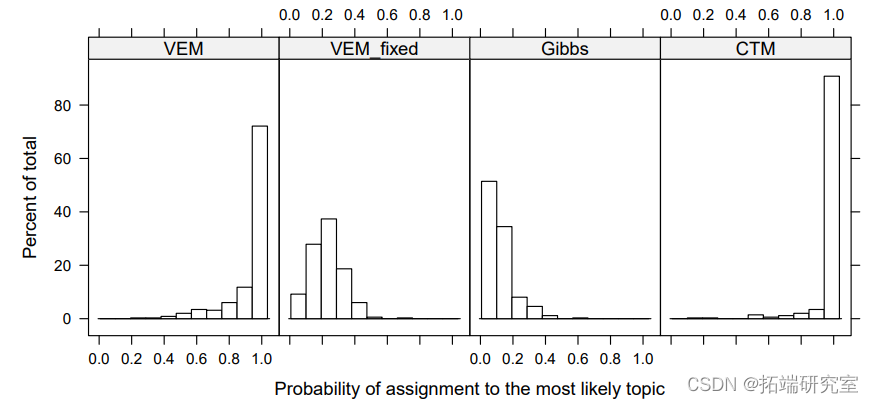
图 1:不同估计方法的所有文档分配到最可能主题的概率的直方图

我们看到,如果估计α,则将其设置为远小于默认值的值。
熵度量还可用于指示四种拟合方法的主题分布有何不同。

值越高,表示主题分布分布在主题上越均匀。文档的估计主题和主题的估计术语可以使用便利函数主题()和术语()获得。每个文档最可能的主题由以下公式获得
R> Topic <- topics(jss_TM[["VEM"]], 1)每个主题的五个最常用术语由下式获得:

如果文档的任何类别标签可用,则这些标签可用于验证拟合模型。
这些论文之间的相似性表现在以下事实中:大多数论文的主题与其最可能的主题相同。主题7的十个最有可能的术语由下式给出

显然,这个话题与特刊的一般主题有关。这表明拟合主题模型在不使用此信息的情况下成功地检测了同一特刊中论文之间的相似性。
5. 通讯社数据案例
在下文中,分析了1992年第一次文本检索会议(TREC-1)(Harman 1992)通讯社数据的子集。
R> dim(AssociatedPress)

