本文主要是介绍基于SVM+Webdriver的智能NBA常规赛与季后赛结果预测系统——机器学习算法应用(含python、ipynb工程源码)+所有数据集(四),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 前言
- 总体设计
- 系统整体结构图
- 系统流程图
- 运行环境
- 模块实现
- 1. 数据预处理
- 2. 特征提取
- 3. 模型训练及评估
- 4. 模型训练准确率
- 系统测试
- 1. 测试效果
- 1)常规赛预测效果
- 2)季后赛预测效果
- 2. 模型应用
- 相关其它博客
- 工程源代码下载
- 其它资料下载

前言
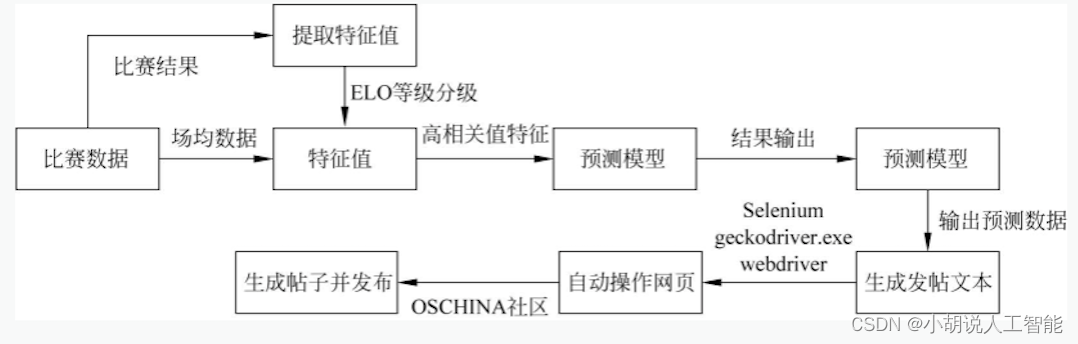
本项目使用了从NBA官方网站获得的数据,并运用了支持向量机(SVM)模型来进行NBA常规赛和季后赛结果的预测。此外,项目还引入了相关系数法、随机森林分类法和Lasso方法,以评估不同特征的重要性。最后,使用Python库中的webdriver功能实现了自动发帖,并提供了科学解释来解释比赛预测结果。
首先,项目采集了NBA官方网站上的各种数据,这些数据包括球队与对手的历史表现、球员数据、赛季统计等。这些数据用于构建常规赛或季后赛结果的预测模型。
其次,支持向量机(SVM)模型被用来分析这些数据以进行常规赛或季后赛结果的预测。SVM是一种强大的机器学习算法,可以通过分析数据来确定不同特征对比赛结果的影响。
项目还使用了相关系数法、随机森林分类法和Lasso方法,以评估每个特征对常规赛或季后赛结果的重要性。这有助于识别哪些因素对比赛胜负有更大的影响。
最后,项目利用Python中的webdriver库自动发帖,在开源中国论坛中发布关于比赛预测的帖子。这些帖子不仅提供了预测结果,还附带了科学解释,以便其他球迷能够理解模型如何得出这些预测。这对于NBA球迷和数据科学爱好者来说可能是一个非常有趣的项目,能够帮助他们更好地理解比赛和预测比赛结果。
总体设计
本部分包括系统整体结构图和系统流程图。
系统整体结构图
系统整体结构如图所示。
系统流程图
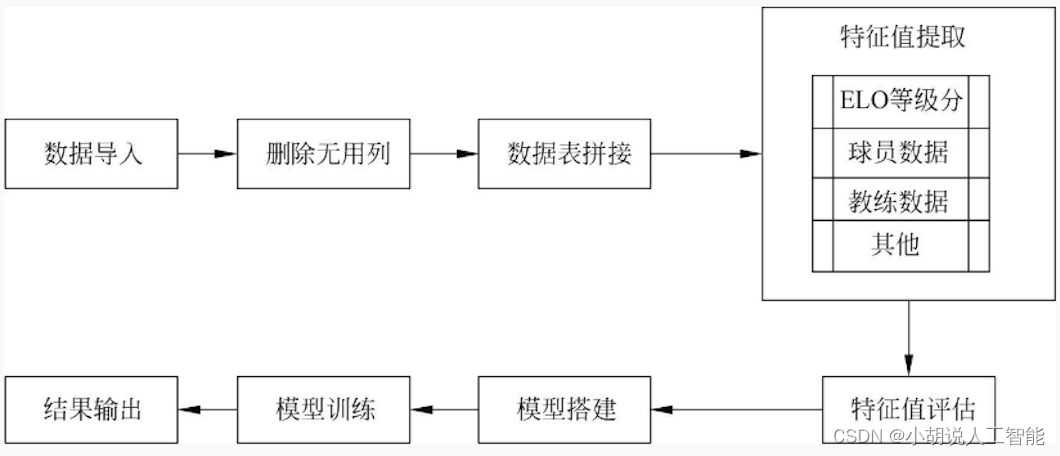
