本文主要是介绍【MMT】ICLR 2020: MMT(Mutual Mean-Teaching)方法,无监督域适应在Person Re-ID上性能再创新高,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原文链接 小样本学习与智能前沿 。 在这个公众号后台回复“200708”,即可获得课件电子资源。


为了减轻噪音伪标签的影响,文章提出了一种无监督的MMT(Mutual Mean-Teaching)方法,通过在迭代训练的方式中使用离线精炼硬伪标签和在线精炼软伪标签,来学习更佳的目标域中的特征。同时,还提出了可以让Traplet loss支持软标签的soft softmax-triplet loss”。 该方法在域自适应任务方面明显优于所有现有的Person re-ID方法,改进幅度高达18.2%。
MUTUAL MEAN-TEACHING: PSEUDO LABEL REFINERY FOR UNSUPERVISED DOMAIN ADAPTATION ON PERSON RE-IDENTIFICATION
- ABSTRACT
- 1 INTRODUCTION
- 2 RELATED WORK
- Unsupervised domain adaptation (UDA) for person re-ID.
- Genericdomainadaptationmethodsforclose-setrecognition.
- Teacher-studentmodels
- Generic methods for handling noisy labels
- 3 PROPOSED APPROACH
- 3.1 CLUSTERING-BASED UDA METHODS REVISIT
- 3.2 MUTUAL MEAN-TEACHING (MMT) FRAMEWORK
- 3.2.1 SUPERVISED PRE-TRAINING FOR SOURCE DOMAIN
- 3.2.2 PSEUDO LABEL REFINERY WITH ON-LINE REFINED SOFT PSEUDO LABELS
- 3.2.3 OVERALL LOSS AND ALGORITHM
- 4 EXPERIMENTS
- 4.1 DATASETS
- 4.2 IMPLEMENTATION DETAILS
- 4.2.1 TRAINING DATA ORGANIZATION
- 4.2.2 OPTIMIZATION DETAILS
- 4.3 COMPARISON WITH STATE-OF-THE-ARTS
- 4.4 ABLATION STUDIES
- Effectiveness of the soft pseudo label refinery.
- Effectiveness of the soft softmax-triplet loss.
- EffectivenessofMutualMean-Teaching.
- Necessity of hard pseudo labels in proposed MMT.
- 5 CONCLUSION

ABSTRACT
Do What
In order to mitigate the effects of noisy pseudo labels:
- we propose to softly refine the pseudo labels in the target domain by proposing an unsupervised framework, Mutual Mean-Teaching (MMT), to learn better features from the target domain via off-line refined hard pseudo labels and on-line refined soft pseudo labels in an alternative training manner.
- the common practice is to adopt both the classification loss and the triplet loss jointly for achieving optimal performances in person re-ID models. However, conventional triplet loss cannot work with softly refined labels. To solve this problem, a novel soft softmax-triplet loss is proposed to support learning with soft pseudo triplet labels for achieving the optimal domain adaptation performance.
Results: The proposed MMT framework achieves considerable improvements of 14.4%, 18.2%, 13.4% and 16.4% mAP on Market-to-Duke, Duke-to-Market, Market-to-MSMT and Duke-to-MSMT unsupervised domain adaptation tasks.
1 INTRODUCTION
State-of-the-art UDA methods (Song et al., 2018; Zhang et al., 2019b; Yang et al., 2019) for person re-ID group unannotated images with clustering algorithms and train the network with clustering-generated pseudo labels.
Conclusion 1
The refinery of noisy pseudo labels has crucial influences to the final performance, but is mostly ignored by the clustering-based UDA methods.
To effectively address the problem of noisy pseudo labels in clustering-based UDA methods (Song et al., 2018; Zhang et al., 2019b; Yang et al., 2019) (Figure 1), we propose an unsupervised Mutual Mean-Teaching (MMT) framework to effectively perform pseudo label refinery by optimizing the neural networks under the joint supervisions of off-line refined hard pseudo labels and on-line refined soft pseudo labels.
Specifically, our proposed MMT framework provides robust soft pseudo labels in an on-line peer-teaching manner, which is inspired by the teacher-student approaches (Tarvainen & Valpola, 2017; Zhang et al., 2018b) to simultaneously train two same networks. The networks gradually capture target-domain data distributions and thus refine pseudo labels for better feature learning.
To avoid training error amplification, the temporally average model of each network is proposed to produce reliable soft labels for supervising the other network in a collaborative training strategy.
By training peer-networks with such on-line soft pseudo labels on the target domain, the learned feature representations can be iteratively improved to provide more accurate soft pseudo labels, which, in turn, further improves the discriminativeness of learned feature representations.

