本文主要是介绍智能分析平台叠加AI,观远数据行业首发「AI预测引擎」,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前两篇我们为大家梳理了AI的演进路程以及需求预测在AI+零售命题中的行业洞察,均取得了不错的反响。在广大粉丝热烈的呼声当中,该系列笔者观远产品天团-小刚同学马不停蹄,为我们带来了AI企划的第三篇文章。本篇,他将首次公开观远智能分析平台上「AI预测引擎」的神秘面纱!
作为观远数据今年重磅推出的新模块,「AI预测引擎」不仅仅引入了先进的AI预测算法,更将观远数据团队多年与诸多500强企业合作中沉淀的、符合本土日历特征的零售数据预测经验预置进了算法模型里面,同时结合观远智能分析平台,为本土零售企业提供从数据接入、整理、预测到展现的端到端整体解决方案。

话不多说,切入正题
观远数据已经帮助联合利华、百威英博等多家500强客户实施需求预测,有大量的零售领域数据预测经验。我们看到,500强企业之所以愿意花上百万,甚至大几百万来做AI预测项目,是基于其庞大的业务体量来评估ROI后作出的选择:
• 一方面,高质量的数据预测确实需要专业的数据科学家和分析人员深入了解业务场景,不断迭代优化预测模型,经过长时间的锤炼才能获得;
• 另一方面,当业务规模足够大时,细微的预测准确度的提升都能给企业带来巨额的利润回报。
但同时,我们也意识到,不是任何企业都有这个资金实力去做此类高质量的数据预测的,并且在业务需求上也可能仅仅是想做一些初步预测来为决策提供参考。因此,为了满足这类客户的预测需求,观远数据的「AI预测引擎」将为他们提供 入门级的零售预测操作门槛,同时又能为他们提供 比一般的统计预测方法更精准的预测结果!
