本文主要是介绍Yolo V1、V2目标检测系统【详解】看不懂就在评论区diss我好吗,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、Yolo V1
- 1、YoloV1的核心思想
- 1.1 YoloV1存在的缺陷
- 2、YoloV1预测过程
- 3、YoloV1的Loss组成
- 3.1 中心点的 Loss
- 3.2 置信度Loss
- 3.3 类别的Loss
- 4、YoloV1的优缺点
- 二、Yolo V2
- 1、YoloV2对于YoloV1的改进
- 2、anchor(锚点/先验框)
- 2.1 注意点
- 2.2 Anchor和Loss Function
- 2.3 Anchor和cell的结合
- 3、 YoloV2的效果比较
一、Yolo V1
1、YoloV1的核心思想
Yolo V1的核心思想就是:One cell will be responsible for predicting an object as long as an object’s center locating in that cell.翻译为中文:只要物体落在哪个格子(cell)中,那么那个格子(cell)将会预测这个物体。如图:

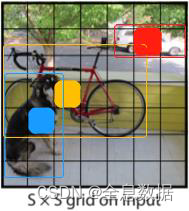
1.1 YoloV1存在的缺陷
因为一个格子(cell)只能预测一个物体,如果2个物体的中心点落在同一个格子(cell)内,那这2个物体就不能被同时预测。
2、YoloV1预测过程
Each cell predicts B bounding box with a confidence,翻译为:每个格子预测B个有置信度的边界框。

如上图第一行是边界框的中心。
第二行是边界框的置信度,包括两个部分,其中 P r ( o b j e c t ) P_{r}(object) Pr(object)表示预测的是不是物体,预测值在 0~1 之间, I o U p r d t r u t h IoU^{truth}_{prd} IoUprdtruth表示预测物体的置信度,即预测的准不准,预测值也在 0~1 之间,所以总体的置信度都在0~1之间;需要注意的是网络预测的是置信度,不预测具体的 P r ( o b j e c t ) P_{r}(object) Pr(object)、 I o U p r d t r u t h IoU^{truth}_{prd} IoUprdtruth。
第三行是网络预测的最终输出结果,从这里可以看出,一个格子预测的B个边界框都是属于同一个种类。
3、YoloV1的Loss组成
YoloV1的Loss由3部分组成,包括中心点的Loss,置信度的Loss,类别的Loss
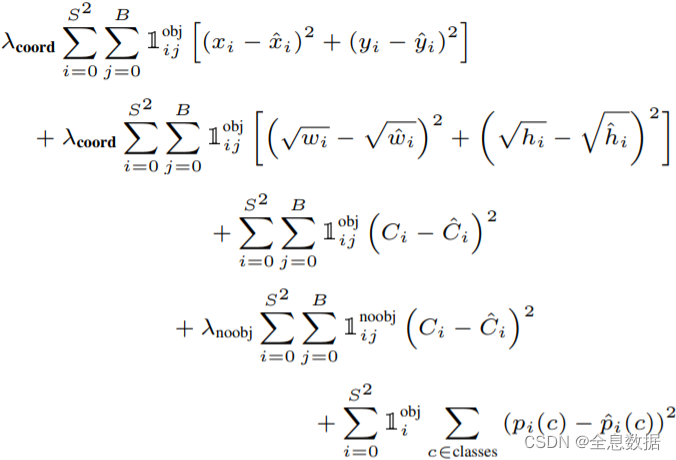
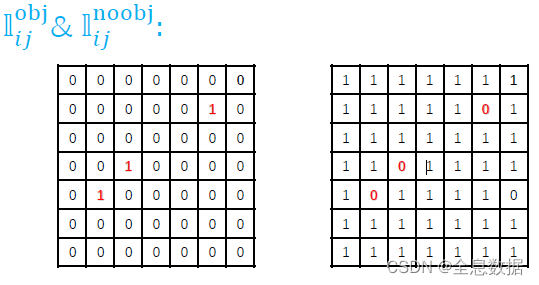
关于 I i j o b j \mathbb{I}^{obj}_{ij} Iijobj,原论文是这样解释的:we have B predictions in each cell, only the one with largest IoU shall be labeled as 1。
3.1 中心点的 Loss
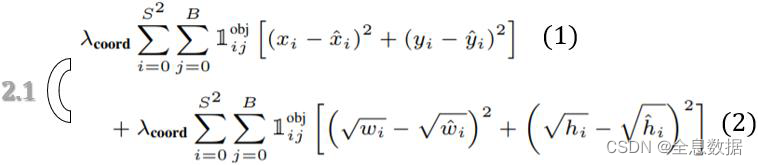
x , y x, y x,y:predicated bbox center,
𝑤 , h 𝑤,ℎ w,h:predicated bbox width & height
x ^ , y ^ \hat{x}, \hat{y} x^,y^:labeled bbox center,
w ^ , h ^ \hat{w}, \hat{h} w^,h^∶labeled bbox width & height
𝑤 , h \sqrt{𝑤},\sqrt{ℎ} w,h:Suppress the effect for larger bbox
λ 𝑐 𝑜 𝑜 𝑟 𝑑 \lambda_{𝑐𝑜𝑜𝑟𝑑} λcoord:设置为5, because there’s only 8 dimensions. Too less comparing to other losses
Weighted loss essentially.
