本文主要是介绍[论文精读]A-GCL: Adversarial graph contrastive learning for fMRI analysis to diagnose neurodevelopmental,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文全名:A-GCL: Adversarial graph contrastive learning for fMRI analysis to diagnose neurodevelopmental disorders
论文原文:A-GCL: Adversarial graph contrastive learning for fMRI analysis to diagnose neurodevelopmental disorders - ScienceDirect
论文代码:GitHub - qbmizsj/A-GCL: MedIA 2023
英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用!
目录
1. 省流版
1.1. 心得
1.2. 论文框架图
2. 原文逐段阅读
2.1. Abstract
2.2. Introduction
2.2.1. Related work
2.2.2. Contribution
2.3. Method
2.3.1. Graph construction
2.3.2. A-GCL
2.3.3. Classification and interpretation
2.3.4. Implementation details
2.4. Results
2.4.1. Experimental setup
2.4.2. Classification performance
2.4.4. Interpretation
2.5. Discussion and conclusion
2.5.1. Impact of atlas selection
2.5.2. Transfer learning between the two ABIDE datasets
2.5.3. Conclusion
3. Reference List
1. 省流版
1.1. 心得
(1)数学部分略显逆天
(2)整体框架图我是真的难评
(3)原文3.1.2给出了很多其他论文的代码
(4)曾在论文模型分类对比的时候怀疑过会不会是其他模型没训练好/参数没调合适,但是给自己模型调很好,但是被张老师以(如下图)驳回


(5)Fig2,3,4,5放的位置怎么回事
(6)有很多消融实验
(7)Discussion有点单薄啊,而且为什么discussion和conclusion放一起啊
(8)那你迁移学习不好不就代表泛化性差吗
(9)纯纯分类性能了
1.2. 论文框架图

2. 原文逐段阅读
2.1. Abstract
(1)Background: neurodevelopmental disorder diagnosis is limited to time consuming and biases from different examiners
(2)Model: they put forward adversarial self-supervised graph neural network based on graph contrastive learning (A-GCL)
(3)Data processing: fMRI, with feature classification.
(4)Node feature: 3 bands (波段) of the amplitude of low-frequency fluctuation (ALFF)
(5)Edge weight: average fMRI time series in different brain regions
(6)Contrastive learning: Bernoulli mask
(7)Dataset: ABIDE I, ABIDE II and ADHD-200
(8)Atlas: AAL1, AAL3, Shen268
2.2. Introduction
(1)Functional connectivity (FC) in resting-state functional Magnetic Resonance Imaging (rs-fMRI) mostly analysed by clinical experts themselves.
(2)In this paper, authors define normal controls as NC.
2.2.1. Related work
(1)Machine learning (ML) as SVM, MLP, RF, CNN, convolution-based autoencoder and deep learning (DL) as GNN made great progress in computer-aided diagnosis (CAD). (我想吐槽一下就是我在很多其他论文里面看到的都举的是很新的更针对脑科学的例子,这里全放这么早期又这么经典的...感觉略显敷衍...还是说这作者找不到那些代码来比对啊哈哈哈哈)
(2)⭐There are two categories of GNN, namely graph classification and node classification
(3)Graph classification: define a single brain as a graph. Such as BrainGB, BrainGNN, spatio-temporal attention GNN, node-edge graph attention network (NEGAT).
(4)Node classification: guess that each person constructs one graph. Such as: hierarchical graph convolutional network (GCN) etc.
(5)Graph contrastive learning (GCL): regard augmented version as positive sample which is close to original graph, put others as negative sample which are far away from original graph (什么玩意儿?)
(6)Limitations of GNN:
①Parameter update
②Adjacency matrix only ignores features of nodes
③Arbitrary truncation causes unsatisfactory creation of positive samples
canonical adj.典型的;经典的;(数学表达式)最简洁的;被收入真经篇目的;按照基督教会教规的
truncate vt.截断;截短,缩短,删节(尤指掐头或去尾) adj.截短的;被删节的
2.2.2. Contribution
(1)Adopt 3 bonds in ALFF from blood oxygen level-dependent (BOLD) signals
(2)A-GCL mainly foucs on edge-dropped version
(3)A-GCL do not drop any BOLD signal
(4)Build a dynamic memory bank which adopt queue structure to store samples from the same patch and different patch. This method save the memory of GPU and icrease the number of negative sample. All these are for the performance of model is highly rely on the number of negative sample.