模型处理流程如图所示。
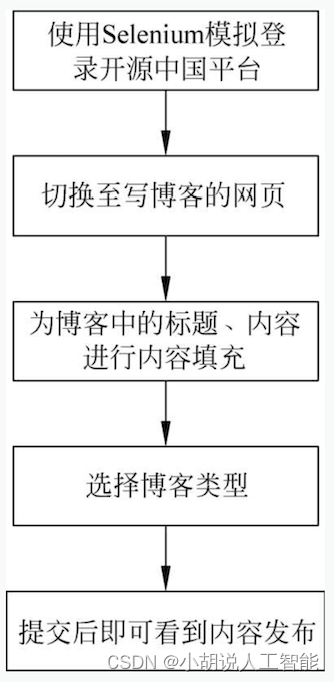
自动发帖流程如图所示。
运行环境
本部分包括Python环境、Jupyter Notebook环境、PyCharm环境和Matlab环境。
详见博客。
模块实现
本项目包括4个模块:数据预处理、特征提取、模型训练及评估、模型训练准确率,下面分别介绍各模块的功能及相关代码。
1. 数据预处理
数据处理分为常规赛和季后赛。
详见博客。
2. 特征提取
本部分包括常规赛特征提取和季后赛特征提取。
详见博客。
3. 模型训练及评估
本部分包括常规赛预测模型和季后赛模型创建。
详见博客。
4. 模型训练准确率
详见博客。
系统测试
本部分包括测试效果及模型应用。
1. 测试效果
本部分包括常规赛模拟预测和季后赛模拟预测效果。
1)常规赛预测效果
相关代码如下:
pred_y_ss=pd.Series(pred_y_pro[:,1]).map(lambda x:1 if x>0.5 else 0)
#通过调节百分比,控制主队获胜难度
result=pd.concat([schedule1617,pred_y_ss],axis=1)
#使用concat函数将18~19赛季比赛日历与预测结果拼接,形成预测日历
result.columns=['Vteam', 'Hteam', 'win']
#Vteam,Hteam分别为客场与主场球队,前者获胜则win值为1
result.head()
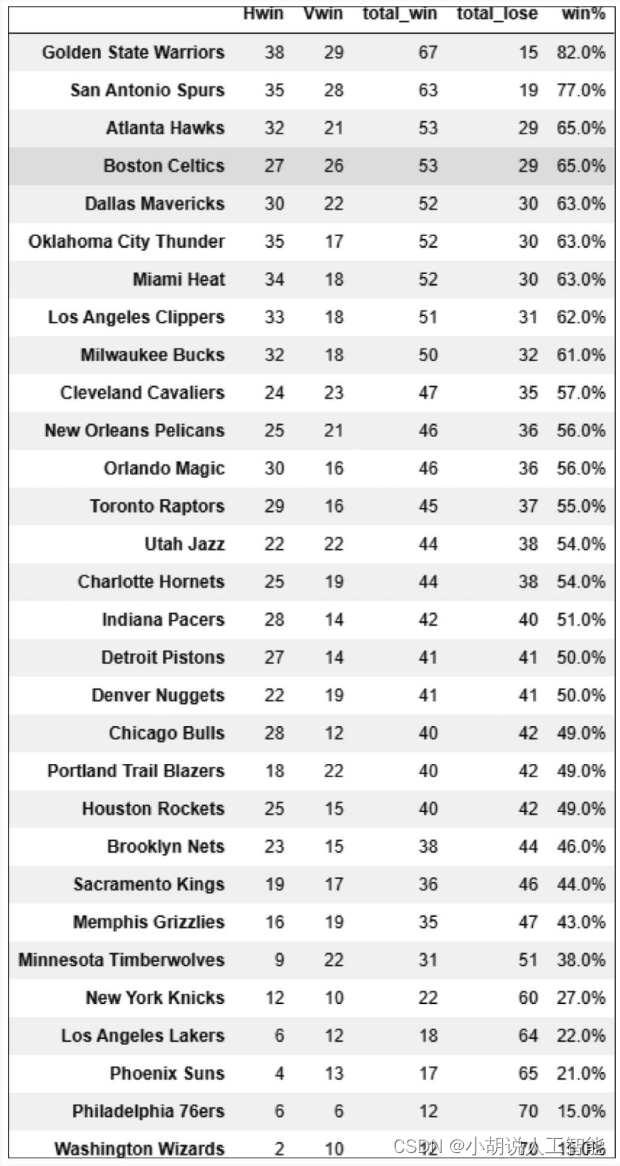
主客队胜负预测结果头部如下表所示。

常规赛模拟预测结果如下表所示。
Homewin_ss=result.groupby('Hteam').win.sum()
#求出每个球队的主场胜利情况
VictorWin_ss=result.groupby('Vteam').win.apply(lambda x:x.count()-x.sum())
#求出每个球队的客场胜利情况
result_per_team=pd.concat([Homewin_ss,VictorWin_ss],axis=1)
#生成每个球队的主客场胜负表
