本文主要是介绍李宏毅 自然语言处理(Voice Conversion) 笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前一章笔记:李宏毅 自然语言处理(Speech Recognition) 笔记
引入
什么是voice conversion?

输入一段声音,输出另一段声音,我们希望这两端声音:内容一样,其他方面不一样(这个其他方面最常见的是:说话的人,比如领结变声器)。


为什么要变成另一个人说呢?同一句话,不同人说的效果是不一样的;还可以拿来骗人(什么一天一个入 狱 小 技 巧);还可以做个人化的语音合成系统;歌声转换(这个今年还蛮常见的,经常在B站刷到《假如xxx唱xxx》);隐私保护(声音里有很多信息,虽然这个例子没有见过,但是B站上确实看到有人通过一张照片推测拍摄地点,还蛮震惊的。老师举的例子就是可以搞那种把小孩子的声音转换成父母的声音的对讲系统,这样外面按门铃的人就觉得有父母在家这个样子)。

还可以做speaking style的转换。可以改变说话的情绪(比如人说话很温柔,即使生气听起来也不严重);把正常的声音转化成Lombard的声音(听老师给的例子,有点类似于我们平常打电话和在嘈杂的环境里打电话的区别,不仅仅是音量变化,听起来有点像喊);把呓语转化成正常的声音(比如在图书馆/其他不适合大声说话的场所打电话,让电话另一段听正常的声音);唱歌技巧up

增进一段声音的可理解性。比如有人说话不清楚(比如有小朋友啊老人啊说话会比较黏黏的听不清楚),或者是口音上的不好理解。保留说话的人的特性,但是更好懂。
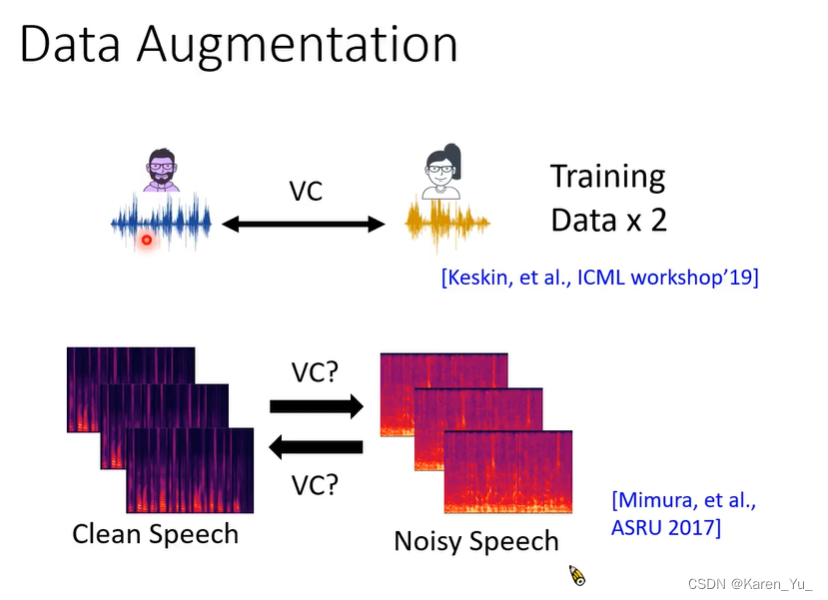
做data augmentation。把男生和女生的声音互相转化,这样就多了一倍的数据;把干净的声音转化成有噪声的声音,或者反过来

