本文主要是介绍Paper Reading: High-level Semantic Feature Detection: A New Perspective for Pedestrian Detection,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Paper Reading Note
URL:
https://arxiv.org/pdf/1904.02948v1.pdf
TL;DR
本篇文章采用anchor-free的方法解决目标检测的问题。
作者认为可以用中心点和尺度这种high-level语义特征代替边缘、blob等low-level语义特征。
Algorithm
模型框架如下:

该算法主要分为Feature Extraction模块和Detection Head模块。
在Feature Extraction模块,作者采用的是Resnet-50(Pretrained on ImageNet),为了融合位置特征和语义特征,模型把每一个stage进行L2正则及反卷积后进行融合。
在Detection Head模块,作者使用256个33的卷积和分离的两个11卷积分别生成了Center Heatmap和Scale Map。
Loss Function

由于无法确定完全正确的中心点,作者用了Gaussian mask替代:
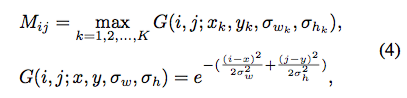

对于尺度的定义,采用了平滑L1 loss:
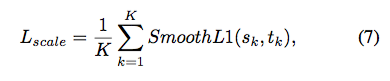
最后把Loss加权求和,权重由作者手动设定:
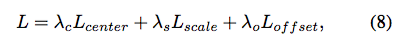
Experiment Detail
作者首先针对模型的选择参数进行了实验,最终发现选取后三层stage进行融合效果最好。
下面是与state-of-the-art模型比较的结果:
Caltech上

CityPerson上

效果基本都超过了现有方法。
Thoughts
该篇模型简单清晰,而且效果拔群。另外作者说会在不久后将代码开源,现有的github上有文档,但是代码还没有开源https://github.com/liuwei16/CSP。
还有就是行人检测的尺度是基本固定的,如果用到其他物体检测是否会产生偏差。
这篇关于Paper Reading: High-level Semantic Feature Detection: A New Perspective for Pedestrian Detection的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