什么是观远数据「AI预测引擎」?
了解过观远产品的朋友们都知道,观远数据在BI平台里面内置了Smart ETL智能数据处理模块。该模块基于Spark大数据计算引擎开发,提供拖拽式、图形化的数据流开发方式,使得一般业务人员也能做专业的数据分析处理。
一般的ETL过程整理主要做的是数据的清洗、转换、关联、加载等操作,那观远的Smart ETL何以称之为智能呢?这是因为Smart ETL中除了支持Spark本身自带的函数之外,还支持自定义的UDF、UDAF函数开发,具有非常强大的智能算子扩展能力。
举个例子,如果你想挖掘商品间的潜在联系,开拓更多销售机会,你就可以使用Smart ETL内置的“关联性挖掘”这个智能算子来快速实现商品销售关联分析。
而「AI预测引擎」则是另一个重要的智能算子。你可以用它来做各种级别的销售预测,大到门店,小到品类,甚至SKU的预测。有了这些可靠的销售预测的数据,你将实现:
降低库存金额:对于库存成本较高的零售企业,通过销售预测来指导进货与库存,在保证供给的前提下,进一步降低库存金额,降低成本。
降低报废风险:对于可售时长比较短的商品(比如水果、面包、鲜食),通过精准的销售预测,来指导备货,降低报废率(并不是追求零报废),节约成本。
把握销售机会:对于潜在的销售机会,比如节日、活动、天气变化等,通过销售预测来指导提前备货,充分把握销售机会,最大化销售额。
指导排产、配送:对于可以做到自产自销的零售企业来说,准确的销售预测,还能够将预测数据倒推到生产、配送环节,指导排产、物流。