需要说明,在voice conversion的时候,输入和输出的长度可以是不一样的(甚至不一样更好,不同的口音说一句话的长度不一样很正常)。但是在很多文献中都采用输入和输出相同(这样能让模型简单一些,不需要用seq2seq)。
输出也是acoustic feature sequence,但是这一串向量往往不能直接转化成声音信号。假设这一串向量是一个spectrumgram,转成声音信号还差一个phase(相位)。需要另外一个model做vocoder,吃acoustic feature当做输入,直接输出声音信号。这里vocoder可以采用传统的信号处理的方法(不见得能得到好的结果,我们在听合成的时候听到的那种假假的声音往往就是这里的问题),也可以用DL。
在本章节中不会涉及到怎么把acoustic feature转化成声音信号,只是得到acoustic feature(因为这一方法并不是仅仅用于voice conversion)

voice conversion可以按照训练资料分为两类。
成对的资料:
我们很难收集到大量的成对的资料。可以采用比较好的pre-train的model。先把seq2seq的model pre-train好,再用少量的资料去fine-tune。也可以采用语音合成的方法(这里举例是让谷歌把别人说过的话再说一遍,这样就可以得到一个把所有人说的话都转化成谷歌声音的model)。
不成对的资料:
每个说话的人说的内容甚至说的语言都是不一样的,让model把一个人的声音转化成另一个人的声音。
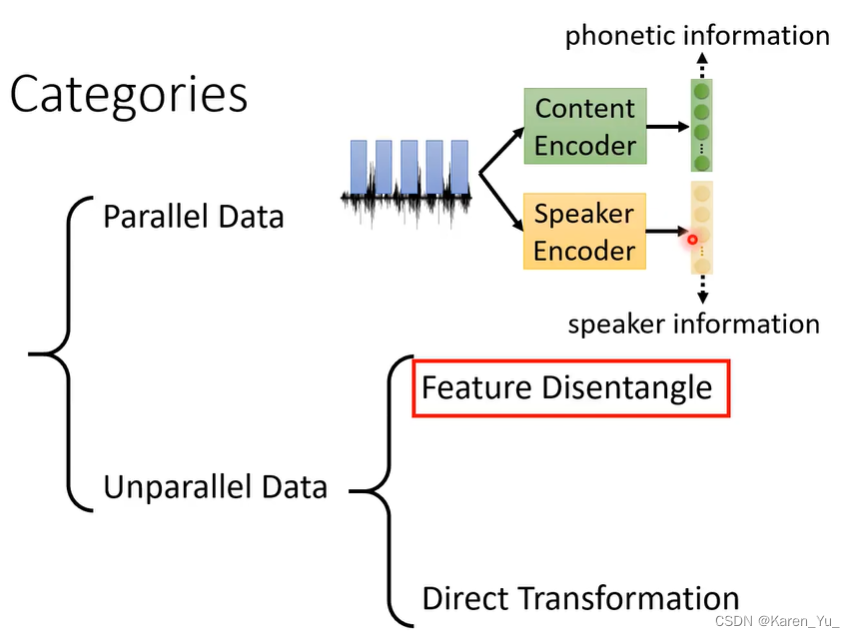
这里有两个方法:feature disentagle&direct transformation。
Feature Disentangle
feature disentangle:声音信号中包含了很多维度的信息,可能包含了内容的信息(文字),说话人的信息,背景的信息。feature disentagle要做的就是把这些混在一起的信息分开。我们不仅仅可以把说话人的信息提取出来,替换,我们也可以把情绪/口音的部分提取出来进行替换。在之后的例子中都只涉及到speaker的转换,但是应注意到其实都可以转化。
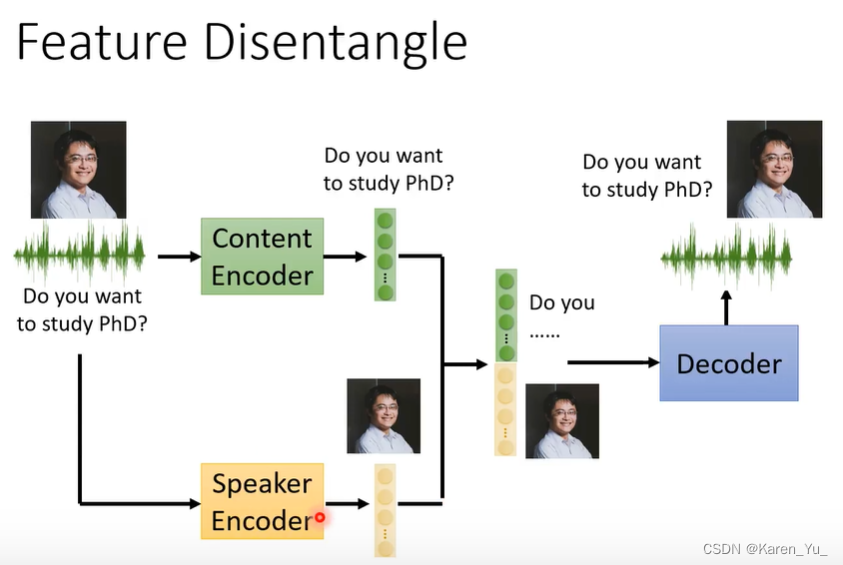
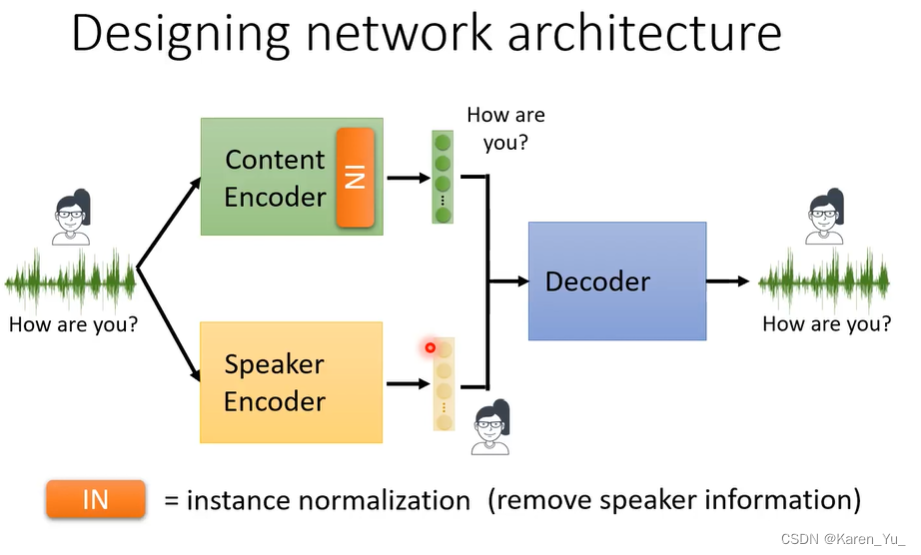
content encoder把只和文字内容有关的部分提取出来,speaker encoder得到一句话,忽略内容,只把与speaker特征有关的部分提取出来。接下来需要一个decoder,会根据两个特征念出来这句话的内容。

