voice专题

Retrieval-based-Voice-Conversion-WebUI模型构建指南
一、模型介绍 Retrieval-based-Voice-Conversion-WebUI(简称 RVC)模型是一个基于 VITS(Variational Inference with adversarial learning for end-to-end Text-to-Speech)的简单易用的语音转换框架。 具有以下特点 简单易用:RVC 模型通过简单易用的网页界面,使得用户无需深入了

Easy Voice Toolkit - 简易语音工具箱,一款强大的语音识别、转录、转换工具 本地一键整合包下载
Easy Voice Toolkit 是一个基于开源语音项目实现的简易语音工具箱,提供了包括语音模型训练在内的多种自动化音频工具,集成了GUI,无需配置,解压即用。 工具箱包括 audio-slicer、VoiceprintRecognition、whisper、SRT - to - CSV - and - audio - split、vits 和 GPT - SoVITS 等。这些优秀

fast-voice-assistant
首先我们来到这个据说50行代码就可以创建个人语音助手的github地址GitHub - dsa/fast-voice-assistant: ⚡ Insanely fast AI voice assistant with <500ms response times 按照readme 完成环境的配置 but,你发现,这只是第一步,真正的难点在于完成.env中各个key的配置 1)Using th
iOS Alexa Voice Service SDK 编译之旅(2)
一切都开始于这里 1.Alexa SDK编译流程官网地址:https://developer.amazon.com/en-US/docs/alexa/avs-device-sdk/ios.html 2.Alexa SDK github源码官网地址:https://github.com/alexa/avs-device-sdk 一、Alexa的编译过程 编译流程中有一句话要

iOS Alexa Voice Service SDK 编译之旅(1)
AVS,即Alexa Voice Service,是亚马孙提供的名叫Alexa语音智能对话服务,和国内的小米的小爱同学、百度的小度、阿里巴巴的天猫精灵和谷歌的GoogleAssistant有相似的功能。相比于国内的针对中文的语音交互,AVS更适用于国外的英文语音交互逻辑,但是编译使用之复杂也是令人叹为观止,迄今(2020.4.9)为止,网上还找不到一个可用的、已经编译好的iOS
基于QCC上Google Voice Assistant功能实现
基于QCC上Google Voice Assistant功能实现 /*! \copyright Copyright (c) 2020-2022 Qualcomm Technologies International, Ltd. All Rights Reserved. Qualcomm Technologies International,

