本文主要是介绍OpenVoice: Versatile Instant Voice Cloning,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
OpenVoice:多功能即时语音克隆
摘要
OpenVoice是一种多功能的即时声音克隆方法,它只需要参考说话者的一小段音频就可以复制他们的声音并以多种语言生成语音。OpenVoice 在解决以下领域中的开放性挑战方面代表了重大进展:1) 灵活的声音风格控制。OpenVoice 可以精细控制声音风格,包括情感、口音、节奏、停顿和语调,除了复制参考说话者的音色外。这些声音风格不会直接从参考说话者那里复制并受到限制。以前的方法在克隆后缺乏灵活操控声音风格的能力。2) 零样本跨语言声音克隆。OpenVoice 实现了对大型发言者训练集中未包括的语言的零样本跨语言声音克隆。与通常需要针对所有语言的庞大的多语言发言者数据集的以往方法不同,OpenVoice 可以在没有任何该语言的大型发言者训练数据的情况下克隆声音到新的语言。OpenVoice 在计算上也高效,成本是商业可用 API 的数十倍以下,而且性能还不如商业 API。为了促进该领域的进一步研究,作者已经公开了源代码和训练好的模型。作者还在演示网站上提供了定性结果。在公开发布之前,内部版本的 OpenVoice 在 2023 年 5 月到 10 月期间被全球用户使用了数千万次,作为 MyShell.ai 的后端服务。
1. 引言
文章的引言部分强调了文本到语音(TTS)合成中即时声音克隆(IVC)的重要性。IVC允许模型在没有额外训练的情况下克隆任何参考说话者的声音。这种功能在多种现实世界的应用中具有极高的价值,例如媒体内容创建、定制聊天机器人和人机交互等。
2. 方法
这部分首先展示了OpenVoice的直观设计思想,然后详细阐述了模型结构和训练过程。包括:
- 2.1 直觉:描述了同时克隆任何说话者的声音色彩、灵活控制所有其他风格,并轻松添加新语言的挑战和解决方案。
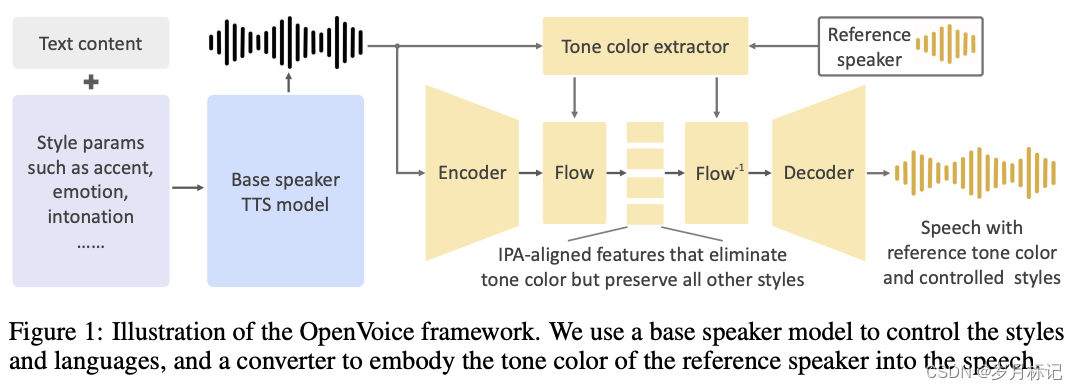
- 2.2 模型结构:介绍了OpenVoice的两个主要组成部分——基础说话者TTS模型和声音色彩转换器。这种结构使得声音风格和语言的生成不依赖于声音色彩的生成,从而实现了高度的灵活性。
- 2.3 训练:讨论了基础说话者TTS模型和声音色彩转换器的训练过程,包括使用的数据集和训练目标。
3. 实验
本节讨论了声音克隆的客观评估难度,并重点分析了OpenVoice自身的定性表现。文中提供了一些测试结果和用户可以自由评估的公开音频样本。
4. 讨论
讨论部分总结了OpenVoice在声音样式和语言灵活性方面相比以往方法的优势,并强调了该方法的设计哲学——将声音色彩克隆与其他声音样式和语言的生成解耦,为未来研究的推进提供了代码和模型权重的公开访问。
这篇关于OpenVoice: Versatile Instant Voice Cloning的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!