指导人员配置,优化排班:通过分时段的销售预测,来指导门店进行更为合理的数据化排班,最大化地利用人力成本,同时保障客户消费体验。
评估销售目标的进度:通过对当前累计销售额与未来销售预期的预测分析,评估销售目标的完成进度与质量。有需要的还可以及时调整销售目标,做到敏捷运营。
增强客户体验:通过进销存各个环节的预测,增强客户体验,避免各类因缺货、延迟交货、延迟发货等情况导致的客户消费体验下降的情况发生。
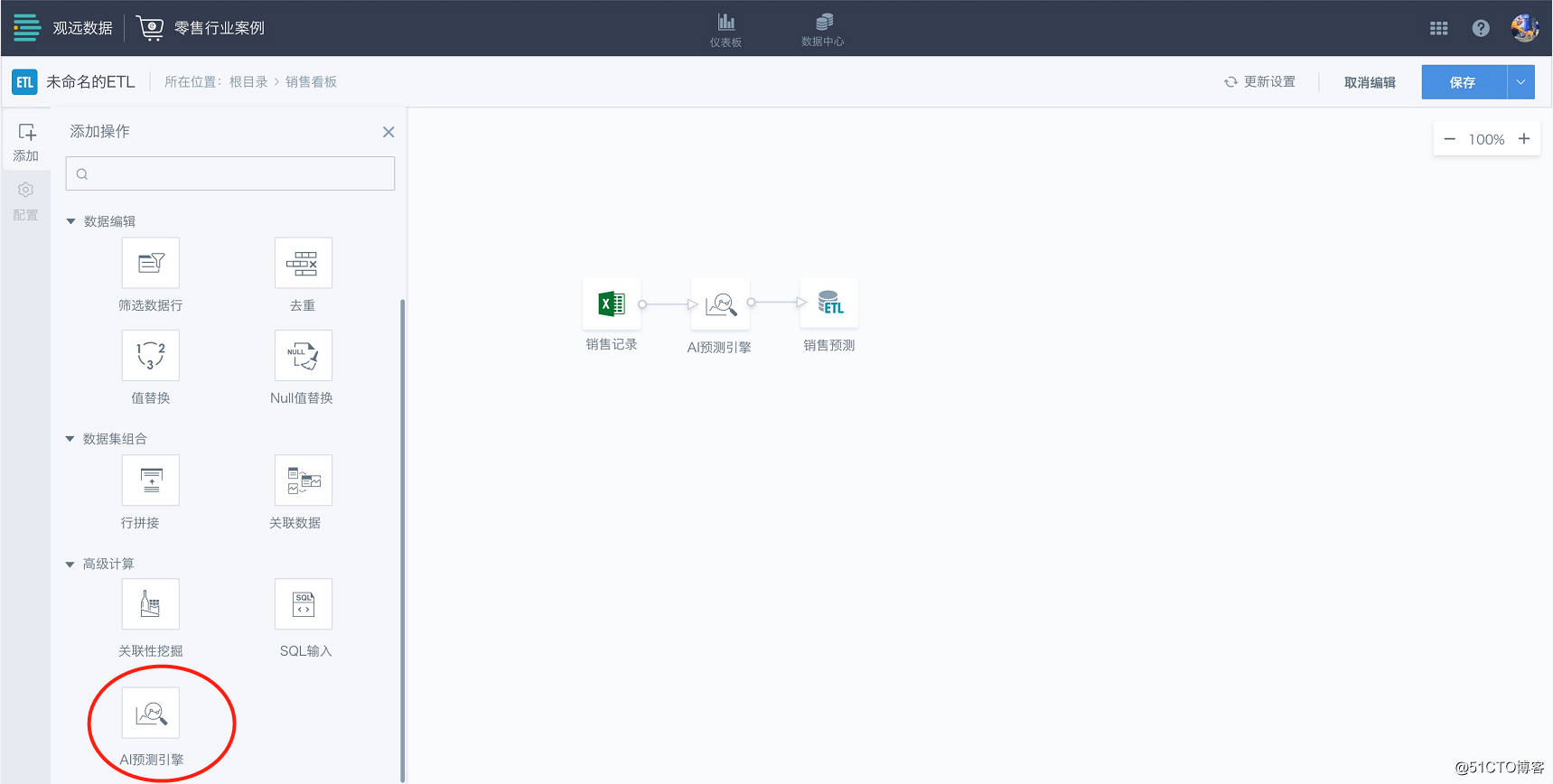
「AI预测引擎」智能算子
在观远Smart ETL中,用户仅需要拖入一个「AI预测引擎」算子,接入事先预处理好的历史数据,然后简单配置日期字段、预测指标,以及指标聚合维度(日/周/月/季度/年)和预测周期数,便可开始预测。预测结果可以输出到数据集进行下一步的展示分析与决策支持。
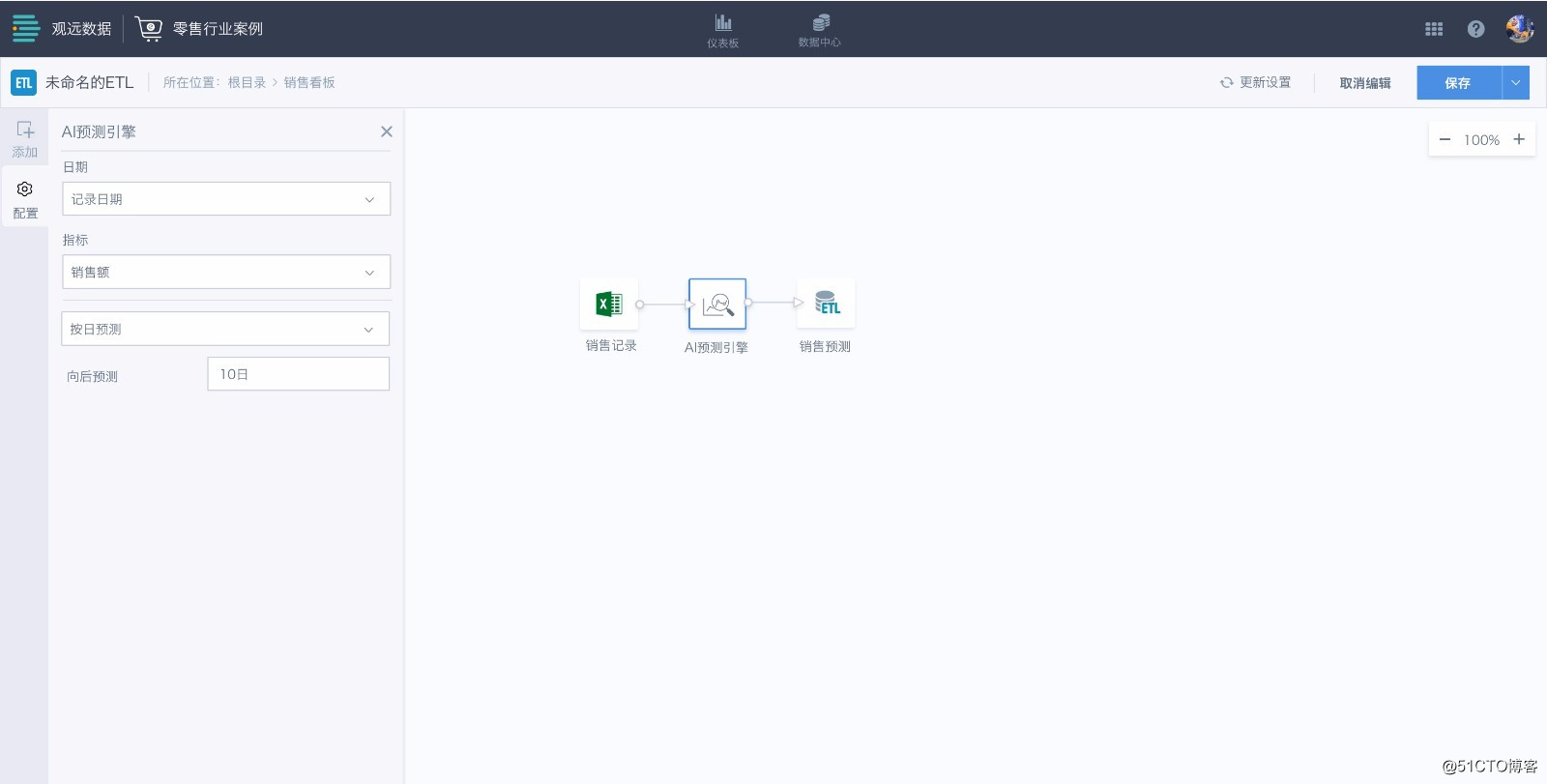
「AI预测引擎」节点配置
观远数据的「AI预测引擎」主要适用于零售企业的销售预测或需求预测。上图所示只是一个极简模式的预测算子。但即便配置如此简单,却能输出相当精准的预测结果。
• 对 零售行业门店级别(以超市数据为例)的日商预测平均准确度达到 83%(MAPE≈17.65%),个别门店 接近 90%;
• 而细化到 单门店单品类(鲜肉类)的日商预测,准确度达到84%。
在这个基础上,我们还能提供更多配置项,添加诸如天气情况、促销活动、品类级别的日期特征等外部信息,进一步提升数据预测的准确度;同时也可以提供多门店、多品类的批量预测。
架构解密
为什么如此简单的操作,便能实现还不错的销售数据预测呢?