Windows下 webrtc voice engine 提示libyuv.lib找不到 或者
wertc 使用voice engine时,提示如下错误: 1>ManifestResourceCompile: 1> All outputs are up-to-date. 1>common_video.lib(webrtc_libyuv.obj) : error LNK2019: unresolved external symbol _NV12ToRGB565 refere
VoiceEngine之voice hardware Demo
Target: 利用webrtc voice engine 获取音频媒体设备信息 点击(此处)折叠或打开 #include "webrtc\voice_engine\include\voe_base.h" #include "webrtc\voice_engine\include\voe_hardware.h" #include "webrtc\voice_engine\in
音频筑基:200字说清声和音的区别(Sound/Audio/Music/Voice/Speech辨析)
音频筑基:200字说清声和音的区别(Sound/Audio/Music/Voice/Speech辨析) 音频筑基:200字说清声和音的区别 音频筑基:200字说清声和音的区别(Sound/Audio/Music/Voice/Speech辨析) 梳理如下: 声音 声(Sound) 广义:机械波产生的振动狭义:人耳可听到的振动(20-20kHz) 音(Audio) 有意义的声(滤去
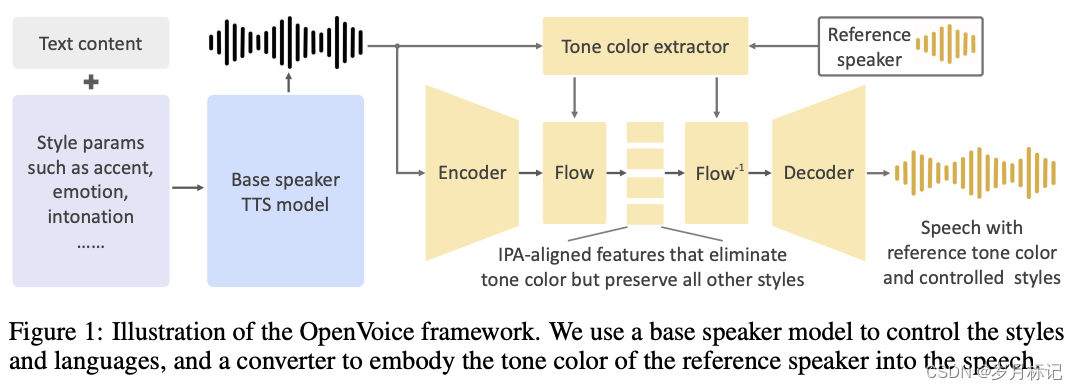
OpenVoice: Versatile Instant Voice Cloning
OpenVoice:多功能即时语音克隆 摘要 OpenVoice是一种多功能的即时声音克隆方法,它只需要参考说话者的一小段音频就可以复制他们的声音并以多种语言生成语音。OpenVoice 在解决以下领域中的开放性挑战方面代表了重大进展:1) 灵活的声音风格控制。OpenVoice 可以精细控制声音风格,包括情感、口音、节奏、停顿和语调,除了复制参考说话者的音色外。这些声音风格不会直接从参考说话
使用VOICE_CALL在Android5.0之后闪退bug源码解析
android4.4_r1版本AndroidRecord.java中源码如下 public More ...AudioRecord(int audioSource, int sampleRateInHz, int channelConfig, int audioFormat,209 int bufferSizeInBytes)210 throws Illegal
Pro T-SQL 2005 Programmer's Guide (Expert's Voice)
版权声明:原创作品,允许转载,转载时请务必以超链接形式标明文章原始出版、作者信息和本声明。否则将追究法律责任。 http://blog.csdn.net/topmvp - topmvp Pro T-SQL 2005 Programmer's Guide provides comprehensive and detailed coverage of all the major feature
华为设备Voice VLAN配置命令
[Huawei-GigabitEthernet0/0/1]voice-vlan 10 enable //指定VLAN是Voice VLAN,同时使能接口的Voice VLAN功能,缺省去使能 [Huawei-GigabitEthernet0/0/2]voice-vlan remark-mode mac-address //配置语音报文按照MAC地址提升优先级,缺省按照VLAN提升报文优先级 [Hu
voice of dprk
为甚么下面的网站不能直接访问? http://www.vok.rep.kp/ dprk是“友好邻邦”?! 所谓远交近攻,相邻的国家不太可能友好。 http://blog.jxcn.cn/u/yangchongwen/193803.html

OpenAI发布Voice Engine模型!用AI合成你的声音!
大家好,我是木易,一个持续关注AI领域的互联网技术产品经理,国内Top2本科,美国Top10 CS研究生,MBA。我坚信AI是普通人变强的“外挂”,所以创建了“AI信息Gap”这个公众号,专注于分享AI全维度知识,包括但不限于AI科普,AI工具测评,AI效率提升,AI行业洞察。关注我,AI之路不迷路,2024我们一起变强。 北美时间3月29日,OpenAI继续大秀肌肉,在一篇博客中发布并展