(5)Conlusion of contributions
①Adversarial contrastive learning with a dynamic memory bank
②Multiple datasets and atlases(额,严格来说我觉得也不是特别大的贡献)
③Ablation study(其实我觉得这个严格来说也不算什么新的,但是作者在这好像提出了很多种消融实验啊。等我往后看看再说,是什么消融多样化吗)
④Explanation
(6)Information of graph and framework of A-GCL
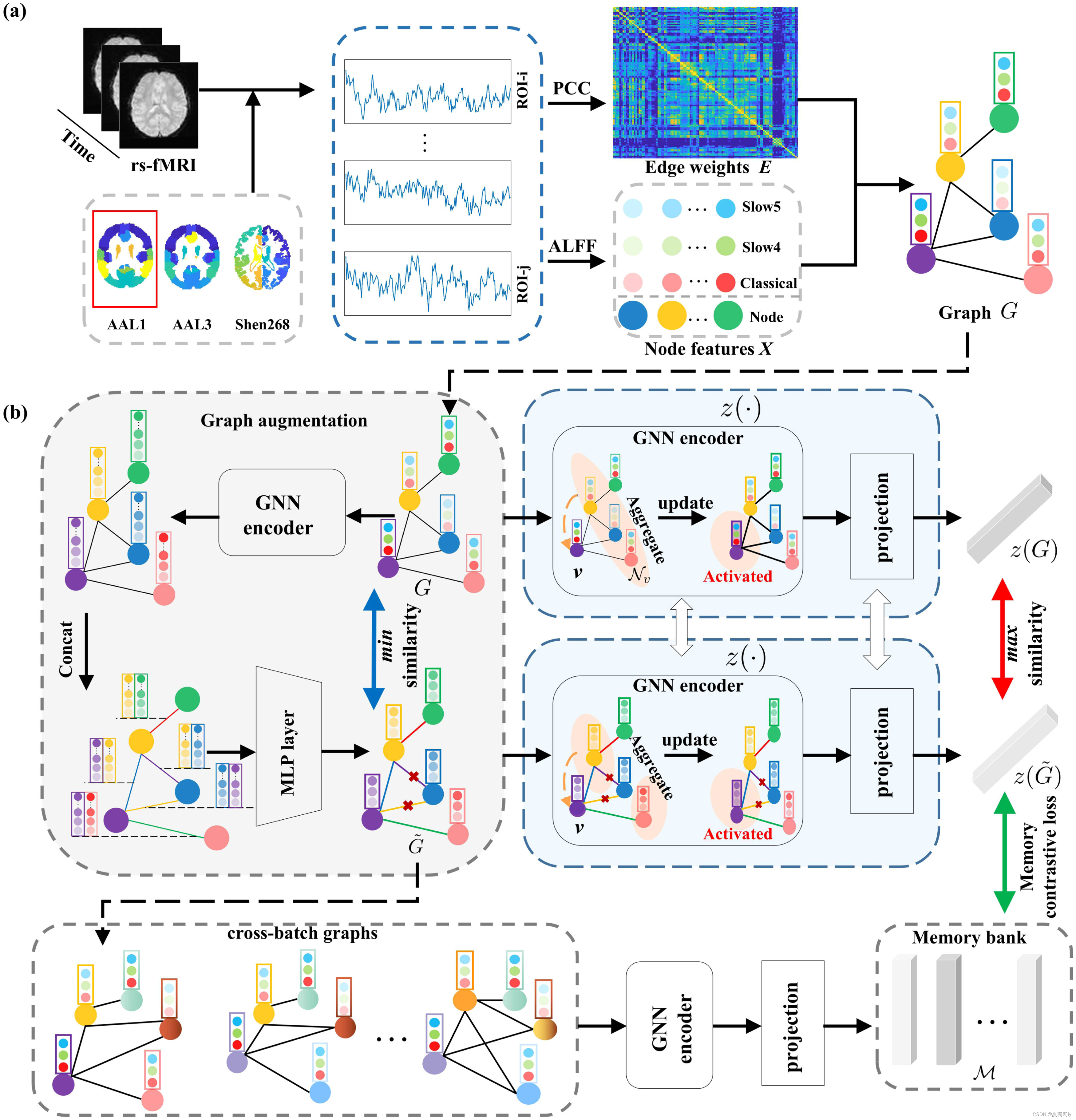
2.3. Method
2.3.1. Graph construction
(1)Authors set each ROI as a node, functional connectivity between ROI as an edge
(2)Mean time series: average of all BOLD signals in one region
(3)Edge weight: Pearson’s correlation coefficient (PCC) between mean time series in two regions
(4)Node feature: combine 3 ALFFs (Slow-5: 0.01–0.027 Hz, Slow-4: 0.027–0.073 Hz, classical: 0.01–0.08 Hz) in low-frequency range, then use Fourier transform of the mean time series
(5)Settings of graph
where and
denotes node set,
denotes the number of ROIs;
,
denotes adjacency matrix. All the existing edges are set by 1, otherwise 0;
,
denotes node features set;
,
denotes the edge weight matrix.
Besides, node features are normalized by:
where denotes the channel value(这个我自己设的,我也不知道是什么啊),
denotes original node feature;
The edge weights are normalized by:
where denotes original edge weight.
2.3.2. A-GCL
(1)Graph augmentation
①Structure: graph isomorphism network (GIN) → feature concatenation → MLP
②GIN block
where denotes all the neighbor nodes of node
;
;
is a funcion that adding features and edge weights together to a vector;
is MLP layer;
Therefore, the function can be rewritten as:
③Matrix form of GIN block
where ;
denotes Hadamard product;
denotes (???为什么说是M维全1的向量啊??不应该是个矩阵吗);
are trainable parameters;
denotes batch normalization;
④MLP layer
where are trainable parameters;
, because there are two layers of GIN,
reperesents the feature after learning;
Also, denotes a combination of edge features.
④Dropout
where , and drop any data if
;
;
denotes a temperature parameter which controls the smoothness;
when
;
when
.