这样,只要吧speaker encoder这边的特征替换成别人说话的特征就能得到其他人说这句话的语言。

我们希望不同的encoder抽取的是不同的信息。
但是我们怎么确保一个encoder只抽content,一个encoder只抽speaker呢?如果只是像一般的autoencoder那样end-to-end的train,输入一段声音信号,中间输出什么也不管,直接吧中间输出的转回声音信号,没道理content encoder和speaker encoder就按照我们的要求提取信息。->加一些额外的东西。

在训练的时候,我们知道每句话是谁说的,那就不用speaker encoder了,每一个speaker就是由一个one-hot vector表示,比如:如果是speakerA,对应的speaker的code就是10,如果是speakerB就是01。
但是也存在问题:没有办法合成出新的speaker的声音
有几个不同的speaker就要开响应长度的向量(one-hot),假设训练资料中有10个speaker,就需要长度为10的向量,如果我们现在来一个新的speaker,就要重新训练模型,用原来的模型没办法合成第十一个人的声音。

解决方法还可以是提前训练好一个speaker encoder(输入一段声音信号,输出一个向量,这个向量代表了speaker的特征)。

怎么确保content encoder抽出来的就只和文字内容有关呢?->常见的方法,直接把一个语音识别系统塞在content encoder这里,当做content encoder来用。
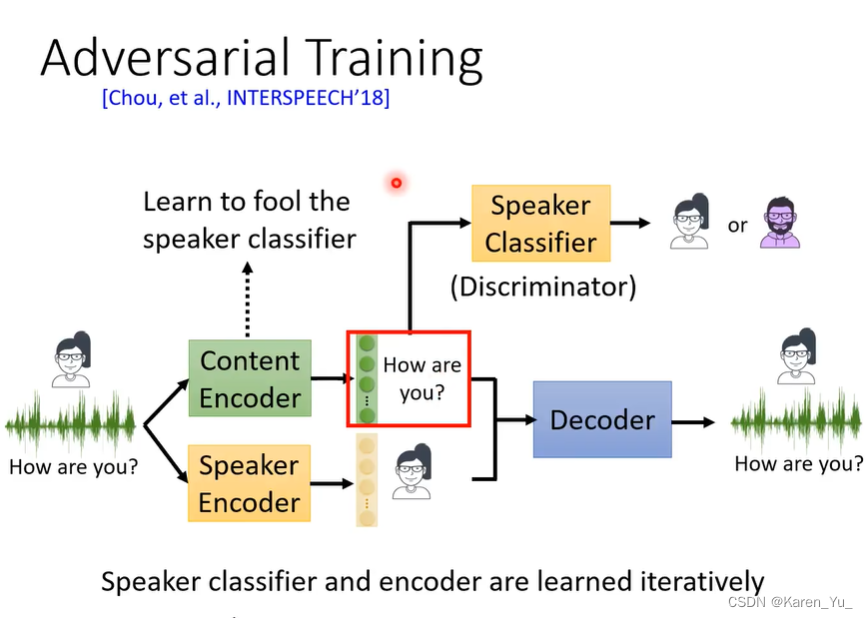
其他方案:加上GAN,让content encoder不要encode speaker的信息。可以train一个discriminator,作为一个speaker classifier,判断向量来自于哪个speaker。而content encoder要做的就是想办法去骗过这个speaker classifier。speaker classifier和content encoder是交替训练的。希望content encoder可以成功的骗过speaker classifier->代表content encoder的输出没有带有speaker的任何信息。

实际上,我们可以通过设计网络的架构让它encode我想让它encode的东西。可以通过设计,让content encoder去encode content的信息,让speaker encoder去encode speaker的信息。给encoder不同的架构。
这里举的例子在image transfer中已经有应用了。
为了让content encoder去encode content的信息,在content encoder里面加了一个instance normalization->可以帮助去掉speaker的信息。
那么instance normalization做的是什么呢?

这里的encoder的架构就像是LAS里面的encoder,很多层的CNN,首先input的是声音信号,用1-D的convolution扫过这排声音信号得到一排数值,

再用另一个filter也得到一排数值
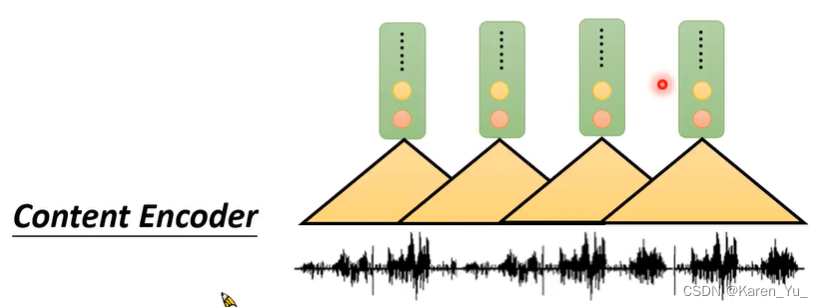
通过一组filter以后,每一小块声音信号都会变成一个vector(即:通过1-D convolution的layer之后会得到一个vector sequence)