【论文学习】《Defending Your Voice: Adversarial Attack on Voice Conversion》
《Defending Your Voice: Adversarial Attack on Voice Conversion》论文学习 文章目录 《Defending Your Voice: Adversarial Attack on Voice Conversion》论文学习 摘要 1 介绍 2 相关工作 2.1 语音转换 2.2 声音的攻击与防御 3 方法论
VoIP(Voice over Internet Protocol 基于IP的语音传输)介绍(网络电话、ip电话)
文章目录 VoIP(基于IP的语音传输)1. 引言2. VoIP基础2.1 VoIP工作原理2.2 VoIP协议 3. VoIP的优势和挑战3.1 优势3.2 挑战 4. VoIP的应用5. 总结 VoIP(基于IP的语音传输) 1. 引言 VoIP,全称Voice over Internet Protocol,也就是通过互联网进行语音通信或多媒体会话的技术。这种技术已经引起
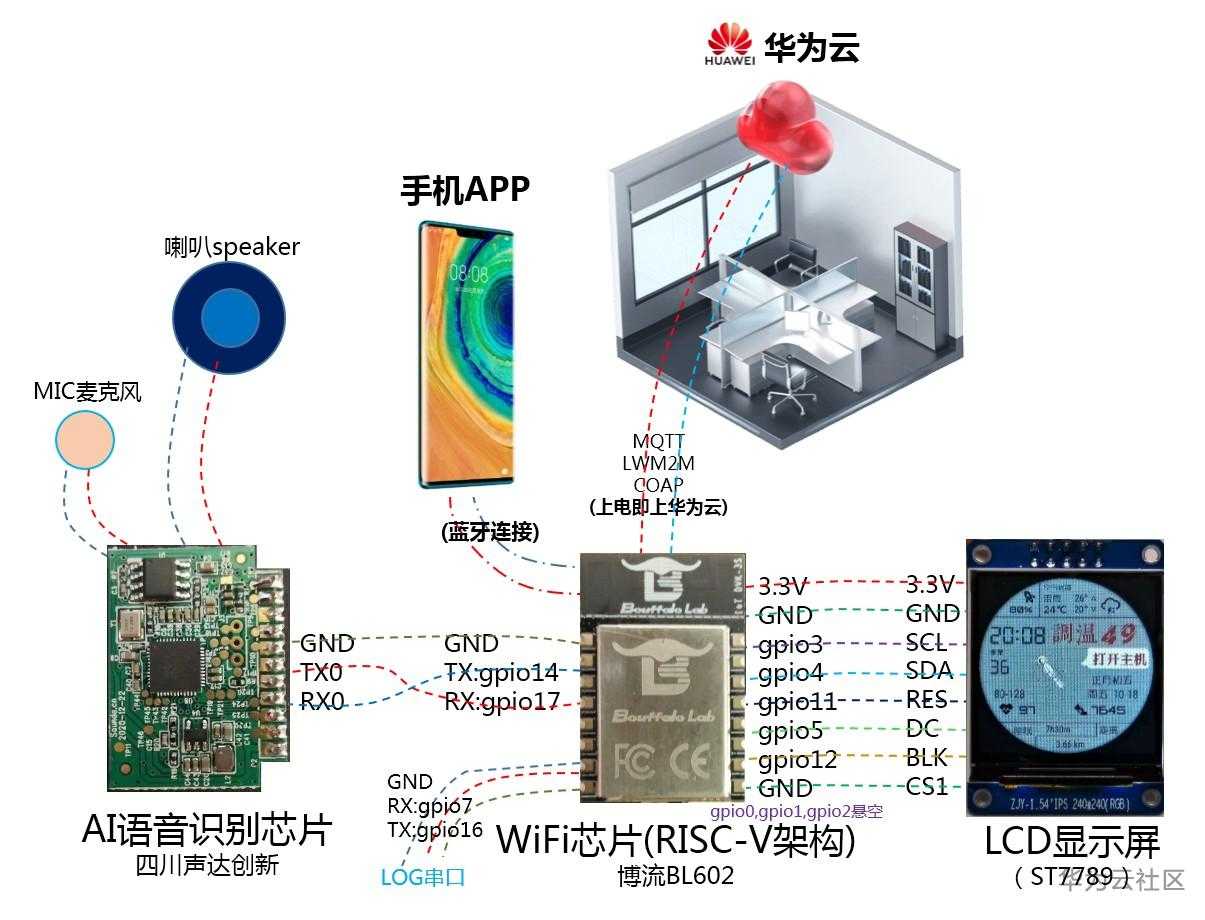
【上电即上华为云】华为云smart语音识别_AI_Voice_wifi_RISC-V_LCD_ST7789
【摘要】 语音识别将改变我们的生活!!!应用场景上有很多想象空间,产品经过语音改造后让人耳目一新,定制多国语言可打造全球爆款产品。本文实现一款smart语音识别案例,由AI语音识别芯片、WiFi芯片(RISC-V,含蓝牙)、LCD显示屏构成,当然更重要的是上电即上华为云。 华为云smart语音识别_AI_Voice_wifi_RISC-V_LCD_ST7789:上电即上华为云 一句话总
![Unity文字转语音(使用RT-Voice PRO [2023.1.0])](https://img-blog.csdnimg.cn/20201221182711272.png)
Unity文字转语音(使用RT-Voice PRO [2023.1.0])
参考文章Unity插件——文字转朗读语音RtVioce插件功能/用法/下载_rtvoice-CSDN博客 一、使用步骤 1.导入进Unity(插件形式为 .unitypackage) https://download.csdn.net/download/luckydog1120446388/88717512 2.添加所需Prefab 1).右键可以直接添加到 Hierarchy面板 2
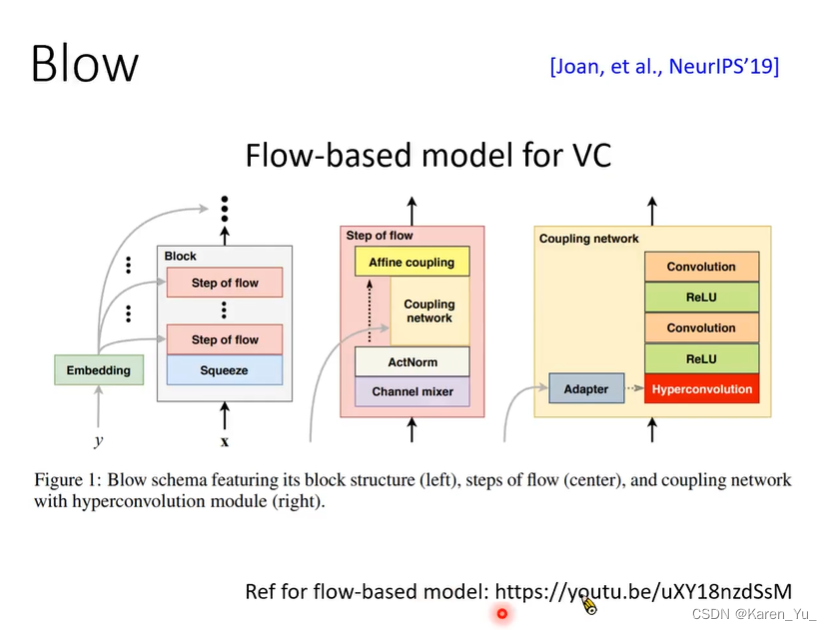
李宏毅 自然语言处理(Voice Conversion) 笔记
前一章笔记:李宏毅 自然语言处理(Speech Recognition) 笔记 引入 什么是voice conversion? 输入一段声音,输出另一段声音,我们希望这两端声音:内容一样,其他方面不一样(这个其他方面最常见的是:说话的人,比如领结变声器)。 为什么要变成另一个人说呢?同一句话,不同人说的效果是不一样的;还可以拿来骗人(什么一天一个入 狱 小 技 巧);还可以做个
OpenAI再次与Altman谈判;ChatGPT Voice正式上线
11月22日,金融时报消息,OpenAI迫于超过700名员工联名信的压力,再次启动了与Sam Altman的谈判,希望他回归董事会。 在Sam确定加入微软后,OpenAI超700名员工签署了一封联名信,要求Sam和Greg Brockman(前董事会主席)回归,不然就追随他们加入微软新成立的子公司。 签署该联名信的就包括被怀疑是整个事件的幕后策划人,OpenAI联合创始人兼首席科学家Ilya