它由2246个文档组成,词汇表已经被选中,只包含出现在超过5个文档中的单词。

该分析使用 10 倍交叉验证来评估模型的性能。
当折的值从 1, . . . 10 时,我们用三种不同的变体来估计模型。
主题数量从以下方面不等:
R> topics <- 10 * c(1:5, 10, 20)
对于α VEM,我们有:
对于固定α VEM:
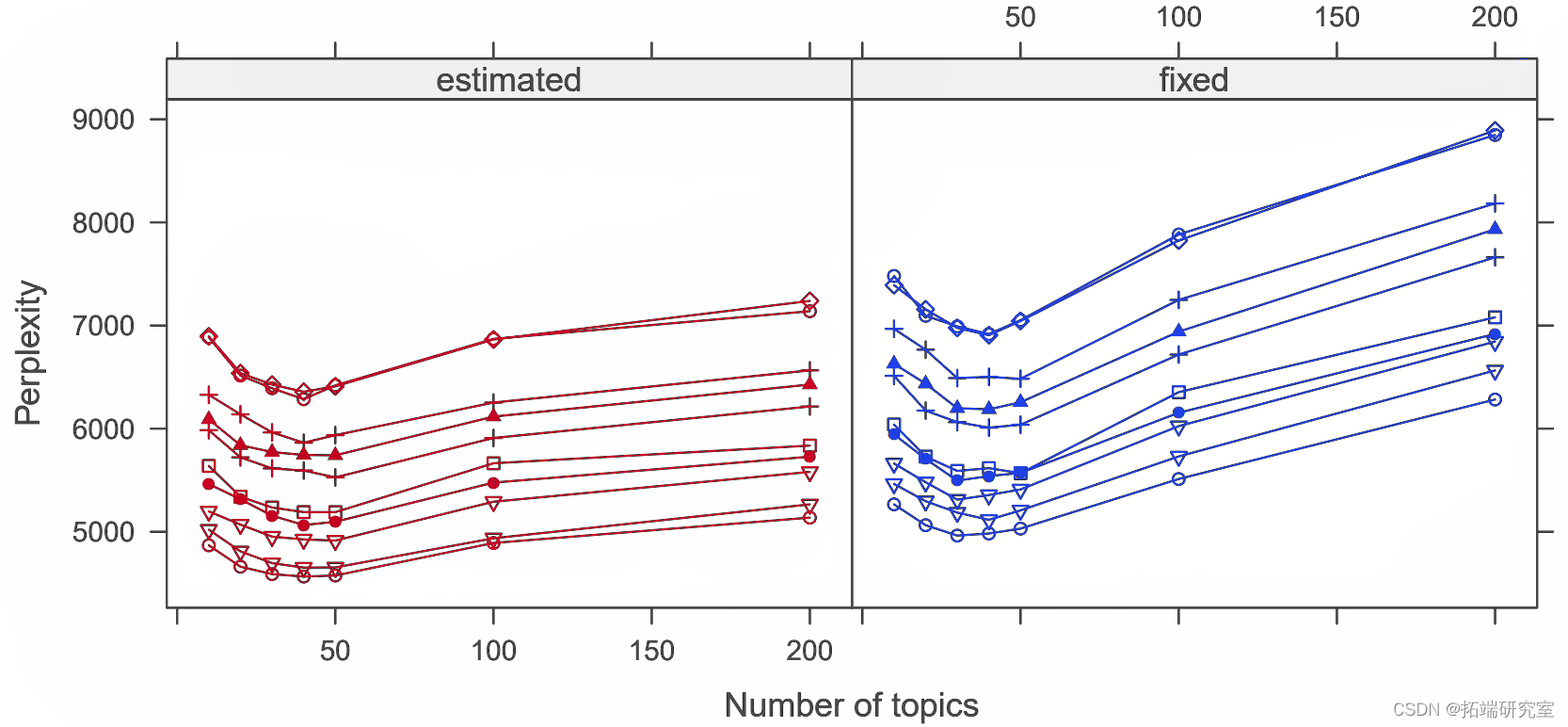
图 2:拟合 VEM 模型的测试数据的困惑。每行对应于 10 倍交叉验证中的一个折叠。
对于 Gibbs 采样,我们使用 1000 的预烧,然后是 1000 次抽取,并返回所有抽取
+ model = train[[which.max(sapply, train, logLik)]],
+ control = list(estimate.beta = FALSE, burnin = 1000, thin = 100,
图 2 给出了使用 VEM 拟合的模型的测试数据的困惑度。对于这两种估计方法,建议将大约40个主题作为最佳方法。VEM估计α值在左侧的图3中给出。显然,这些值比用作默认值 50/k 的值小得多。同样,请注意,较小的α值表示文档上的主题分布大部分权重位于角落。这意味着文档仅包含少量主题。对于使用 Gibbs 抽样拟合的模型,还通过确定测试数据的困惑来执行模型选择。右边的图 3 表明,大约 20-40 个主题是最佳主题。
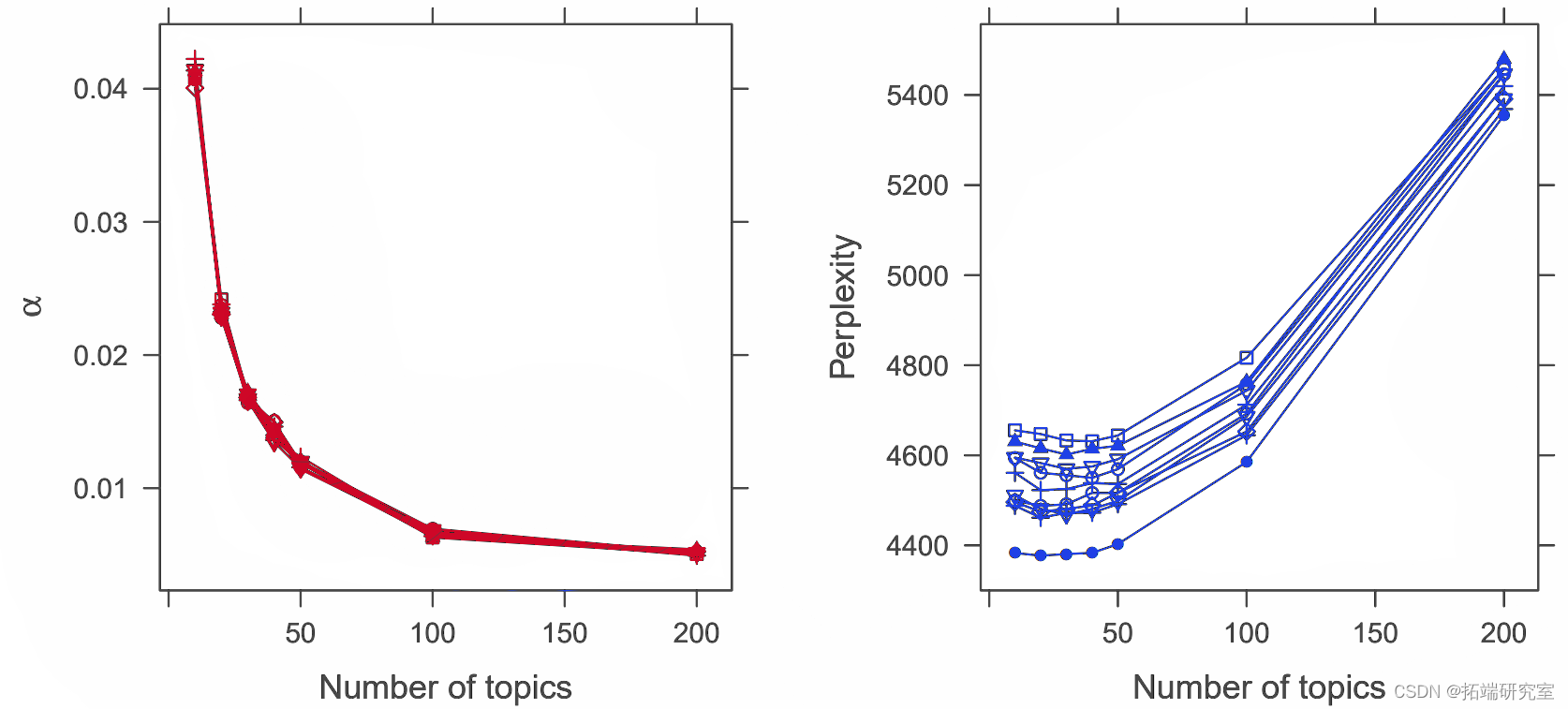
图 3:左图:使用 VEM 拟合的模型的估计α值。右图:使用吉布斯抽样拟合模型的测试数据的困惑度。每行对应于 10 倍交叉验证中的一个折叠
确定具有最小距离的最佳匹配,并相对于其八个最有可能的单词进行比较。
R> terms(AP$VEM, 8)[,best_match[1:4]]