instance normalization就作用在这个vector sequence上面,对这些vector的同一个dimension做normalization,会计算出这些vector的同一个dimension的mean和variance,然后减去mean除以variance。因此这些vector的同一个dimension的mean都会是0,variance都是1。以往这种方法多用在input feature上,在这里用在encoder的hidden layer上。
那么为什么这种方法可以去掉speaker的特性呢?
我们可以认为在CNN里面(1-D convolution里面,每一个filter其实就是抓声音信号中的某一种pattern,所以每一个row都代表声音信号中某一个pattern是否出现。)
比如,有的抓高频的信号,有的抓低频的信号,那么男生的声音进来低频的filter输出比较大,高频的比较小,女生的声音进来,高频的filter的输出比较大,低频的filter输出的比较小。
做normalization之后,就相当于吧speaker的特征去掉了(没有哪个filter的值特别大)

那么怎么让speaker encoder去encode speaker的信息呢?
采用adaptive instance normalization(只影响speaker的信息)
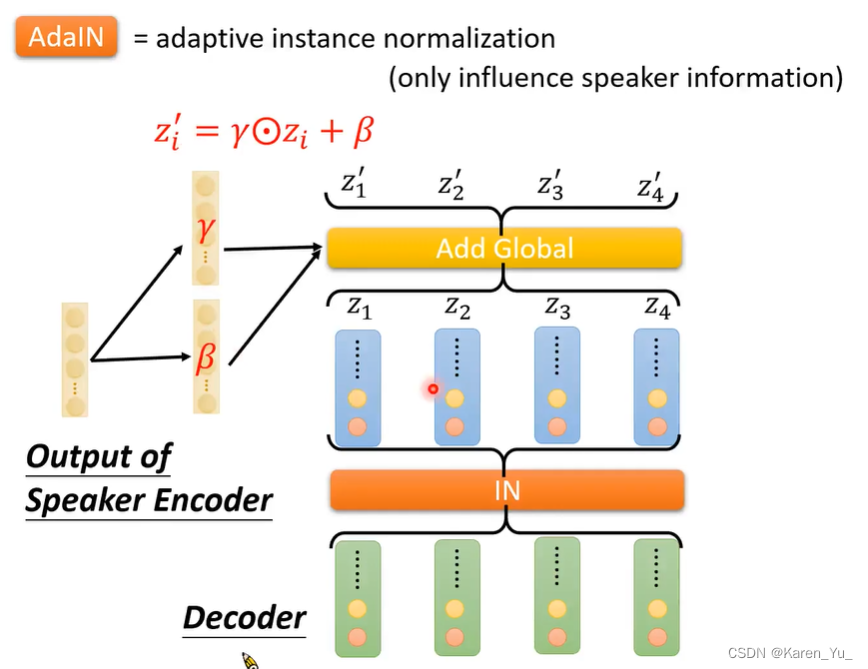
在decoder中,也有instance normalization,也会对CNN输出的每一个row,做normalization,去掉speaker的信息,那这时,怎么输出speaker的信息呢(来自encoder)。
speaker encoder会输出一个vector,这个vector通过两个transform之后分别产生两个vector γ β,接下来,γ 和 β会去影响做完instance normalization的结果。



但是实际上产生声音的效果并不都会很理想。其实model在training的时候,从来没有考虑过要做voice conversion这件事。model在training的时候,content encoder和speaker encoder其实吃的是同一个speaker的信息,并且是同一个句子的信息。在training的时候用的是minimize autoencoder的reconstruction error,但是在testing的时候,model要做的并不是autoencoder,而是voice conversion->model发现吃的可以是不同的speaker的信息。