语音端点检测(voice activity detection VAD)综述+论文百篇(195*~2019)
能量 短时过零率 自相关 pitch G.729B AMR opt 1/2 深度学习 bDNN 基于听觉机制 Method Feature Concept Work Environment G.729B VAD [6, 24] linear spectrum frequency, zero crossing rate, full band signal energy,

Voice Control for ChatGPT简单高效的与ChatGPT进行交流学习。
快捷又不失灵活性 日常生活中,我们与亲人朋友沟通交流一般都是喜欢语音的形式来完成的,毕竟相对于文字来说语音就不会显的那么的苍白无力,同时最大的好处就是能解放我们的双手吧,能更快实现两者间的对话,沟通便更高效了。 Voice Control for ChatGPT允许您与 ChatGPT 进行语音对话。它在输入字段下方添加了一个按钮,可让您录制语音并将问题提交给 ChatGPT。这使得与智能对话

语音合成(TTS)论文优选:DeepSinger: Singing Voice Synthesis with Data Mined From the Web
声明:语音合成(TTS)论文优选系列主要分享论文,分享论文不做直接翻译,所写的内容主要是我对论文内容的概括和个人看法。如有转载,请标注来源。 欢迎关注微信公众号:低调奋进 DeepSinger: Singing Voice Synthesis with Data Mined From the Web 本文章是浙江大学和亚洲微软联合发表关于歌唱合成的文章,更新于2020.07.15,
voice 和token 互相转
voice 和token 互相转 解释代码 解释 这段代码实现了一个将音频数据转换为 token 列表,并将 token 列表转换回音频的转换过程。以下是代码的主要步骤: 导入所需的库,包括 paddle、numpy、tqdm 和 glob。 定义一个名为 read_and_gen_token 的函数,该函数接受一个音频文件名作为输入,并将其转换为 token 列表。 在 re
voice 和token 互相转
voice 和token 互相转 解释代码 解释 这段代码实现了一个将音频数据转换为 token 列表,并将 token 列表转换回音频的转换过程。以下是代码的主要步骤: 导入所需的库,包括 paddle、numpy、tqdm 和 glob。 定义一个名为 read_and_gen_token 的函数,该函数接受一个音频文件名作为输入,并将其转换为 token 列表。 在 re