本文主要是介绍语音合成(TTS)论文优选:DeepSinger: Singing Voice Synthesis with Data Mined From the Web,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
声明:语音合成(TTS)论文优选系列主要分享论文,分享论文不做直接翻译,所写的内容主要是我对论文内容的概括和个人看法。如有转载,请标注来源。
欢迎关注微信公众号:低调奋进
DeepSinger: Singing Voice Synthesis with Data Mined From the Web
本文章是浙江大学和亚洲微软联合发表关于歌唱合成的文章,更新于2020.07.15,本文主要的贡献是如何使用网上爬取的数据来训练歌唱合成系统,具体的文章链接 https://arxiv.org/pdf/2007.04590.pdf
文章的demo链接
DeepSinger: Singing Voice Synthesis with Data Mined From the Web - Speech Research
1 背景
歌唱合成是一项非常有趣的研究,但歌唱合成的训练语料十分昂贵,往往获得较好的训练语料需要花费上百万的成本,因此很少有企业和研究所能够承担此种开销。歌唱合成训练语料相比普通语料的成本较高的原因:1)需要专业歌手在专业的录音棚录制高音质的干声;2)歌声的标注需要更复杂的信息,标注成本较高。为了解决数据的问题,本文是首次使用网络爬取的数据进行模型训练,总体效果还算不错,也为很多研究者提供思路。
2 详细设计
先来看一下DeepSinger整体的流程(图1所示):1)网上爬取歌曲和相应的歌词;2)使用Spleeter进行歌曲的歌声和伴奏的分离,获取干声;3)歌词和歌声之间的对齐,获取时长信息;4)进行数据筛选,获取较好的训练语料;5)歌唱合成系统的训练;

其中以上的五个步骤,本文主要讲解对齐设计和歌唱合成模型。对齐模型是使用encoder-attention-decoder的ASR模型,具体如图2所示,另外本部分的attention使用guided attention,具体如图3所示。本文通过attention的对齐情况来抽取时长。


本文的歌唱合成模型是在fastspeech系统上进行的修改,为了支持多人多语言的歌唱合成,具体的系统结构如图4所示:该部分的输入为phoneme + pitch + singer infomation (reference encoder)。推理阶段如图5所示,这里不再详细阐述。


3 实验
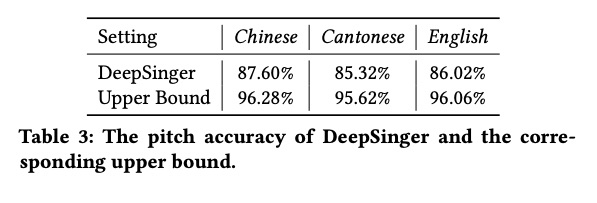
本文的实验数据是在中文,粤语和英文歌曲进行的实验,具体的数据信息见table 1所示。接下来将在客观和主观两个方面进行评估。table 2的客观指标显示合成三种语言歌曲在句子级别正确率都差不多大于80%,ASE都小于100ms。table3展示了基频准确率都大于85%,这种效果还是不错的。table 4 是MOS测试,由此可知,合成的音质相比于GT较低,但也可接受。table 5分别展示每个模块的影响,其中添加TTS数据可以很好帮助提高合成效果。table 6显示使用参考音频是否干净的影响效果。table7显示reference encoder的重要性。table8显示出本文提出的DeepSinger使用歌唱语料的效果。





4 总结
歌唱合成的训练语料十分昂贵,往往获得较好的训练语料需要花费上百万的成本,因此很少企业和研究所能够承担此种开销。为了解决数据的问题,本文是首次使用网络爬取的数据进行模型训练,总体效果还算不错,也为很多研究者提供思路。
这篇关于语音合成(TTS)论文优选:DeepSinger: Singing Voice Synthesis with Data Mined From the Web的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









