本文主要是介绍Representation Compensation Networks for Continual Semantic Segmentation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Representation Compensation Networks for Continual Semantic Segmentation
- Abstract
- 1. Introduction
- 2. Related Work
- 3. Method
- 3.1. Preliminaries
- 3.2. Representation Compensation Networks
- 3.3. Pooled Cube Knowledge Distillation
论文地址
github code
很久没有更新paper reading的内容了,最近发现Continual Semantic Segmentation这个领域有点意思,在这里记录一下。
Abstract
这篇工作研究Continual Semantic Segmentation问题,持续学习的意思是,以语义分割为例,我们经常训练好一个模型后,在后期 的使用中又添加了新的类别信息,这时如果重新和先前的类别一起训练,会耗费大量的时间和资源;如果直接用新的类别的数据集继续训练,会造成catastrophic forgetting的情况,也就是说old knowledge会被遗忘,new knowledge也学不好。本文提出了representation compensation (RC) module,这个模块由两个分支组成,其中一个是冻结的,另一个是可训练的。本文的另一个contribution是设计了一个pooled cube knowledge distillation strategy,在spatial和channel维度上对知识进行蒸馏,提高模型的鲁棒性。
1. Introduction
大概介绍一下Continual Semantic Segmentation,这里解释一些名词,比如Joint Training,也就是在拿到新的类别的训练数据时和先前的老类别训练数据融合在一起重新做训练。模型所具有的能力是,在得到新的类别的训练数据时,模型能很好地分辨旧类别和新类别,同时为了节省花费,新类别的训练数据只标注了新类别,其他类别(包括旧类别)都被归为背景。
本文的网络有两个branch,一个被frozen,保存old knowledge,另一个用来做训练,然后两个分支融合。
2. Related Work
3. Method
3.1. Preliminaries
对于本文一些符号的描述,大家可以阅读原文,这里不再赘述。
3.2. Representation Compensation Networks
对于常规的网络而言,结构都是一个3×3的卷积接一个normalization和激活函数,本文网络添加了一个平行的3×3卷积层+normalization结构,然后两个平行的层最后经过一个融合,然后再经过一个激活函数。

从图中可以看出,作者的意思是在step t-1,把平行的两个卷积层merge到一起,然后在step t中把merge的这部分冻结,用来保留old knowledge,然后用另外一个分支去学习new knowledge,那么这两个部分是怎么merge到一起的呢?文中给出了公式:

同时作者也用了一个drop-path策略:
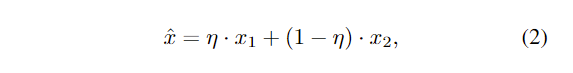
在训练的时候, η \eta η随机取0,0.5,1,对两个分支在激活函数前做融合,在测试的时候 η \eta η设置为0.5。
3.3. Pooled Cube Knowledge Distillation
知识蒸馏策略,用average pooling在空间和channel维度上对每个stage的特征图做处理,最终要求一个teacher model和student model的loss,说实话这里我不是很理解他的作用机理,可能要看看代码他的细节是如何的。
这篇关于Representation Compensation Networks for Continual Semantic Segmentation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!