the conventional triplet loss (Hermansetal.,2017)cannot work with such refined soft labels. To enable using the triplet loss with soft pseudo labels in our MMT framework, we propose a novel soft softmax-triplet loss so that the network can benefit from softly refined triplet labels.
The introduction of such soft softmax-triplet loss is also the key to the superior performance of our proposed framework. Note that the collaborative training strategy on the two networks is only adopted in the training process. Only one network is kept in the inference stage without requiring any additional computational or memory cost.
The contributions of this paper could be summarized as three-fold.
- The proposed Mutual Mean-Teaching (MMT) framework is designed to provide more reliable soft labels.
- we propose the soft softmax-triplet loss to learn more discriminative person features.
- The MMT framework shows exceptionally strong performances on all UDA tasks of person re-ID.
2 RELATED WORK
Unsupervised domain adaptation (UDA) for person re-ID.
Genericdomainadaptationmethodsforclose-setrecognition.
Teacher-studentmodels
Generic methods for handling noisy labels
3 PROPOSED APPROACH
Our key idea is to conduct pseudo label refinery in the target domain by optimizing the neural networks with off-line refined hard pseudo labels and on-line refined soft pseudo labels in a collaborative training manner.
In addition, the conventional triplet loss cannot properly work with soft labels. A novel soft softmax-triplet loss is therefore introduced to better utilize the softly refined pseudo labels.
Both the soft classification loss and the soft softmax-triplet loss work jointly to achieve optimal domain adaptation performances.
Formally:
we denote the source domain data as D s = { ( x i s , y i s ) ∣ i = 1 N s } D_s = \left\{(x^s_i,y^s_i )|^{N_s}_{i=1}\right\} Ds={(xis,yis)∣i=1Ns}, where x i s x^s_i xisand y i s y^s_i yis denote the i-th training sample and its associated person identity label, N s N_s Ns is the number of images, and M s M_s Ms denotes the number of person identities (classes) in the source domain. The N t N_t Nt target-domain images are denoted as D t = { x i t ∣ i = 1 N t } Dt = \left\{x^t_i|^{N_t}_{i=1}\right\} Dt={xit∣i=1Nt}, which are not associated with any ground-truth identity label.
3.1 CLUSTERING-BASED UDA METHODS REVISIT
State-of-the-art UDA methods generally pre-train a deep neuralnet work F ( ⋅ ∣ θ ) F(·|θ) F(⋅∣θ)onthe source domain, where θ θ θ denotes current network parameters, and the network is then transferred to learn from the images in the target domain.
The source-domain images’ and target-domain images’ features encoded by the network are denoted as { F ( x i s ∣ θ ) } ∣ i = 1 N s \left\{F(x^s_i|θ)\right\}|^{N_s}_{ i=1} {F(xis∣θ)}∣i=1Ns and { F ( x i t ∣ θ ) } ∣ i = 1 N t \left\{F(x^t_i|θ)\right\}|^{N_t}_{ i=1} {F(xit∣θ)}∣i=1Nt respectively.

As illustrated in Figure 2 (a), two operations are alternated to gradually fine-tune the pre-trained network on the target domain.
- The target-domain samples are grouped into pre-defined M t M_t Mtclasses by clustering the features { F ( x i t ∣ θ ) } ∣ i = 1 N t \left\{F(x^t_i|θ)\right\}|^{N_t}_{ i=1} {F(xit∣θ)}∣i=1Nt output by the current network. Let h i t ^ \hat{h^t_i} hit^ denotes the pseudo label generated for image x i t x^t_i xit.
- The network parameters θ θ θ and a learnable target-domain classifier C t : f t → { 1 , ⋅ ⋅ ⋅ , M t } C^t : f^t →\left\{1,··· ,M_t\right\} Ct:ft→{1,⋅⋅⋅,Mt} are then optimized with respect to an identity classification(crossentropy) loss L i d t ( θ ) L^t_{id}(θ) Lidt(θ) and a triplet loss (Hermans et al., 2017) L t r i t ( θ ) L^t_{tri}(θ) Ltrit(θ) in the form of,