这四个主题显然是关于同一主题的,并且由非常相似的单词组成。但是,主题之间的这种清晰对应关系仅存在于主题的一小部分中。图 4 中具有匹配主题的距离图像图也表明了这一点。根据图像,我们不会期望最差的四个匹配主题有很多共同点。通过检查每个主题的八个最重要的单词也可以看到这一点。


6. 扩展到新的拟合方法
包主题模型已经为 LDA 模型提供了两种不同的估计方法,为 CTM 提供了一种不同的估计方法。用户可以通过方法参数扩展方法并提供自己的拟合函数。在下文中,我们概述了如何使用包 rjags 来拟合 LDA 模型,使用具有不同实现的 Gibbs 采样。

图 4:解决方案的主题与 40 个 VEM 主题和 40 个 Gibbs 采样主题相匹配。
R> BUDEL <-
+ "model {
+ for (i in 1:length(W)) {
+ z[i] ~ dcat(theta[D[i],]);
+ W[i] ~ dcat(beta[z[i],]);
+ }
以下代码实现了一个新的方法函数,以使用带有包 rjags 的 Gibbs 采样来拟合 LDA 模型。在此用于拟合模型的函数中,未确定语料库中每个单词的对数似然以及最可能的主题成员身份,因此不是返回对象的一部分。
我们仅将新的拟合函数应用于通讯社数据的一小部分,并且仅执行 Gibbs 采样器的 20 次迭代,以限制所需的时间。所需的时间也与吉布斯采样器的LDA特定实现进行了比较。
R> terms(lda_rjags, 4)

从这个例子中可以看出,在包主题模型中添加新的估计方法需要编写一个合适的拟合函数。

这篇关于R语言LDA、CTM主题模型、rjags 吉布斯gibbs采样文本分析论文摘要、通讯社数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