这是因为架构层面观远数据将预测算法封装成Spark UDF函数,有机地融合进Smart ETL,成为一个可点选配置的智能算子;算法层则采用了先进的算法,并将观远数据多年沉淀的零售行业预测经验转化为相应日期特征优化配置后预置进算法包里。
如此一来,看似简单的时序预测,其实已经包含影响零售行业销售数据的周期性特征、节假日特征以及节前节后特征,这样的预测自然是要比一般时序预测方法准确度提升不少了。
未来,我们还会根据不同品类的消费特征,分别给予不同的品类特征日历,进一步提升品类甚至SKU级别的预测准确度。同时,还可以增加天气作为额外特征,这样对于一些极端天气情况下的销售预测也会进一步提升准确度了。
算法解密
具体到算法层面,为什么观远的AI智能预测算法能够比市面上通用的预测算法在预测准确度上再提升一个层级呢?
首先我们来看一般时序预测工具中常用的ARIMA模型(Autoregressive Integrated Moving Average Model)。它是一种结合自回归与移动平均方法进行预测的模型,要求时序数据是稳定的,或者通过差分化后是稳定的,一般来说很难符合现实数据的情况。与之类似的还有GARCH模型等传统时序方法,大都只能进行单变量的建模,局限性较大。
近年来涌现出更多复杂时序模型,以便解决实际业务中的复杂情况。例如比较有代表性的TBATS的预测模型,结合了Box-Cox转换,趋势拟合,ARMA建模,周期性分析等复杂技术手段来进行建模预测。它实际上是一种状态空间模型(State Space Model)的算法实现,类似的还有隐马尔可夫模型,RNN等也都属于此类。这类模型主要限制是参数繁多,计算量大,在大规模时序预测时往往需要花费很大的计算成本实现。
那零售行业现实状况是怎样的呢?我们不妨先来看看零售数据本身具有的一些特征:
趋势特征:一般销售数据在一个比较长期的时间范围内,具有整体增长或下滑的趋势特征。
周期特征:销售数据具有明显的周期性和季节性。
非规律性的节假日特征:节假日及节假日前后对销售数据有显著影响。
各类外部因素影响:促销活动、天气、搜索指数、销售指标等因素也会显著影响销售数据。
数据稀疏性:一般零售行业的SKU,门店等维度的组合会非常巨大,但每个组合中的时序数据数量往往比较有限。
基于直观的理解,我们就可以发现简单的ARIMA模型与复杂的状态空间模型对于零售数据的预测都有一定的局限之处。而观远数据则是根据具体的业务数据情况,结合使用高效的广义累加模型和状态空间模型,统筹考虑零售时序数据的趋势性、周期性,并加入对节假日及促销、天气等可预测波动因素的分析,给出综合预测结果,可以说这是一个专门为零售预测而生的算法模型!
