本文主要是介绍解读:PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1.摘要
- 2.Introduction
- 3.网络结构
- 3.1用于有效特征编码和建议生成的3D Voxel CNN
- 3.2.通过voxel set abstraction进行voxel到关键点场景编码
- 3.3.扩展的VSA模块
- 3.4.预测关键点权重
- 3.5.key point-to-grid RoI特征抽象用于proposal refinement
- 4.损失
1.摘要
提出了一种新颖的高性能3D对象检测框架,名为Point Voxel-RCNN(PV-RCNN),用于从点云中进行精确的3D对象检测。提出的方法将3D体素卷积神经网络(CNN)和基于PointNet的集合抽象进行了深度融合,以学习更多判别性点云特征。它利用了3D体素CNN的高质量建议以及基于PointNet的网络的灵活感受野的优势。
第一阶段用3D voxel CNN生成高质量的建议,然后在第二阶段利用RoI-grid对上下文信息进行编码,以准确估计对象的置信度和位置。
2.Introduction
基于体素的方法在计算上更有效,但不可避免的信息丢失会降低精确的定位精度,而基于点的方法具有较高的计算成本,但可以通过Set Abstraction获得较大的感受野。本文提出一个统一的框架可以集成两种方法中的最佳方法,并以可观的幅度超越现有的最新3D检测方法。
3.网络结构
如图所示,PV-RCNN由3D体素CNN组成,其稀疏卷积作为有效特征编码和建议生成的主干。 给定每个3D对象建议,为了有效地从场景中合并其相应的特征,我们提出了两种新颖的操作:体素到关键点场景编码,该编码将整个场景特征量的所有体素汇总为少量的特征关键点, 点到网格RoI特征抽象可有效地将场景关键点特征汇总到RoI网格,以进行提案置信度预测和位置调整。
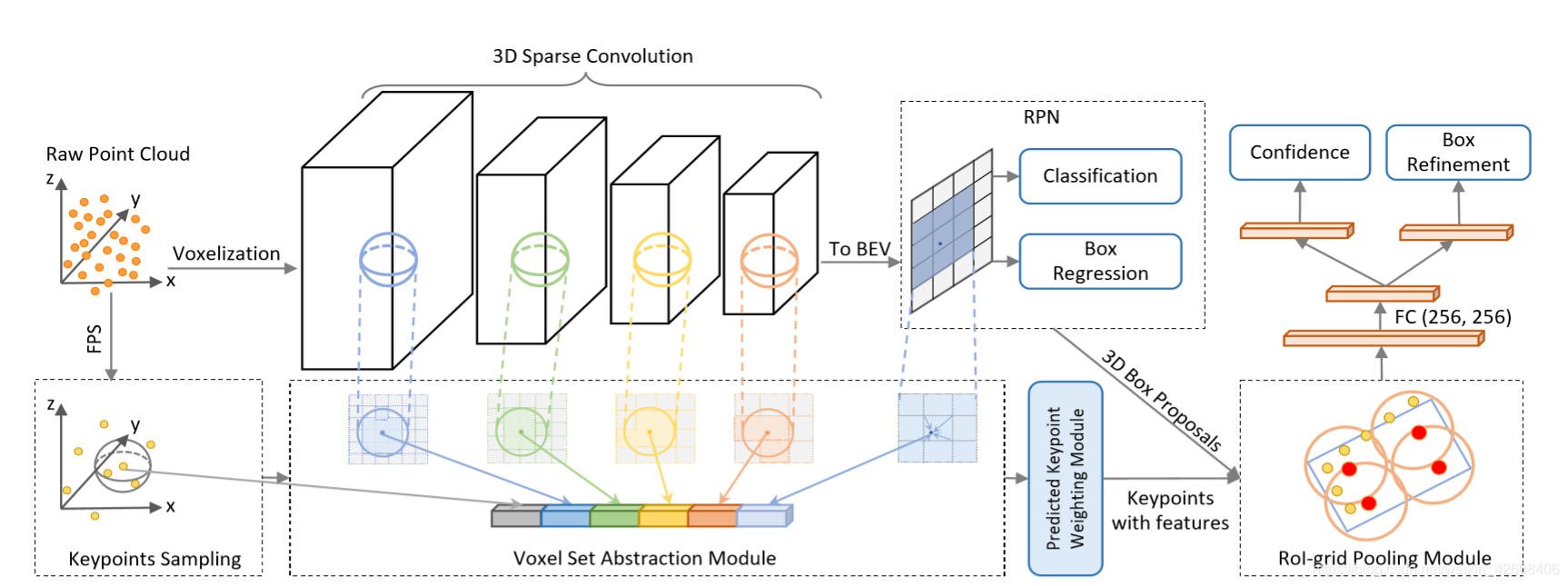
3.1用于有效特征编码和建议生成的3D Voxel CNN
3D体素CNN。 首先将输入点云P分为空间分辨率为L×W×H的小体素,其中,非空体素的特征将直接计算为所有内部点的点特征的平均值。 常用的特征是3D坐标和反射强度。 该网络利用一系列3×3×3 3D稀疏卷积将点云逐渐转换为具有1×,2×,4×,8×下采样大小的特征量。
3D提案生成。 通过将编码的8×下采样3D特征量转换为2D鸟瞰feature,遵循基于anchor的方法会生成高质量的3D建议。 具体来说,我们沿Z轴(高度变为通道)堆叠3D特征量以获得L/8×W/8鸟瞰特征图。 每个类别都有2×L/8×W/8 3D锚框(每个cell每个类别设置两个anchor),这些框采用此类的平均3D对象大小,并对鸟瞰特征图的每个像素评估两个0°,90°方向的锚。与基于PointNet的方法相比,采用基于锚的方案的3D体素CNN主干实现了更高的召回性能。(voxel CNN网络结构如下图)
3.2.通过voxel set abstraction进行voxel到关键点场景编码
本文提出的框架首先将代表整个场景的多个神经层的体素聚合为少量的关键点,这些关键点充当3D体素CNN特征编码器和proposal修饰网络之间的桥梁。
关键点采样采用最远点采样(FPS)算法从点云P中采样少量的n个关键点K = {p1,···,pn}
体素集抽象模块从3D CNN特征量到关键点的多尺度语义特征进行编码。