需要注意的是: I i j o b j \mathbb{I}^{obj}_{ij} Iijobj只有具有最大的IoU才能设置为1,即待预测物体的格子只计算一次中心点Loss;
3.2 置信度Loss
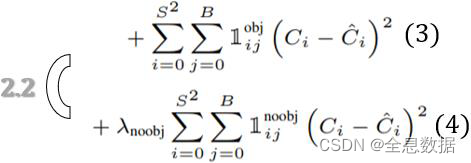
C i ^ \hat{C_i} Ci^:confidence score [IoU] ofpredicated and labeled bbox
即是说, C i ^ \hat{C_i} Ci^是我们预测的边界框与标注的边界框相计算的IoU
C i C_i Ci∶predicated confidence score [IoU] generated from networks
即是说, C i C_i Ci是网络预测的值,只要给 C i C_i Ci保留一个空位tensor,网络就会预测
我们也用到了 I i j n o o b j \mathbb{I}^{noobj}_{ij} Iijnoobj,即是学习背景,因为我们并没有给背景标注,所以这里的 C i ^ \hat{C_i} Ci^为0;
λ n o o b j \lambda_{noobj} λnoobj设置为0.5,因为背景相对于正样本太多了,所以设置为0.5;
3.3 类别的Loss
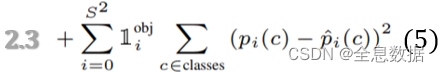
Each cell will only predict 1 object, which is decided by the bbox with largest IoU Classification Loss;
Don’t forget to do NMS after generating bboxes
因为每个cell只预测同一个类别的物体,所以就没有 ∑ j = 0 B \sum_{j=0}^{B} ∑j=0B这一项;
4、YoloV1的优缺点
优点:
One stage, really fast
缺点:
1、Bad for crowed objects [ 1 cell 1 obj
2、Bad for small objects
3、Bad for objects with new width height ratio
4、No BN
二、Yolo V2
1、YoloV2对于YoloV1的改进
1、加入了BN层

2、High Resolution Classifier,由7×7的格子变成了13×13的格子
3、anchor的使用
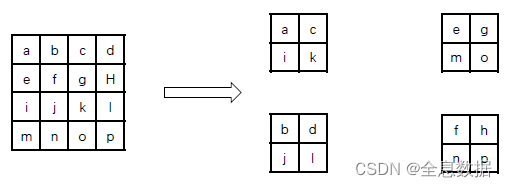
4、reorg网络
即把一个feature map每隔一个数据点进行分割,如图通过reorg网络把 4×4 的feature map分割成了4个 2×2 的feature map,然后再和其他2×2 的feature map进行拼接。
目的:进行浅层物理信息和深层语义信息的结合。
5、Multi Scale Training
Remove FC layers: Can accept any size of inputs, enhance model robustness.
Size across 320, 352, …, 608. Change per 10 epochs
[border % 32 = 0, decided by down sampling]
2、anchor(锚点/先验框)
2.1 注意点
1、Pre defined virtual bboxes,即YoloV2的anchor是预先设定好的虚拟边框,是已知的,
2、Final bboxes are generated from them
3、与Fast-RCNN的anchor的区别
Fast-RCNN的anchor是网络生成的,而YoloV2的anchor是预先设定好的虚拟边框。
2.2 Anchor和Loss Function
