本文主要是介绍梯度提升回归(Gradient boosting regression,GBR) 学习笔记以及代码实现permutation_importance(PI),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1.介绍
- 1.1 集成学习
- 1.2 Boosting与 Bagging区别
- 1.3 Gradient Boosting算法
- 1.4 终极组合GBR
- 2.代码实现
- 特征重要性排序–Permutation Importance
- PI优点
- PI思想以及具体实施流程:
- 补充:我们自己定义模型的特征重要性排序
1.介绍
梯度提升回归(Gradient boosting regression,GBR)是一种从它的错误中进行学习的技术。它本质上就是集思广益,集成一堆较差的学习算法进行学习。有两点需要注意:
①每个学习算法准确率都不高。但是它们集成起来可以获得很好的准确率。
②这些学习算法依次应用。也就是说每个学习算法都是在前一个学习算法的错误中学习
1.1 集成学习
Boosting是一种机器学习算法,常见的机器学习算法有:
决策树算法、朴素贝叶斯算法、支持向量机算法、随机森林算法、人工神经网络算法、Boosting与Bagging算法(回归算法)、关联规则算法、EM(期望最大化)算法、深度学习。
一般集成学习会通过重采样获得一定数量的样本,然后训练多个弱学习器,采用投票法,即“少数服从多数”原则来选择分类结果,当少数学习器出现错误时,也可以通过多数学习器来纠正结果。
根据个体学习器之间是否存在依赖性可以分为两类算法:
1)个体学习器之间存在较强的依赖性,必须串行生成学习器: boosting类算法;
2)个体学习器之间不存在强依赖关系,可以并行生成学习器: Bagging类算法
1.2 Boosting与 Bagging区别
①Boosting是一种通用的增强基础算法性能的回归分析算法。它可以将弱学习算法提高为强学习算法,可以应用到其它基础回归算法(如线性回归、神经网络等)来提高精度。
Boosting由于各基学习器之间存在强依赖关系,因此只能串行处理,也就是说Boosting实际上是个迭代学习的过程。Boosting的工作机制为:
1)先从初始训练集中训练出一个基学习器,再根据基学习器的表现对训练样本分布进行调整,使得先前基学习器处理不当的样本在后续的训练过程中受到更多关注;
2)然后基于调整后的样本分布来训练下一个基学习器;
3)如此重复,直到基学习器数目达到事先自定的值T,然后将这个基学习器进行加权结合。
②Bagging
首先从数据集中采样出T个数据集,然后基于这T个数据集,每个训练出一个基分类器,再将这些基分类器进行组合做出预测。Bagging在做预测时,对于分类任务,使用简单的投票法。对于回归任务使用简单平均法。若分类预测时出现两个类票数一样时,则随机选择一个。Bagging非常适合并行处理。
1.3 Gradient Boosting算法
任何监督学习算法的目标是定义一个损失函数并将其最小化。
Gradient Boosting 的基本思想是:串行地生成多个弱学习器,每个弱学习器的目标是拟合先前累加模型的损失函数的负梯度,使加上该弱学习器后的累积模型损失往负梯度的方向减少。
举个简单的例子:
假设有个样本真实值为10,第一个弱学习器拟合结果为7,则残差为10-7=3;使残差3作为下一个学习器的拟合目标,第二个弱学习其拟合结果为2;
则这两个弱学习器组合而成的 Boosting 模型对于样本的预测为7+2=9;以此类推可以继续增加弱学习器以提高性能。
和其他boost方法一样,梯度提升方法也是通过迭代的方法联合弱”学习者”联合形成一个强学习者。
1.4 终极组合GBR
GBR的弱学习器是回归算法常见的回归算法:
线性回归、逻辑回归、多项式回归、逐步回归、岭回归、套索回归、弹性回归
其他GB算法:
梯度提升回归树、梯度提升决策树
2.代码实现
# 导入相关包
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from pylab import *
from matplotlib.ticker import MultipleLocator
from sklearn import datasets, ensemble
from sklearn.inspection import permutation_importance
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
