本文主要是介绍Deep AutoEncoder-based Lossy Geometry Compression for Point Clouds,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Deep AutoEncoder-based Lossy Geometry Compression for Point Clouds
https://arxiv.org/abs/1905.03691
Sampling layer
在G-PCC中,基于八叉树的几何编码根据量化尺度来控制有损几何压缩,设输入点云为:
G-PCC编码器的量化计算如下:

其中 X s h i f t X_{shift} Xshift和 s s s是用户人工定义的参数。
量化后,将有许多重复点共享相同的量化位置。一种常见的方法是合并这些重复的点,这样可以减少输入点云中的点数。
受G-PCC的启发,这篇文章将点云进行下采样后输再输入编码器。输入点 x 1 , x 2 , … , x n {x_1,x_2,…,x_n} x1,x2,…,xn,被最远点采样(FPS)得到子集 x i 1 , x i 2 , … , x i m {x_{i_1},x_{i_2},…,x_{i_m}} xi1,xi2,…,xim,其中 x i j x_{i_j} xij是距离已采样点集 x i 1 , x i 2 , … , x i j − 1 {x_{i_1},x_{i_2},…,x_{i_{j-1}}} xi1,xi2,…,xij−1最远的点。与随机采样相比,FPS采样得到的点集的密度更均匀,更能保持原始对象的形状特征。
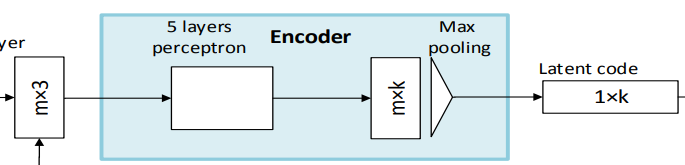
Encoder and Decoder
编码器使用PointNet:
解码器使用全连接网络:

Quantization
用加性均匀噪声代替量化:
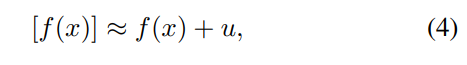
Rate-distortion Loss
率: non-parametric and fully factorized density model
失真:Chamfer distance
结果
数据集:ShapeNet
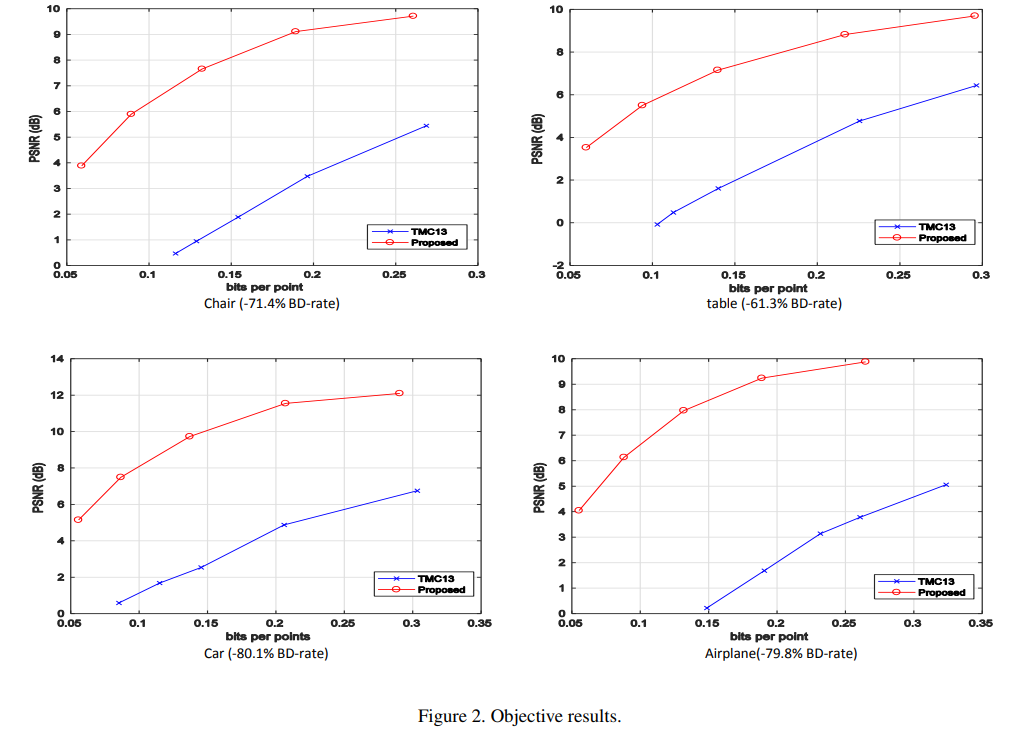

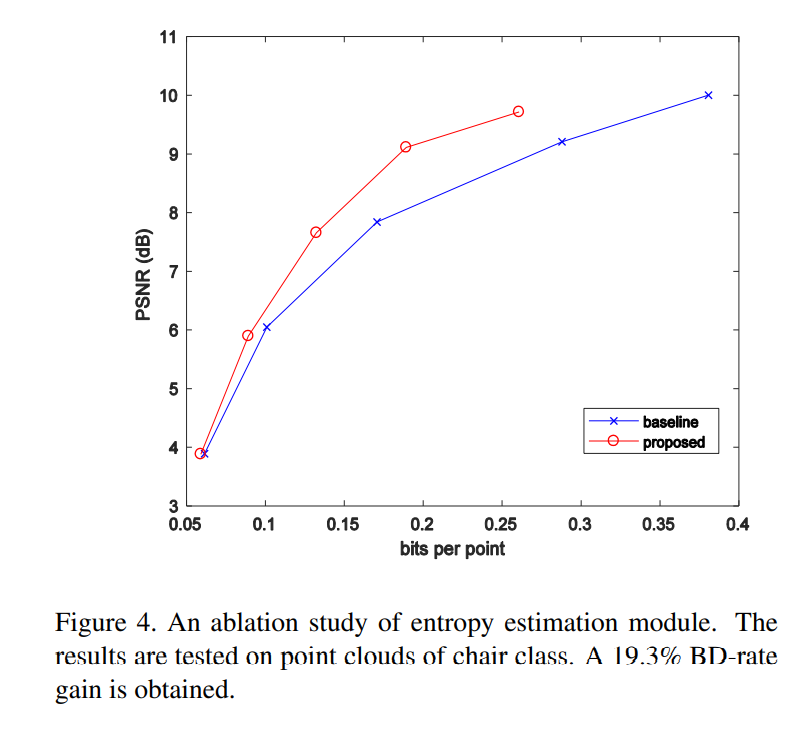
这篇关于Deep AutoEncoder-based Lossy Geometry Compression for Point Clouds的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