#计算出每个球队的总胜场、总负场及胜率,添加至表中
result_per_team.columns=['Hwin','Vwin']
result_per_team['total_win']=result_per_team.sum(axis=1)
result_per_team['total_lose']=82-result_per_team['total_win']
result_per_team['win%']=(round(result_per_team['total_win']/82*100,0)).astype('str')+'%'
#按照总胜场对球队进行排序
result_per_team.sort_values('total_win',ascending=False)
2)季后赛预测效果
由于本赛季停摆,对2018-2019赛季的季后赛程进行模拟预测的相关代码如下:
#生成测试集18~19赛季
X1, y1 = data_form('1819playoff.xlsx', z='test')
#预测18~19赛季的季后赛结果
pred_y = model.predict(X1).tolist()
#print(pred_y.tolist())
#print(y1)
aaa = pd.read_excel('1819playoff.xlsx')
pred_result = pd.DataFrame(index=range(len(y1)), columns=['team1', 'team2', 'Winner'])
#预测结果形成数据框
for i in range(len(pred_y)):if pred_y[i] == 1:pred_result.loc[[i], ['team1']] = aaa.loc[[i], ['Teamw']].valuespred_result.loc[[i], ['team2']] = aaa.loc[[i], ['Teaml']].valuespred_result.loc[[i], ['Winner']] = aaa.loc[[i], ['Teamw']].valueselse:pred_result.loc[[i], ['team