⑤Summary of data augmentation
All in all, the process of augmentation can be written as ,
where
isomorphism n.同构;类质同象;类质同晶型(现象);同(晶)型性
(2)Dynamic memory bank and loss function design
①Loss function 1 for bringing the same image feature closer and separating different image features
(什么是resp.)
where is a batch of graph sets,
is its cardinality(基数又是什么).
②Similarity metric
③Keep on droping out and minimize (?)
④Loss function 2
where stores the previous batch of
in queue structure and is initialized by 0.
⑤Objeective function
where and
are regularization coefficients;
and gradient descent/ascent bring and
. (???????????)
2.3.3. Classification and interpretation
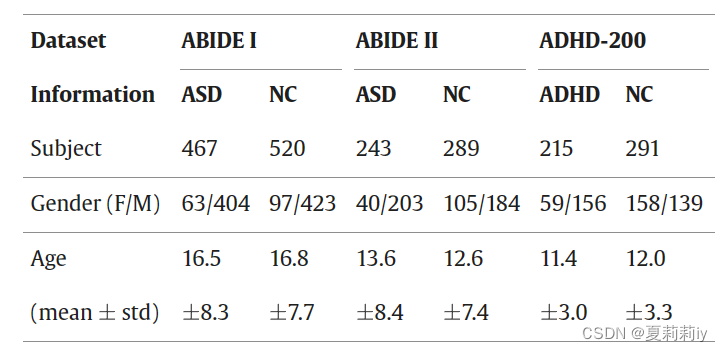
(1)Put SVM classifier in datasets:
(2)Interpretation
①Visualize the important connections in sparse graph
②Add all elements in one row in matrix as importance score. The score represents the degree of ROI connects
2.3.4. Implementation details
(1)Their experiment
①Framework: PyTorch
②Code: GitHub - qbmizsj/A-GCL: MedIA 2023GitHub - qbmizsj/A-GCL: MedIA 2023GitHub - qbmizsj/A-GCL: MedIA 2023
③Learning rate: 0.0005
④Embedded dimension : 32
⑤Batch size: 32
⑥The temperature : 1
⑦Regularization coefficient:
⑧Length of : 256
(2)For new dataset
①Recommended batch size: 8 or 16 or 32 or 64
②Recommended learning rate :
2.4. Results
2.4.1. Experimental setup
(1)Dataset and preprocessing
①fMRI processing pipeline: fMRIPrep