表示在3D voxel CNN的k层所表示的基于voxel的特征向量。

代表体素的坐标,由k层体素的索引和真实体素大小表示。对于每一个关键点Pi,首先找到k层rk半径邻域内的非空像素,并且把这些非空体素的特征向量写成:

其中,是将体素的语义特征和局部相对坐标相连接
然后,通过PointNet变换关键点的相邻体素集合的体素特征,以生成关键点的特征:

其中M(.)表示在近邻集合中随机抽取最多Tk个voxel进行计算,G(.)表示用于编码体素特征和相对位置的多层感知器网络。尽管相邻体素的数量在不同的关键点上有所不同,但沿通道最大池化操作max(·)将关键点pi的不同数量的相邻体素特征向量映射得到特征向量。
通常,我们还将在k层设计不同的半径范围为聚合具有不同receptive fields的局部体素特征,以捕获更丰富的多尺度上下文信息。
上述的voxel set abstraction在3D voxel CNN的不同层执行,可以将来自不同级的聚合特征进行级联以生成关键点pi的多尺度语义特征。

For i=1,….n,特征fi(pv)是结合了从三维voxel特征f(lk)进行的基于三维像素CNN学习到的特征和从等式2的三维voxel特征学习中获得的基于pointnet的特征,除此之外,pi的3D坐标还保留了精确的位置信息。
3.3.扩展的VSA模块
通过进一步丰富原始点云P和8×下采样二维鸟瞰图的关键点特征,扩展了VSA模块,其中原始点云部分弥补了初始点云体素化的量化损失,而二维鸟瞰图沿Z轴有更大的感受野。
原始点云特征fi(raw)也如公式(2)所示进行聚合。利用二维投影点坐标系对特征点进行插值,得到鸟瞰图的特征map。因此,pi的特征通过连接其所有相关特性而进一步丰富。
 它具有保留整个场景的3D结构信息的强大功能,并且还可以大大提高最终的检测性能。
它具有保留整个场景的3D结构信息的强大功能,并且还可以大大提高最终的检测性能。
3.4.预测关键点权重
关键点中有的是前景点、有的是背景点,前景点的权重应该大,背景点应该小。所以对每个关键点的特征进行权重预测

其中A(·)是一个三层MLP网络,其sigmoid函数用于预测[0,1]之间的前景置信度。PKW模块通过focus loss进行训练。
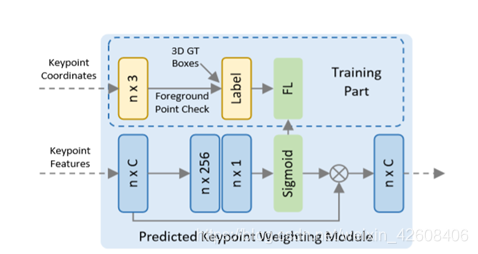
通过这n个点的feature,可以计算n个weight,weight由真实的mask做监督训练,然后用这weight乘以点的feature,得到每个点的最终的feature。
3.5.key point-to-grid RoI特征抽象用于proposal refinement
RoI-grid Pooling via Set Abstraction
提出了一种基于集合抽象操作的关键点到网格RoI特征抽象,用于多尺度RoI特征编码。
在每个3D提案中统一采样6×6×6网格点,表示为G = {g1,…,g216}。首先将半径为r的网格点gi的相邻关键点标识为
然后应用一个PointNet block来聚合邻域关键点的特征集合产生grid point:gi的特征:

其中M(.)和G(.)与公式2中的定义相同。设置具有不同感受野的多重半径和关键点特征,将它们组合在一起以捕获更丰富的多尺度上下文信息。
在从其周围的关键点获取每个网格的聚合特征后,可以通过具有256个特征维的两层MLP对相同RoI的所有RoI网格特征进行矢量化和转换,以代表总体建议。
3D Proposal Refinement and Confidence Prediction
给定每个proposal的RoI特征,proposal优化网络将学习预测3D proposal的大小和位置(即中心,大小和方向)残差。 refinement网络采用2层MLP,分别具有两个分支,分别用于置信度预测和proposal refinement。
对于置信度预测分支,将3D RoI和它们对应的ground truth之间的3D IoU用作训练目标。 对于第k个3D RoI,其置信度训练目标yk归一化为[0,1]

其中IoUk是是第k个RoI与其地面真实度框的IoU。 以最小化预测置信度目标时的交叉熵损失:

4.损失

这篇关于解读:PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