1']] = aaa.loc[[i], ['Teamw']].valuespred_result.loc[[i], ['team2']] = aaa.loc[[i], ['Teaml']].valuespred_result.loc[[i], ['Winner']] = aaa.loc[[i], ['Teaml']].values
#结果写入文件
pred_result.to_csv('data_pred_result.csv')
季后赛模拟预测结果如下表所示。
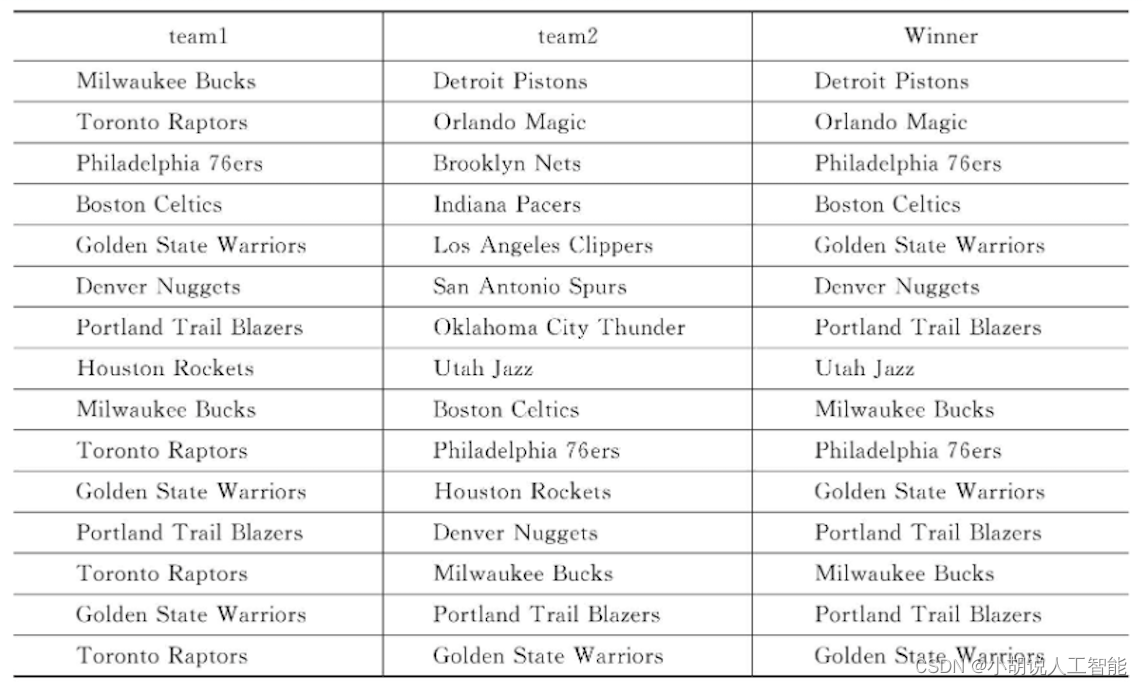
读者可以利用本部分代码,下载最新数据对未来的比赛结果进行预测。
2. 模型应用
本部分介绍预测结果使用Python自动发帖的方法,打开火狐浏览器,进入OSCHINA网站登录页。
相关代码如下:
user_main_url = 'https://my.oschina.net/u/564070'
username = '15201308426'
password = '5944608ab'
driver = webdriver.Firefox(executable_path='drivers/geckodriver.exe')
#最大化窗口
driver.maximize_window()
登录页面如下图所示。
#firefox元素定位,直接使用F12可以查看需要的参数,用户名和密码是自己定义的字符串
driver.find_element_by_id('userMail').send_keys(username)
driver.find_element_by_id('userPassword').send_keys(password)
#找到登录按钮并单击
driver.find_element_by_xpath('//*[@id="account_login"]/form/div/div[5]/button').click()
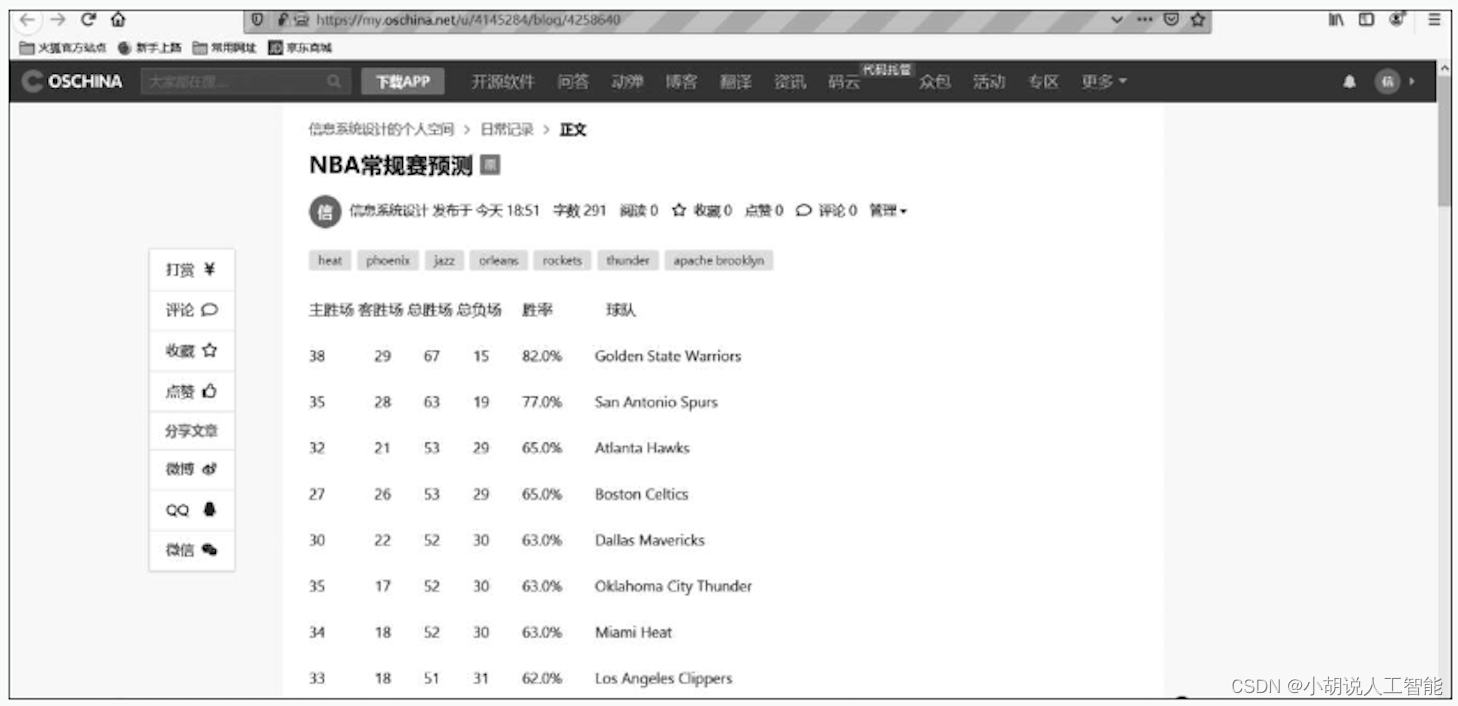
发帖操作界面如下图所示。
#进入主页