rs-fMRI reference image estimation, head-motion correction, slice timing correction, and susceptibility distortion correction are performed. For confounder removal, framewise displacement, global signals, and mean tissue signals are taken as the covariates and regressed out after registering the fMRI volumes to the standard MNI152 space.
②Define how they calculate time series, ALFF node features and FC matrix
③Setting 3 atlas, AAL1 with 116 regions, AAL3 with 166 regions, Shen268 with 268 regions
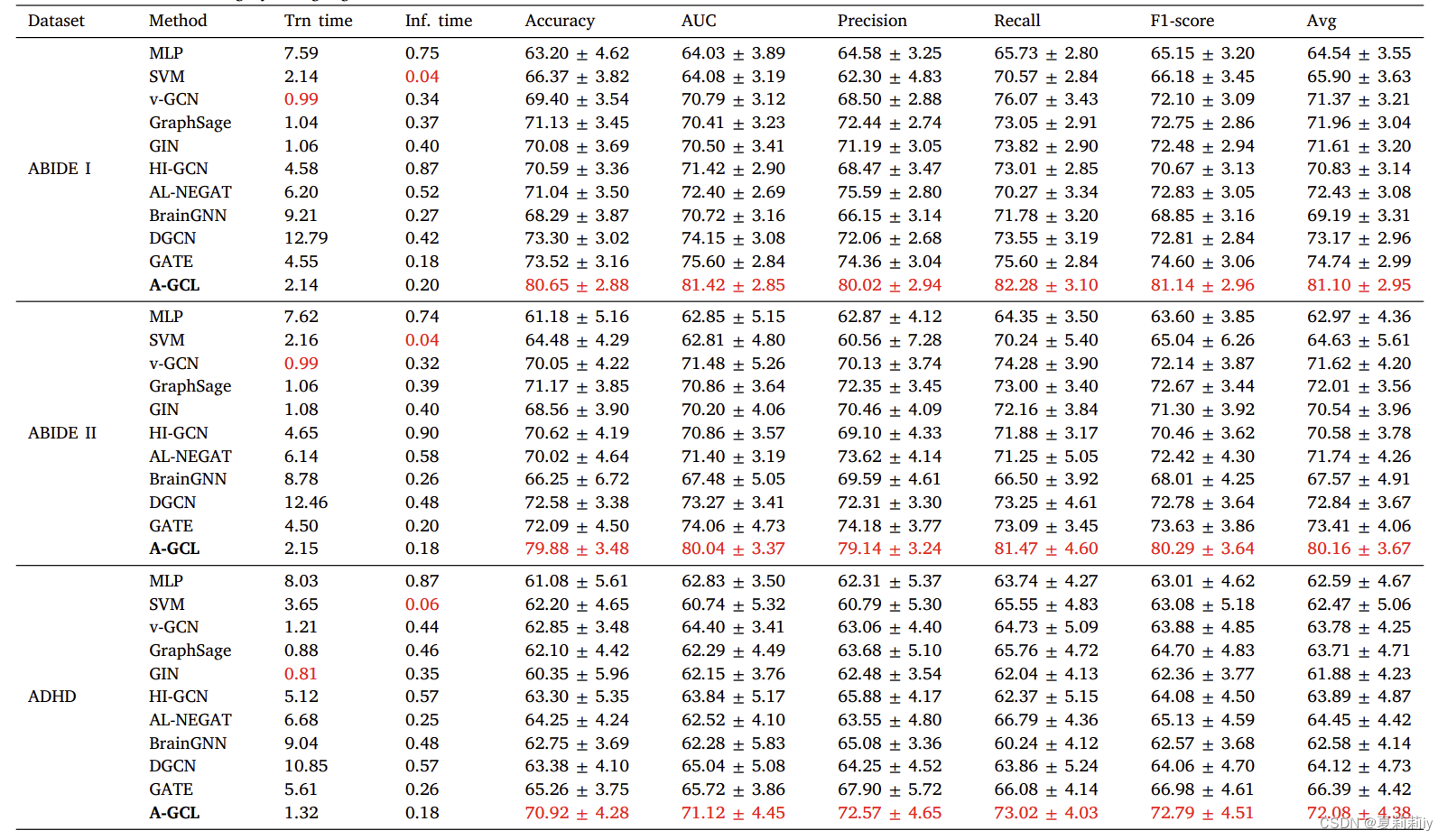
④Classification accuracy table in AAL1, while AAL3 and Shen268 are for examing the robustness in ablation study. Additionally, Trn time is training time and Inf. time is inference time
phenotypic adj.表(现)型的
confounder n.混淆;混杂因素;混杂变量;混杂因子;干扰因子
(2)Competing methods
①Provide the parameters setting in other models above
②⭐Provide codes of other models
(3)Evaluation strategy
①metrics: accuracy, sensitivity, specificity, F1-score, and AUC
②validation: 5 fold cross-validation
2.4.2. Classification performance
①Contrastive learning performs well in classification
②They compare data from 5-fold cross validation
(1)Transfer learning for ABIDE datasets
①Transfer learning on ABIDE I and ABIDE II
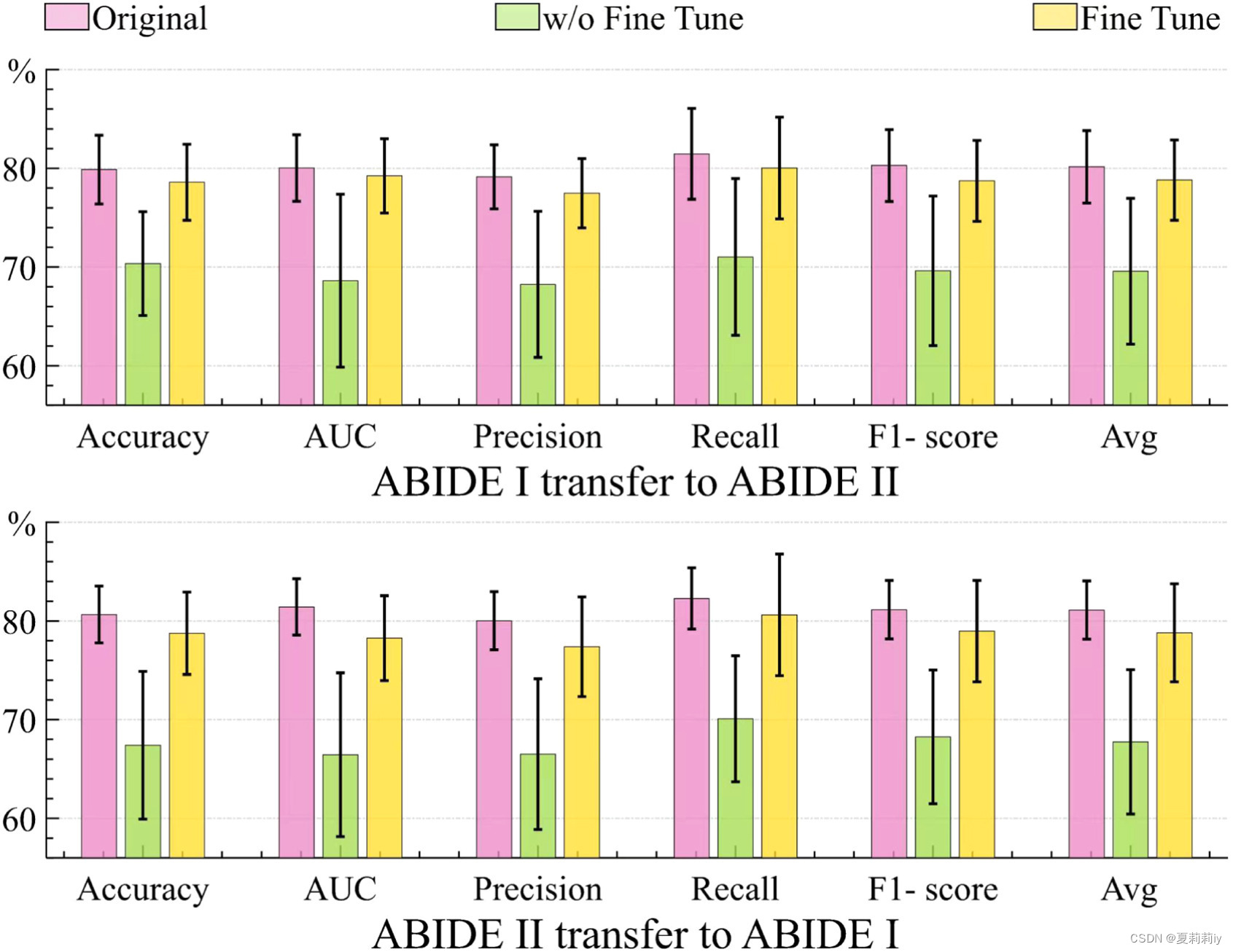
②The performance in transfer learning decrease 10% but still high
2.4.3. Ablation studies
(1)Influence of different atlases on the three datasets
①Shen268 with more regions gets lower performance
②From 116 (AAL1) to 166 (AAL3) regions, ABIDE I is getting better but ABIDE II is not.