预测结果的可视化呈现
观远数据对预测数据呈现做了定向优化,对实际数据与预测数据进行了颜色和线型的区分,并添加了预测数据的置信区间,提供时间轴的缩略展示。
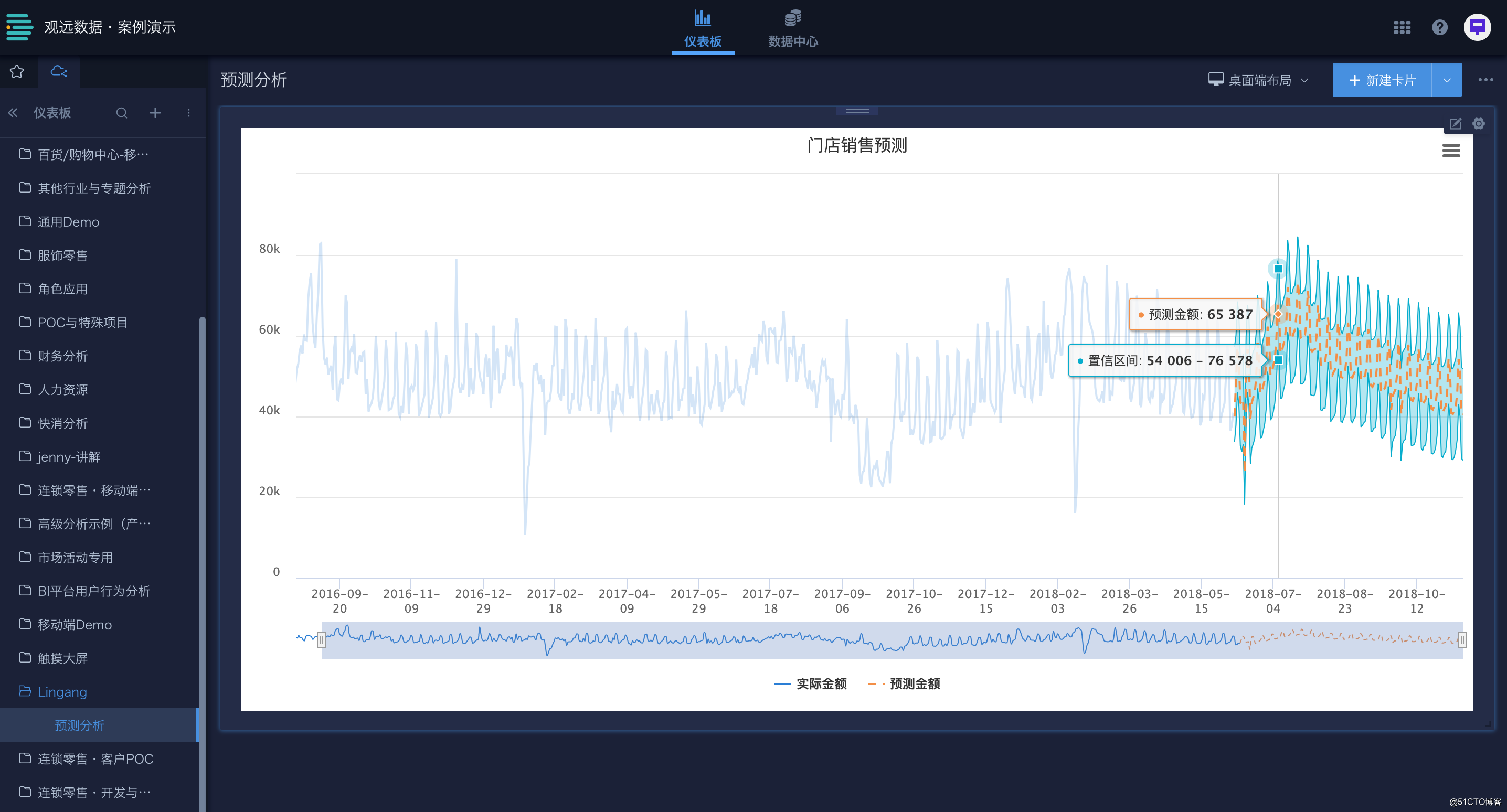
「AI预测引擎」数据展示
小结
本文给大家介绍了集成在观远BI平台内的「AI预测引擎」功能的架构设计与算法实现方案,感兴趣的同学欢迎点击文末阅读原文提交免费试用申请。
下一篇我们将给大家介绍更多观远数据在AI领域的实际落地案例与应用效果,欢迎持续关注!
转载于:https://blog.51cto.com/14211202/2376219
这篇关于智能分析平台叠加AI,观远数据行业首发「AI预测引擎」的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