# 数据集准备,将数据集分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=201)
# 定义模型参数进行训练
params = {"n_estimators": 500,"max_depth": 4,"min_samples_split": 5,"learning_rate": 0.01,
}
reg = ensemble.GradientBoostingRegressor(**params)
reg.fit(X_train, y_train)
模型的参数见以下链接:
https://blog.csdn.net/weixin_34005042/article/details/93812542
# 可视化训练集和测试集数据
ytrain_pre = reg.predict(X_train)
ytest_pre = reg.predict(X_test)fig,ax = plt.subplots(figsize=(8, 8), dpi= 80)
plt.rcParams['font.sans-serif'] = ['Arial'] #字体均为 Arial
plt.rcParams['axes.unicode_minus']=Falsescatter1 = plt.scatter(x=y_train, y=ytrain_pre, s=80, marker='s',c='#FFBCDE' , alpha=0.8, label='train data', linewidths=0.3, edgecolor='#17223b')
scatter2 = plt.scatter(x=y_test, y=ytest_pre,s=80, marker='s',c='#00C8F4' ,alpha=0.8, label='test data', linewidths=0.3, edgecolor='#17223b')
ax.plot([0,1],[0,1],'--',c='black',alpha=0.3)
plt.legend(loc='upper left',fontsize=20, frameon=True ,labelspacing=0.5)
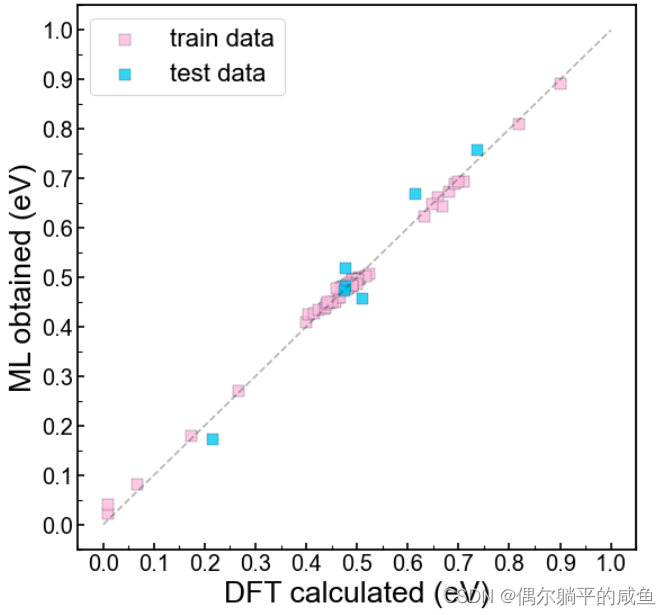
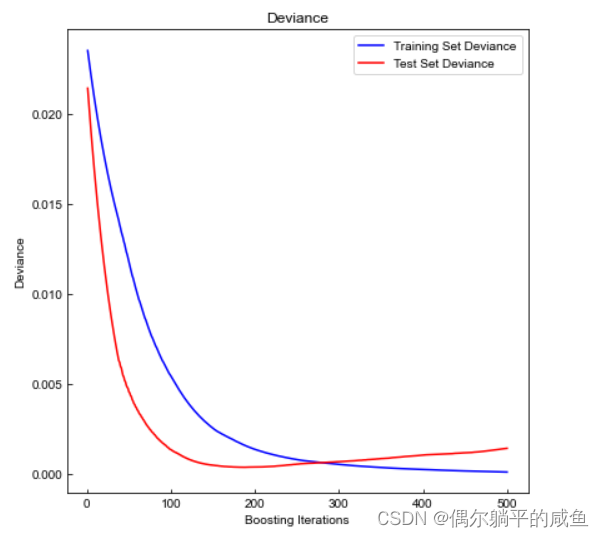
# 训练过程可视化
test_score = np.zeros((params["n_estimators"],), dtype=np.float64)
for i, y_pred in enumerate(reg.staged_predict(X_test)):test_score[i] = reg.loss_(y_test, y_pred)fig = plt.figure(figsize=(6, 6))
plt.subplot(1, 1, 1)
plt.title("Deviance")
plt.plot(np.arange(params["n_estimators"]) + 1, reg.train_score_, "b-", label="Training Set Deviance", )
plt.plot(np.arange(params["n_estimators"]) + 1, test_score, "r-", label="Test Set Deviance")
plt.legend(loc="upper right")
plt.xlabel("Boosting Iterations")
plt.ylabel("Deviance")
fig.tight_layout()
plt.show()
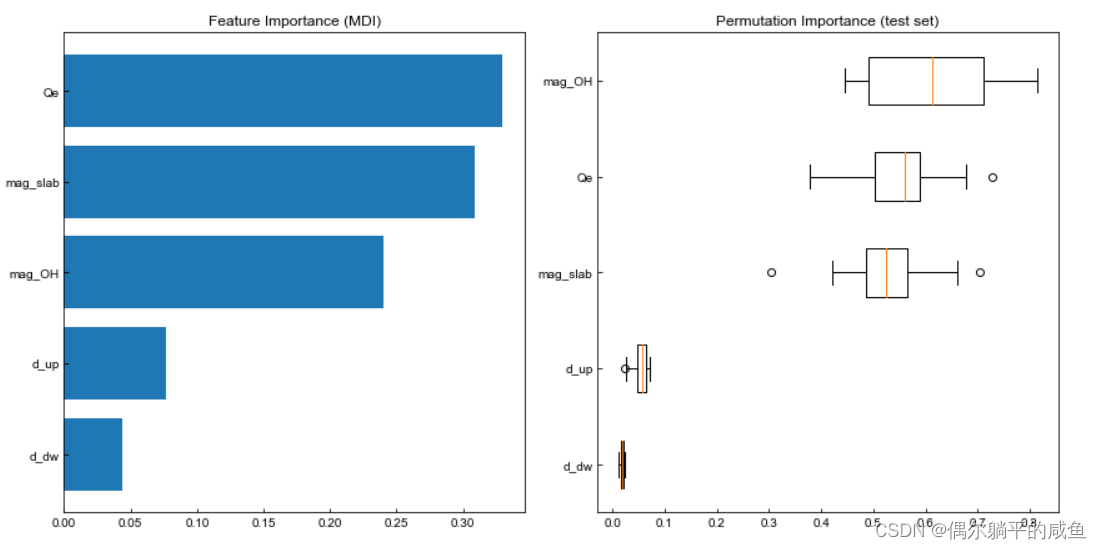
# 查看模型的特征重要性排序和PI
feature_importance = reg.feature_importances_
sorted_idx = np.argsort(feature_importance)
pos = np.arange(sorted_idx.shape[0]) + 0.5
fig = plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.barh(pos, feature_importance[sorted_idx], align="center")
plt.yticks(pos, np.array(fearture_name)[sorted_idx])
plt.title("Feature Importance (MDI)")result = permutation_importance(reg, X_test, y_test, n_repeats=15, random_state=12, n_jobs=1