(2)Effectiveness of edge weights and node features
①Ablation study on how ALFF and FC influence the fMRI classification
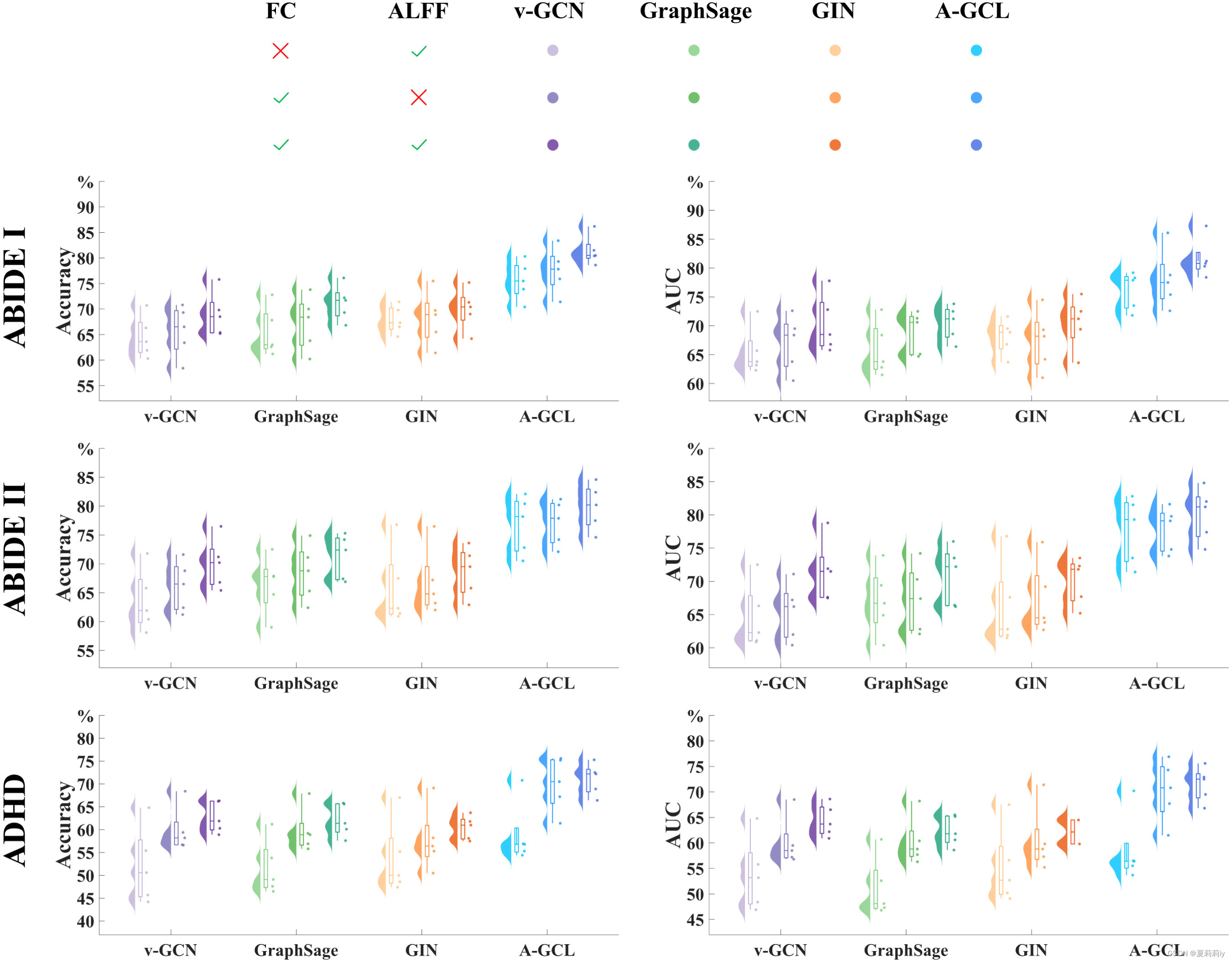
where the first vertical line is setting all elements in FC matrix to 1, the second vertical line is setting all elements to 1 in ALFF feature vector.