idea:做2nd stage training
在training feature disentangle的时候从来没有把voice conversion考虑进来->考虑在training的时候把voice conversion考虑进来。
可以给content encoder和speaker encoder不同的speaker->在training的时候sample一个句子给content encoder,再sample一个speaker给speaker encoder,让decoder看到不同的speaker。
这么做的问题在哪里呢?
如果给不同的信息,最后要产生什么样的语音信息呢?这是没有ground truth的,因此没办法训练。
这里的思路是引入GAN的概念,train一个discriminator,这个discriminator的任务是判断decoder的声音信号听起来是真的声音信号还是生成的声音信号。虽然不知道合成的声音信号听起来应该是什么样子的(不知道ground truth),但是我们也可以确保decoder输出的信号像真实的声音信号。还可以加上一个speaker classifier,判断声音信号是不是某个人讲的。假设我们给的是B说‘hello’的声音,要合成A说'hello'的声音,虽然我们不知道A说‘hello’是什么样子,但是有了speaker classifier以后,decoder会想办法让speaker classifier把合成出来的声音信号分类成A发出的声音。

如果直接update decoder的参数让decoder去骗过speaker classifier可能训练不出来。tip是加一个patcher。patcher也是一个model,吃的input和decoder一样(content encoder的输出+speaker encoder的输出),decoder得到一段声音信号,patcher也产生一段声音信号,这一段声音信号会加到decoder产生的声音信号上,所以这个patcher的作用是打补丁。
Direct Transformation

Cycle GAN
直接把A的声音转成B的声音,采用图像上常用的cycleGAN

吃进来X的声音,经过一系列的转化(train一个generator),变成Y的声音。
但是我们并不知道X的声音转成Y的声音听起来应该是什么样子的,没有ground truth,那么怎么训练这个generator呢?需要一个discriminator,只要提供给discriminator很多Y的声音,然后discriminator就会去学会去鉴别一段声音信号是否是Y的声音。这个discriminator吃一段声音信号会output一个scalar,代表输出的声音信号听起来像不像Y的声音。
generator的目标就是骗过discriminator。
如果只是train一个discriminator和一个generator是不够的,generator可能学到的就是无论输入的是什么就只管输出Y最常说的内容

因此我们还需要加另一个generator,这个generator负责把Y的声音转回X的声音,让输入的声音信号和输出的声音信号越接近越好
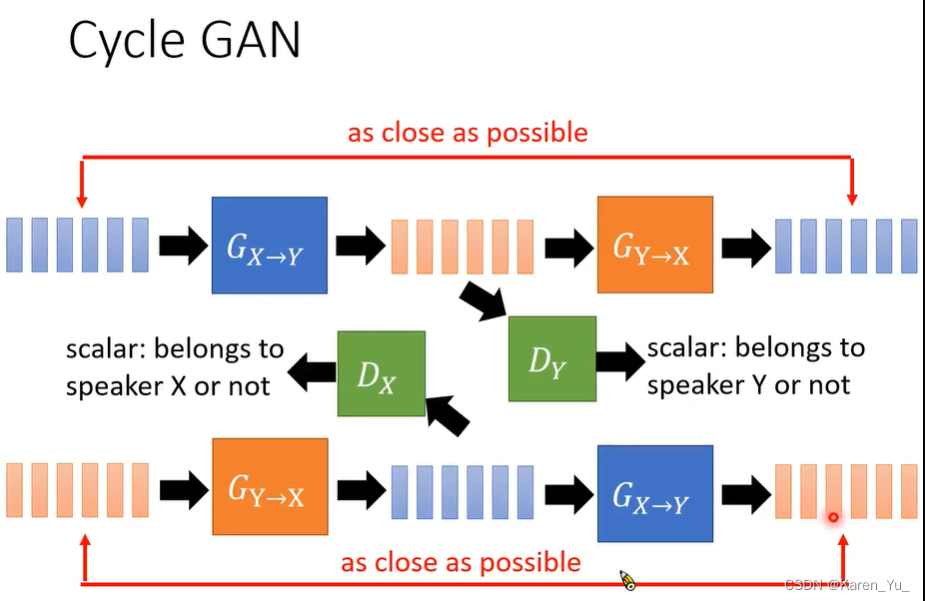
在train cycle GAN的时候还有小tip:在trainX->Y的generator的时候不仅可以喂X的声音让转成Y的声音,还可以多加一个训练的目标,直接喂Y的声音,让直接合成一模一样的Y的声音,让训练的更稳定一点。
同样也可以先把Y的声音转成X的声音,加一个discriminator,这个discriminator判断输出是不是像X的声音,再用另一个generator把X的声音转回Y的声音,一样要有cycle consistency 的loss
StarGAN