while True: #判断是否在个人主页中 if user_main_url in driver.current_url: print('成功进入到个人加载页面') break else: #不在个人主页中则继续加载time.sleep(1)
#单击进入写作页
driver.get('https://my.oschina.net/u/4145284/blog/write')
time.sleep(3)
#标题和正文内容在此修改
title_content = 'NBA常规赛预测'
#title_content = 'NBA季后赛预测'
f = open("常规赛.txt","r")#设置文件对象
#f = open("季后赛.txt","r")#设置文件对象
text_content = f.read()#将.txt文件的所有内容读入到字符串str中
f.close()#将文件关闭
#上述的“常规赛.txt”和“季后赛.txt”分别是常规赛和季后赛的预测结果
#填写标题
titleInput = driver.find_element_by_xpath('//*[@name="title"]')
#title属性变成name
titleInput.send_keys(title_content)
#调用iframe填写内容。Iframe又叫浮动帧标记,可以将HTML文档嵌入在HTML中显示
xf = driver.find_element_by_xpath('//iframe[@class="cke_wysiwyg_frame cke_reset"]')
driver.switch_to.frame(xf)
#text_content是发帖正文
driver.find_element_by_xpath('//body[@class="cke_editable cke_editable_themed cke_contents_ltr cke_show_borders"]').send_keys(text_content)
#输入正文之后,转回父页面
driver.switch_to.parent_frame()
#通过网页源代码可以查看所需参数
#右上角6503759-工作日期,6503760-日常记录,6503761-转帖的文章,模仿鼠标进行单击