(3)Influence of the GNN encoder
①Ablation study with a (a) atlases, (b) GNN encoders, and (c) edge-dropping strategies:
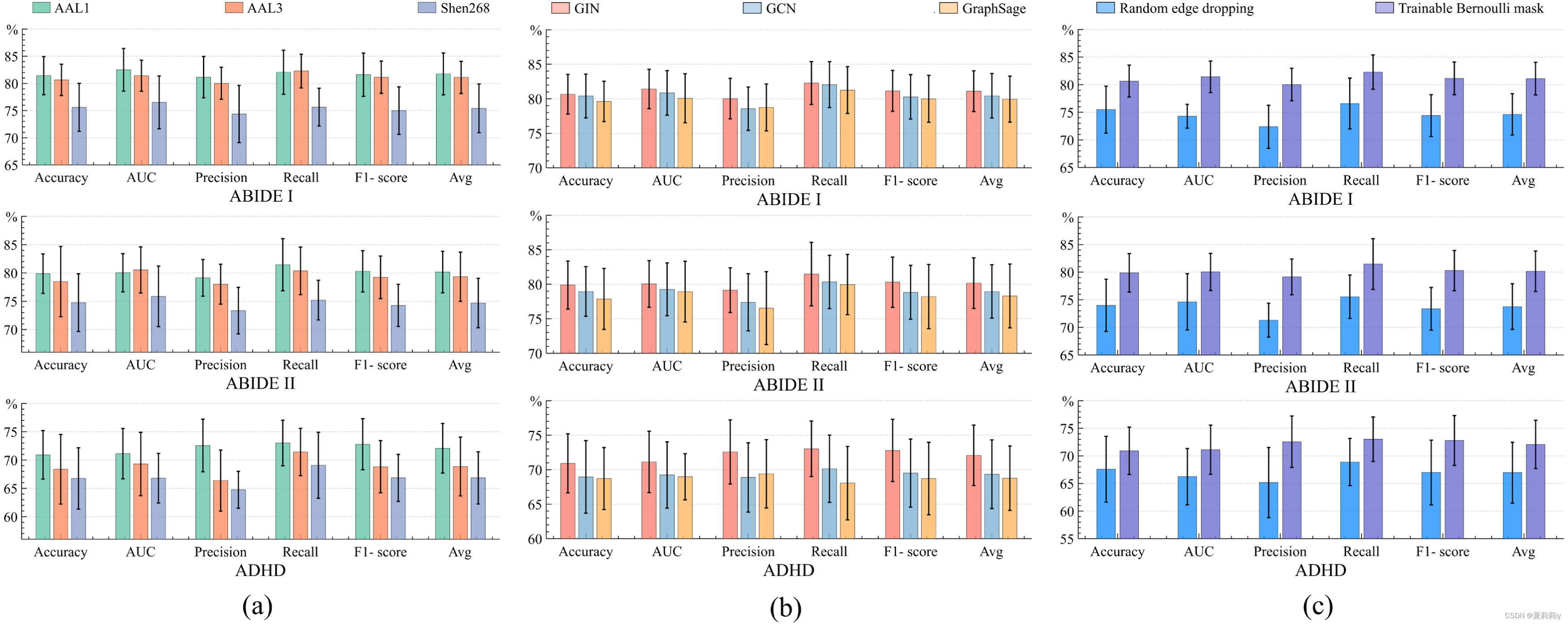
and presents robustness in different encoder.
(4)Influence of the graph augmentation strategy
①Normally the augmentation methods are random rotation, intensity scaling and random dropout
②The Bernoulli mask approach shows above (c) indicates its effectiveness
(5)Influence of the embedding dimension
①Ablation study on whether the embedding dimension will influence the classification performance, where the vertical lines are standard deviation:
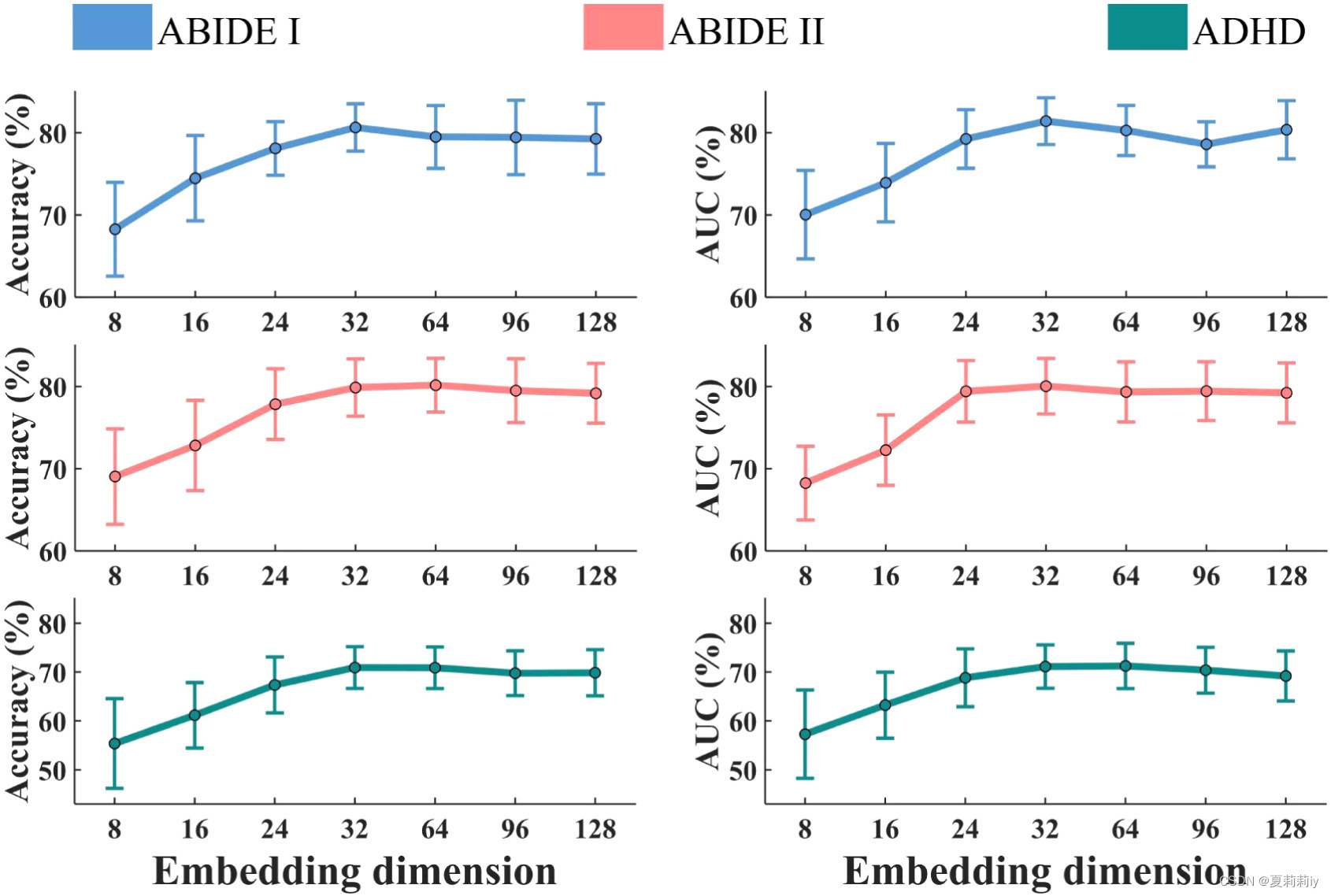