)
# print(result)
sorted_idx = result.importances_mean.argsort()
plt.subplot(1, 2, 2)
plt.boxplot(result.importances[sorted_idx].T,vert=False,labels=np.array(fearture_name)[sorted_idx],
)
plt.title("Permutation Importance (test set)")
fig.tight_layout()
plt.show()
# 计算MSE和拟合优度R^2
train_mse = mean_squared_error(y_train, reg.predict(X_train))
test_mse = mean_squared_error(y_test, reg.predict(X_test))
train_score = reg.score(X_train,y_train)
test_score = reg.score(X_test,y_test)
print("The mean squared error (MSE) on train set: {:.4f}".format(train_mse))
print("The mean squared error (MSE) on test set: {:.4f}".format(test_mse))
print("The R^2 on train set: {:.4f}".format(train_score))
print("The R^2 on test set: {:.4f}".format(test_score))
附:计算拟合优度的另一种方法
Regression = sum((y_pre - np.mean(y_train))**2) # 回归平方和
Residual = sum((y_train - y_pre)**2) # 残差平方和
total = sum((y_train-np.mean(y_train))**2) #总体平方和
R_square = 1-Residual / total
R_square
特征重要性排序–Permutation Importance

PI优点
相比于其他衡量特征重要性的方法,Permutation Importance的优点:
①计算量低
②广泛使用和容易理解
③与我们要测量特征重要性的属性一致
PI思想以及具体实施流程:
PI思想:
• 用上全部特征,训练一个模型。
• 验证集预测得到得分。
• 验证集的一个特征列的值进行随机打乱,预测得到得分。
• 将上述得分做差即可得到特征x1对预测的影响。
• 依次将每一列特征按上述方法做,得到每二个特征对预测的影响。
具体实施流程:
①训练模型
②打乱其中一列的数据,用该数据集进行预测,评估预测精度下降来提现该特征变量的重要性
③将验证数据集还原,并重复第二步,分析其他特征变量
sklearn.inspection.permutation_importance PI相关参数
补充:我们自己定义模型的特征重要性排序
COLS= ['f1', 'f2' ,'f3', 'f4', 'f5' ,'f6']
results_train= []
for k in range(len(COLS)): # X_train, y_train# 打乱第k列save_col = X_train[:,k]np.random.shuffle(X_train[:,k])# 计算第k列的特征重要性(用MAE或者MSE衡量)oof_preds = model(X_train) mae = np.mean(np.abs( oof_preds - y_train ))mse = np.mean(( oof_preds - y_train )**2)results_train.append({'feature':COLS[k],'mae':mae})results_train.append({'feature':COLS[k],'mse':mse})X_train[:,k] = save_col
print(results_train)
这篇关于梯度提升回归(Gradient boosting regression,GBR) 学习笔记以及代码实现permutation_importance(PI)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