where ||·|| denotes the L2-norm distance, subscripts i,p and i,n indicate the hardest positive and hardest negative feature index in each mini-batch for the sample x i t x^t_i xit, and m = 0.5 denotes the triplet distance margin.
3.2 MUTUAL MEAN-TEACHING (MMT) FRAMEWORK
3.2.1 SUPERVISED PRE-TRAINING FOR SOURCE DOMAIN
The neural network is trained with a classification loss L i d s ( θ ) L^s_{id}(θ) Lids(θ) and a triplet loss L t r i s ( θ ) L^s_{tri}(θ) Ltris(θ) to separate features belonging to different identities. The overall loss is therefore calculated as
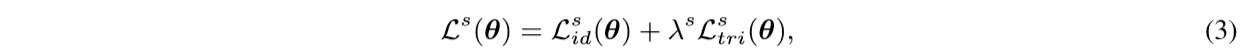
where λ s \lambda^s λs is the parameter weighting the two losses.
3.2.2 PSEUDO LABEL REFINERY WITH ON-LINE REFINED SOFT PSEUDO LABELS
off-linerefined hard pseudo labels as introduced in Section 3.1, where the pseudo label generation and refinement are conducted alternatively. However, the pseudo labels generated in this way are hard (i.e.,theyare always of 100% confidences) but noisy
our framework further incorporates on-line refined soft pseudo labels (i.e., pseudo labels with < 100% confidences) into the training process.
Our MMT framework generates soft pseudo labels by collaboratively training two same networks with different initializations. The overall framework is illustrated in Figure 2 (b).

our two collaborative networks also generate on-line soft pseudo labels by network predictions for training each other.
To avoid two networks collaboratively bias each other, the past temporally average model of each network instead of the current model is used to generate the soft pseudo labels for the other network. Both off-line hard pseudo labels and on-line soft pseudo labels are utilized jointly to train the two collaborative networks. After training,only one of the past average models with better validated performance is adopted for inference (see Figure 2 ©).

We denote the two collaborative networks as feature transformation functions F ( ⋅ ∣ θ 1 ) F(·|θ_1) F(⋅∣θ1) and F ( ⋅ ∣ θ 2 ) F(·|θ_2) F(⋅∣θ2), and denote their corresponding pseudo label classifiers as C 1 t C^t _1 C1t and C 2 t C^t_2 C2t, respectively.
we feed the same image batch to the two networks but with separately random erasing, cropping and flipping.
Each target-domain image can be denoted by x i t x^t_i xit and x i ′ t x'^t_i xi′t for the two networks, and their pseudo label confidences can be predicted as C 1 t ( F ( x i t ∣ θ 1 ) ) C^t_1(F(x^t_i|θ_1)) C1t(F(xit∣θ1)) and C 2 t ( F ( x i ′ t ∣ θ 2 ) ) C^t _2(F(x'^t_i|θ_2)) C2t(F(xi′t∣θ2)).
In order to avoid error amplification, we propose to use the temporally average model of each network to generate reliable soft pseudo labels for supervising the other network.
Specifically, the parameters of the temporally average models of the two networks at current iteration T are denoted as E ( T ) [ θ 1 ] E^{(T)}[θ_1] E(T)[θ1] and E ( T ) [ θ 2 ] E^{(T)}[θ_2] E(T)[θ2] respectively, which can be calculated as :
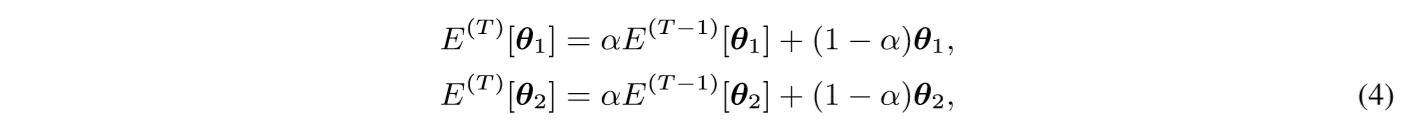
where E ( T ) [ θ 1 ] E^{(T)}[θ_1] E(T)[θ1], E ( T ) [ θ 2 ] E^{(T)}[θ_2] E(T)[θ2] indicate the temporal average parameters of the two networks in the previous iteration(T−1), the initial temporal average parameters are E ( 0 ) [ θ 1 ] = θ 1 E^{(0)}[θ_1] = θ_1 E(0)[θ1]=θ1, E ( 0 ) [ θ 2 ] = θ 2 E^{(0)}[θ_2] = θ2 E(0)[θ2]=θ2,and α is the ensembling momentum to be within the range [0,1).
The robust soft pseudo label supervisions are then generated by the two temporal average models as C 1 t ( F ( x i t ∣ E ( T ) [ θ 1 ] ) ) C^t_1(F(x^t_i|E^{(T)}[θ_1])) C1t(F(xit∣E(T)[θ1])) and C 2 t ( F ( x i t ∣ E ( T ) [ θ 2 ] ) ) C^t_2(F(x^t_i|E^{(T)}[θ_2])) C2t(F(xit∣E(T)[θ2])) respectively. The soft classification loss for optimizing θ 1 θ_1 θ1 and θ 2 θ_2 θ2 with the soft pseudo labels generated from the other network can therefore be formulated as:

The two networks’ pseudo-label predictions are better dis-related by using other network’s past average model to generate supervisions and can therefore better avoid error amplification.
we propose to use softmax-triplet loss, whose hard version is formulated as:
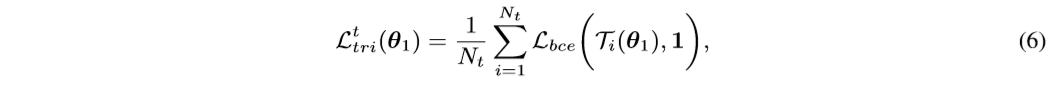
where
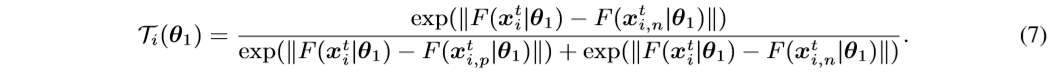
Here L b c e ( ⋅ , ⋅ ) L_{bce}(·,·) Lbce(⋅,⋅) denotes the binary cross-entropy loss. “1” denotes the ground-truth that the positive sample x i , p t x^t_{i,p} xi,pt should be closer to the sample x i t x^t_i xit than its negative sample x i , n t x^t_{i,n} xi,nt.
we can utilize the one network’s past temporal average model to generate soft triplet labels for the other network with the proposed soft softmax-triplet loss:
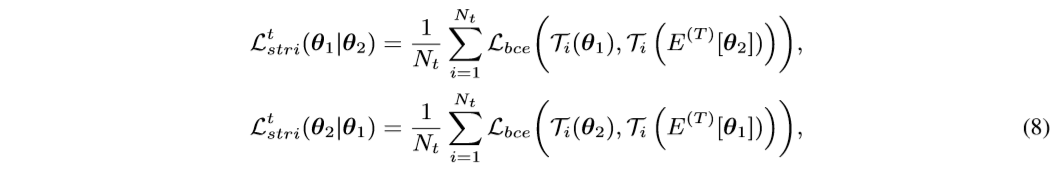
where T i ( E ( T ) [ θ 1 ] ) T_i(E^{(T)}[θ_1]) Ti(E(T)[θ1]) and T i ( E ( T ) [ θ 2 ] ) T_i(E^{(T)}[θ_2]) Ti(E(T)[θ2]) are the soft triplet labels generated by the two networks’ past temporally average models.
3.2.3 OVERALL LOSS AND ALGORITHM
Our proposed MMT framework is trained with both off-line refined hard pseudo labels and on-line refinedsoftpseudolabels. The over all loss function L ( θ 1 , θ 2 ) L(θ_1,θ_2) L(θ1,θ2) simultaneously optimizes the coupled networks, which combines equation 1, equation 5, equation 6, equation 8 and is formulated as,
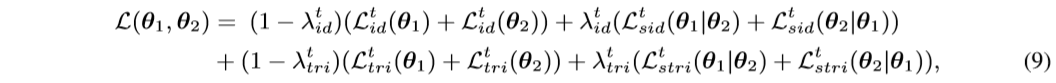
where λ i d t λ^t_{id} λidt, λ t r i t λ^t_{tri} λtrit aretheweightingparameters.
The detailed optimization procedures are summarized in Algorithm 1.