In this picture, authors reckon the more the dimension, the higher the accuracy and AUC value. However, they still guess 32 is the best dimension in that after that, the performance is getting steady but computing time increases sharply.
(6)Influence of λ1, λ2, and the max–min loss function
①The original adversarial loss function is:
However, for ablation study, authors change the function to
② How and
works in AAL1, where A denotes adversarial, NA denotes non-adversarial
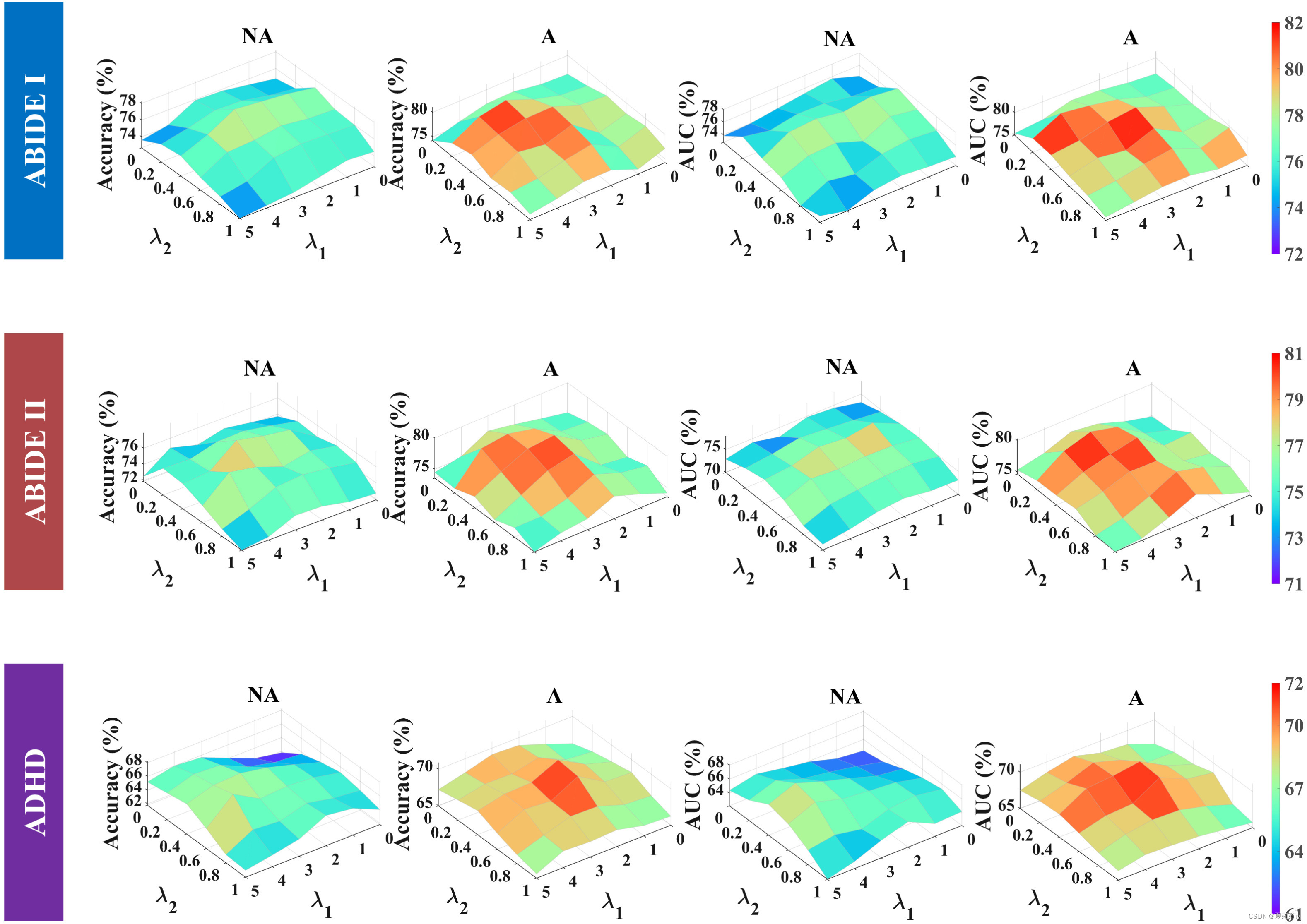
2.4.4. Interpretation
(1)Visualization of the learned Bernoulli mask
①Pictures of matrices and maps:

only the top 20% maps are shown above in that the whole FC maps are too dense.