如果我们现在有多个speaker,这个想法就不太适用了。假设现在有四个speaker,我们就需要在4个speaker之间两两做cycle GAN

改一下cycle GAN。在starGAN里,generator要做很多事情,可以把输入的各式各样的声音信号转成我们需要的speaker的声音。
首先给generator一段声音信号(要被转的声音信号)si的声音信号,要转成sj的声音。
可以把每个speaker ont-hot,每个speaker都是一个特定的向量。也可以有一个已经pre-train好的speaker encoder,这个encoder可以把每个speaker的声音用一个continuous的向量表示,etc。

discriminator也要做一些改变,原来的discriminator是吃一段声音信号,判断这段声音信号是不是某个人讲的。
这里的discriminator也要吃一个speaker的声音信号,现在discriminator要做的是鉴别吃进来的信号是不是某个speaker讲的。

starGAN的运作方式和cycle GAN大同小异(图片上方就是cycle GAN)
在做starGAN的时候先随便sample一个speaker的声音(比如sk的声音),再随便sample一个speaker(比如si),generator就知道我们要把speaker sk的声音转化成speaker si的声音,然后就把si的声音合成出来。
discriminator会去判断合成的声音是不是si的声音。discriminator为什么能够判断呢?是因为我们也会把si的声音信号丢给discriminator。
接着我们会把同一个generator拿来,现在给另一个speaker,sk的信息,这时generator会把声音信号转成sk的信号,让输出和输入越接近越好
两个方法也许可以合成(比如把encoder和decoder放在generator里面?)
其他方法
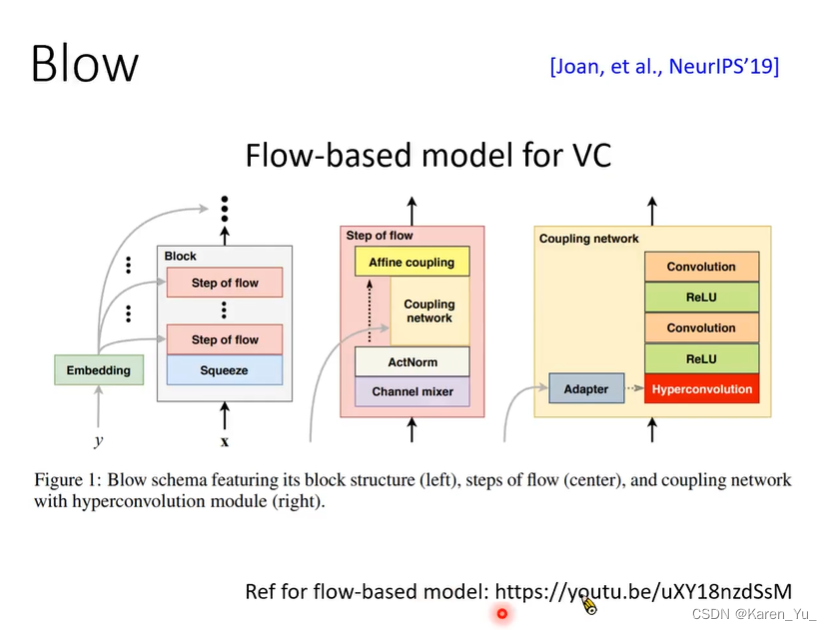
这篇关于李宏毅 自然语言处理(Voice Conversion) 笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