driver.find_element_by_xpath('//div[@class="ui dropdown selection"]').click()
time.sleep(1)
driver.find_element_by_xpath("//div[@data-value='6503760']").click()
#左下角系统分类,该部分方法与前一步一样,选择-游戏开发
driver.find_element_by_xpath('//*[@id="writeArticleWrapper"]/div/div/form/div[4]/div[1]/div').click()
time.sleep(1)
driver.find_element_by_xpath("//div[@data-value='429511']").click()
#单击发表按钮
driver.find_element_by_xpath('//*[@id="writeArticleWrapper"]/div/div/form/div[8]/div[1]').click()
print('发表成功')
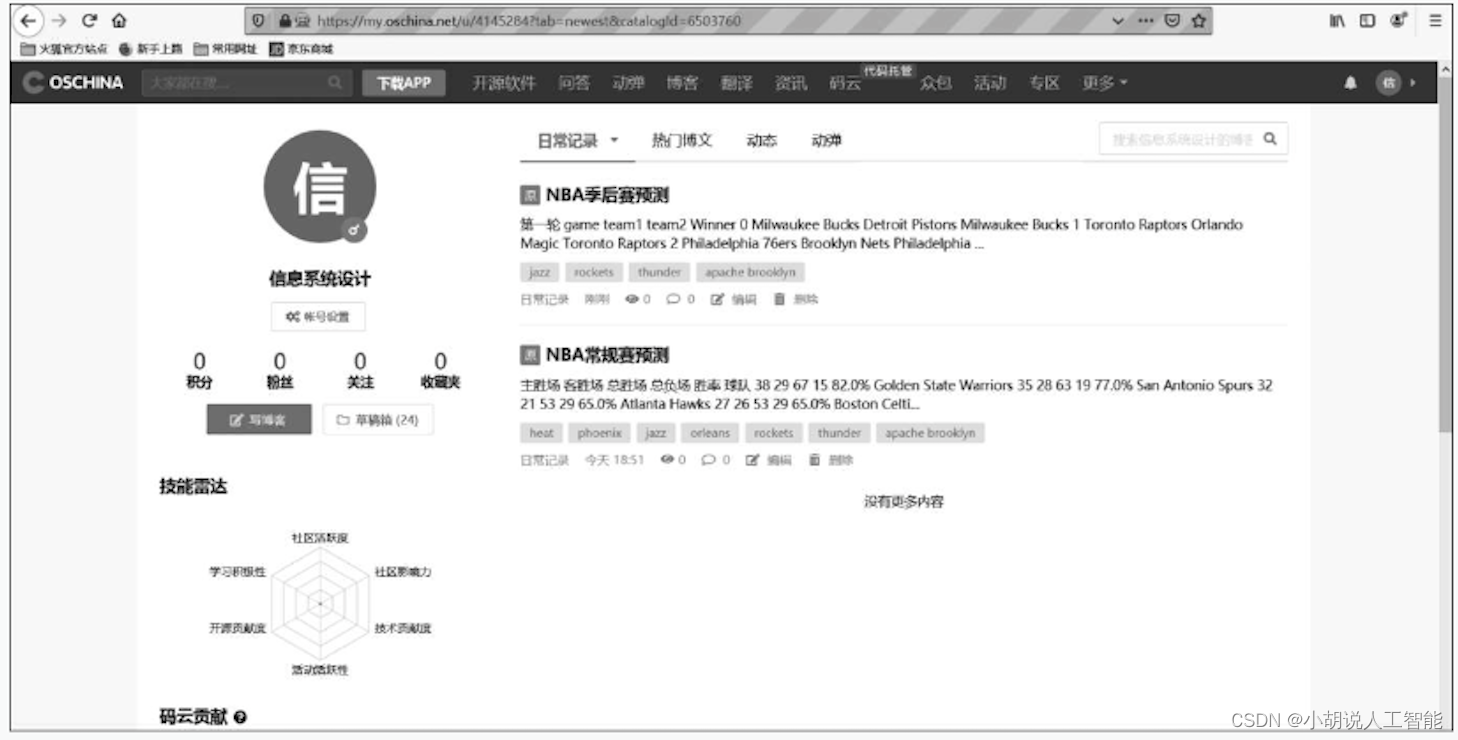
发帖效果如图4~图6所示。

相关其它博客
基于SVM+Webdriver的智能NBA常规赛与季后赛结果预测系统——机器学习算法应用(含python、ipynb工程源码)+所有数据集(一)
基于SVM+Webdriver的智能NBA常规赛与季后赛结果预测系统——机器学习算法应用(含python、ipynb工程源码)+所有数据集(二)
基于SVM+Webdriver的智能NBA常规赛与季后赛结果预测系统——机器学习算法应用(含python、ipynb工程源码)+所有数据集(三)
工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。
这篇关于基于SVM+Webdriver的智能NBA常规赛与季后赛结果预测系统——机器学习算法应用(含python、ipynb工程源码)+所有数据集(四)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