②The correlation between two datasets are calculated by edge-dropped FC matrices/remaining FC matrices. Accordingly, the correlation coefficient between ABIDE I and ABIDE II is 0.8328, between ABIDE I/II and ADHD are 0.1422/0.1758.
(2)Visualization of the important brain regions
①Top 10 important regions
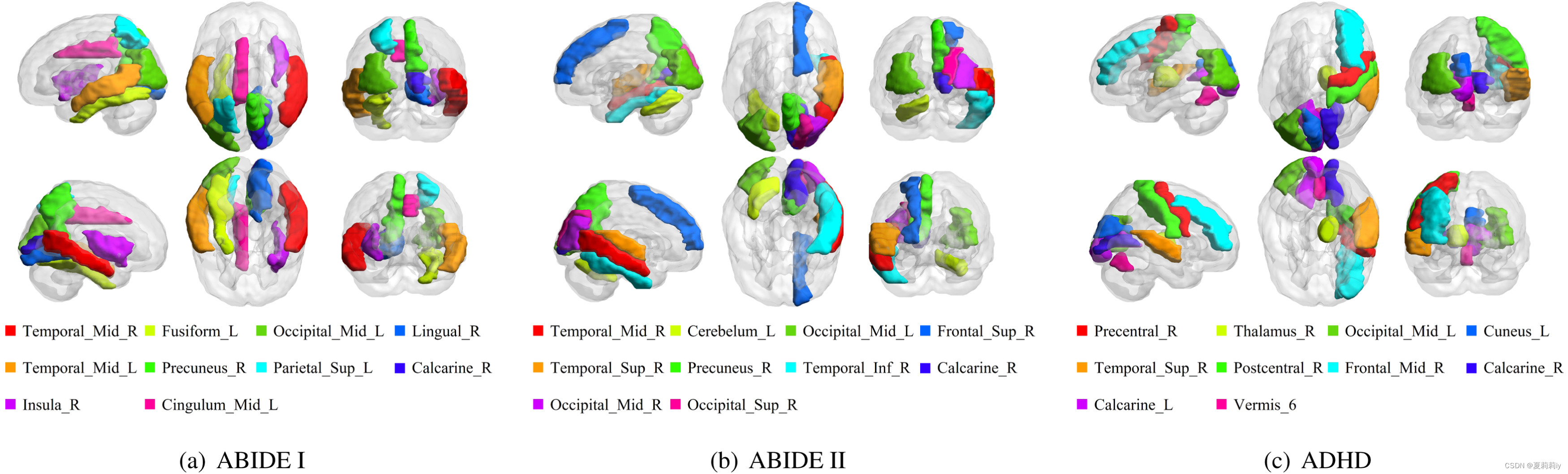
where they are calculated by the sum of FCs of a node in the edge-dropped graph, namely
2.5. Discussion and conclusion
2.5.1. Impact of atlas selection
(1)Authors speculate that more detailed partitioning in Shen268 results in a decrease in the average number of voxels that can be calculated. It also reduces noise suppression.
(2)On the other hand, there are more nodes in matrices which brings difficulty for calculating and optimization
(3)Authors suggest that reseachers can combine atlas to increase performance(这玩意儿真的能结合吗得看医生吧?)
2.5.2. Transfer learning between the two ABIDE datasets
Authors attribute the poor generalization ability to significant differences between the two datasets...
2.5.3. Conclusion
They combine different atlases, datasets, create A-GCL.
3. Reference List
Zhang, S. et al. (2023) 'A-GCL: Adversarial graph contrastive learning for fMRI analysis to diagnose neurodevelopmental disorders', Medical Image Analysis. vol. 90, 102932, doi: Redirecting
这篇关于[论文精读]A-GCL: Adversarial graph contrastive learning for fMRI analysis to diagnose neurodevelopmental的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)