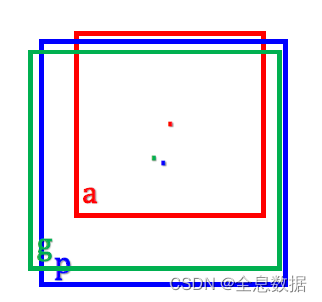
红色的a表示anchor,p表示预测框,g表示label,

YoloV1的回归是预测框的坐标与label标注框之间的回归,在YoloV2里变成了offset的回归,即图中的 p-a 和 g-a,
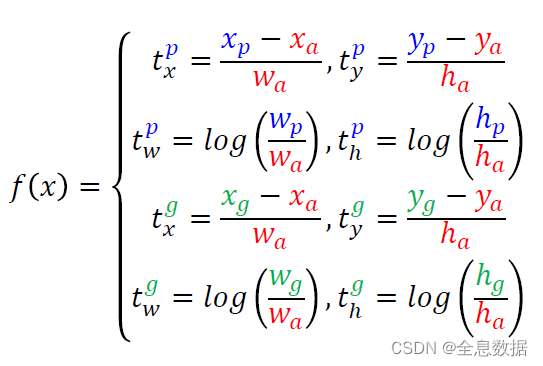
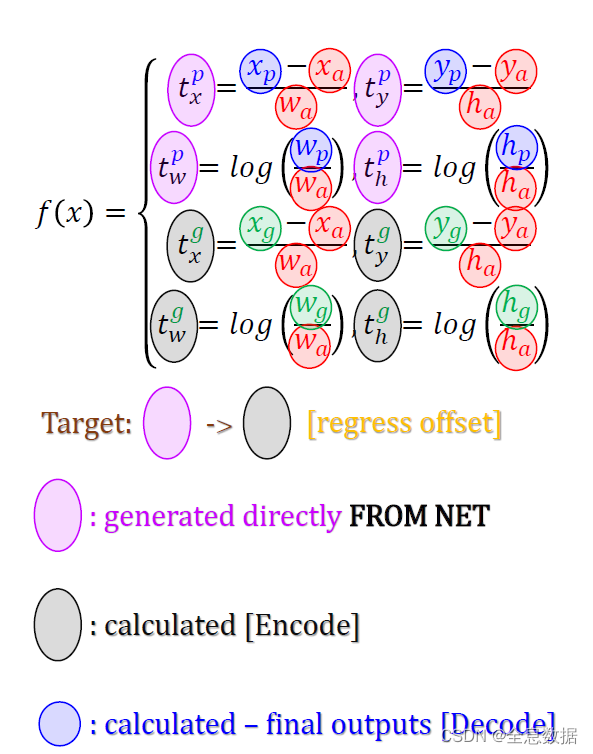
已知值:anchor、Ground Truth
即是说, t x p t^{p}_x txp是网络预测的值, t x g t^{g}_x txg是用已知值算出来的,
为什么关于anchor的归一化:抑制大物体的影响,取 log 也是同样的作用,
2.3 Anchor和cell的结合
因为YoloV2里最终生成的feature map是13×13,计算的Loss都是基于这个13×13的feature map,所以需要把anchor归一化到13×13。
a n c h o r [ 0 ] = a w i = a w o r i W ∗ 13 anchor[0]=a_{wi}=\frac{a_{w_{ori}}}{W}*13 anchor[0]=awi=Wawori∗13
如何把ground truth归一化到13×13呢?
标注的ground truth: [ x 0 , y 0 , w 0 , h 0 ] ∈ [ 0 , W ∣ H ] [x_0,y_0,w_0,h_0]\in[0,W|H] [x0,y0,w0,h0]∈[0,W∣H]
然后再分别除以 W ∣ H W|H W∣H,把坐标归一化到 0-1 之间,然后再乘以13;
即:
[ x , y , w , h ] = [ x 0 / W , y 0 / H , w 0 / W , h 0 / H ] ∗ ( 13 ∣ 13 ) [x,y,w,h]=[x_0/W,y_0/H,w_0/W,h_0/H]*(13|13) [x,y,w,h]=[x0/W,y0/H,w0/W,h0/H]∗(13∣13)
最后再根据cell进行归一化,
x f = x − i x_f=x-i xf=x−i y f = y − i y_f=y-i yf=y−i w f = l o g ( w / a n c h o r [ 0 ] ) w_f=log(w/anchor[0]) wf=log(w/anchor[0]) h f = l o g ( w / a n c h o r [ 1 ] ) h_f=log(w/anchor[1]) hf=log(w/anchor[1])
所以最终得到的 [ x f , y f . w f , h f ] ∈ [ 0 , 1 ] [x_f,y_f.w_f,h_f]\in[0,1] [xf,yf.wf,hf]∈[0,1]
所以上面的 f ( x ) f(x) f(x)可以更改为:
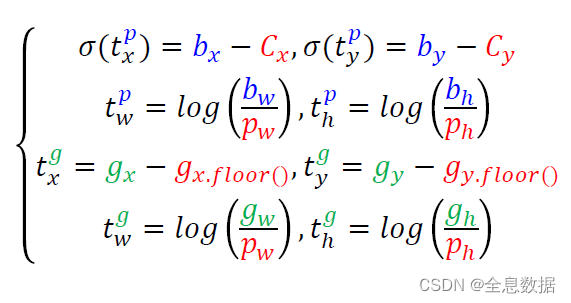
这里说一下上图的符号的意思,
σ ( t x p ) \sigma(t^p_x) σ(txp)是网络预测的结果,因为网络预测的范围在 0-1 之间,所以要加上 σ \sigma σ
b x b_x bx的就是上面公式中的 [ x , y , w , h ] [x,y,w,h] [x,y,w,h]
C x , C y C_x,C_y Cx,Cy是13×13 feature map cell的序号
p w p_w pw是上面公式中的 a n c h o r [ 0 ] anchor[0] anchor[0]
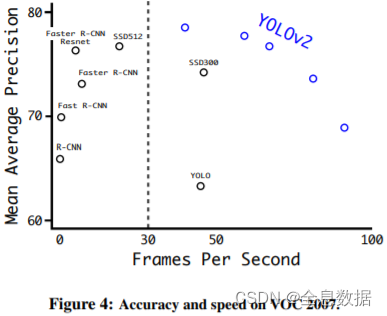
3、 YoloV2的效果比较
这篇关于Yolo V1、V2目标检测系统【详解】看不懂就在评论区diss我好吗的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