The hard pseudo labels are off-line refined after training with existing hard pseudo labelsforoneepoch. During the training process, the two networks are trained by combining the off line refined hard pseudo labels and on-line refined soft labels predicted by their peers with proposed soft losses. The noise and randomness caused by hard clustering, which lead to unstable training and limited final performance, can be alleviated by the proposed MMT framework.
4 EXPERIMENTS
4.1 DATASETS
We evaluate our proposed MMT on three widely-used person re-ID datasets, i.e., Market1501(Zhengetal.,2015),DukeMTMC-reID(Ristanietal.,2016),andMSMT17(Weietal.,2018).
For evaluating the domain adaptation performance of different methods, four domain adaptation tasks are set up, i.e., Duke-to-Market, Market-to-Duke, Duke-to-MSMT and Market-to-MSMT, where only identity labels on the source domain are provided. Mean average precision (mAP) and CMC top-1, top-5, top-10 accuracies are adopted to evaluate the methods’ performances.
4.2 IMPLEMENTATION DETAILS
4.2.1 TRAINING DATA ORGANIZATION
For both source-domain pre-training and target-domain fine-tuning, each training mini-batch contains 64 person images of 16 actual or pseudo identities (4 for each identity).
All images are resized to 256×128 before being fed into the networks.
4.2.2 OPTIMIZATION DETAILS
All the hyper-parameters of the proposed MMT framework are chosen based on a validation set of the Duke-to-Market task with M t M_t Mt = 500 pseudo identities and IBN-ResNet-50 backbone.
We propose a two-stage training scheme, where ADAM optimizer is adopted to optimize the networks with a weight decay of 0.0005. Randomly erasing (Zhong et al., 2017b) is only adopted in target-domain fine-tuning.
- Stage 1: Source-domain pre-training.
- Stage 2: End-to-end training with MMT.
4.3 COMPARISON WITH STATE-OF-THE-ARTS
The results are shown in Table 1. Our MMT framework significantly outperforms all existing approaches with both ResNet-50 and IBN-ResNet-50 backbones, which verifies the effectiveness of our method.

Such results prove the necessity and effectiveness of our proposed pseudo label refinery for hard pseudo labels with inevitable noises.
Co-teaching (Han et al., 2018) is designed for general close-set recognition problems with manually generated label noise, which could not tackle the real-world challenges in unsupervised person re-ID. More importantly, it does not explore how to mitigate the label noise for the triplet loss as our method does.
4.4 ABLATION STUDIES
In this section, we evaluate each component in our proposed framework by conducting ablation studies on Duke-to-Market and Market-to-Duke tasks with both ResNet-50 (He et al., 2016) and IBN-ResNet-50 (Pan et al., 2018) backbones. Results are shown in Table 2.

Effectiveness of the soft pseudo label refinery.
To investigate the necessity of handling noisy pseudo labels in clustering-based UDA methods,we create baseline models that utilize only off-line refined hard pseudo labels. i.e., optimizing equation 9 with λ i d t = λ t r i t = 0 λ^t_{id} = λ^t_{tri} = 0 λidt=λtrit=0 for the two-step training strategy in Section 3.1.
The baseline model performances are present in Table 2 as “Baseline (only L i d t L^t_{id} Lidt & L t r i t L^t_{tri} Ltrit)”.
Effectiveness of the soft softmax-triplet loss.
We also verify the effectiveness of soft softmaxtriplet loss with softly refined triplet labels in our proposed MMT framework.
Experiments of removing the soft softmax-triplet loss, i.e., λ t r i t = 0 λ^t_{tri} = 0 λtrit=0 in equation 9, but keeping the hard softmax-triplet loss (equation 6) are conducted, which are denoted as “Baseline+MMT-500 (w/o Ltstri)”.
EffectivenessofMutualMean-Teaching.
We propose to generate on-line refined soft pseudo labels for one network with the predictions of the past average model of the other network in our MMT framework ,i.e., the soft labels for network1 are output from the average model of network2 an dvice versa.
Necessity of hard pseudo labels in proposed MMT.
To investigate the contribution of L i d t L^t_{id} Lidt in the final training objective function as equation 9, we conduct two experiments.
- (1) “Baseline+MMT-500 (only L s i d t L^t_{sid} Lsidt & L s t r i t L^t_{stri} Lstrit)” by removing both hard classification loss and hard triplet loss with λ i d t = λ t r i t = 1 λ^t_{id} = λ^t_{tri} = 1 λidt=λtrit=1;
- (2)“Baseline+MMT-500 (w/o L i d t ) L^t_{id}) Lidt)” by removing only hard classification loss with λ i d t = 1 λ^t_{id} = 1 λidt=1.
5 CONCLUSION
In this work, we propose an unsupervised Mutual Mean-Teaching (MMT) framework to tackle the problem of noisy pseudo labels in clustering-based unsupervised domain adaptation methods for person re-ID. The key is to conduct pseudo label refinery to better model inter-sample relations in the target domain by optimizing with the off-line refined hard pseudo labels and on-line refined soft pseudo labels in a collaborative training manner. Moreover, a novel soft softmax-triplet loss is proposed to support learning with softly refined triplet labels for optimal performances. Our method significantly outperforms all existing person re-ID methods on domain adaptation task with up to 18.2% improvements.
这篇关于【MMT】ICLR 2020: MMT(Mutual Mean-Teaching)方法,无监督域适应在Person Re-ID上性能再创新高的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



