本文主要是介绍.pcd格式的3维点云到图像平面的投影,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、关于标定文件
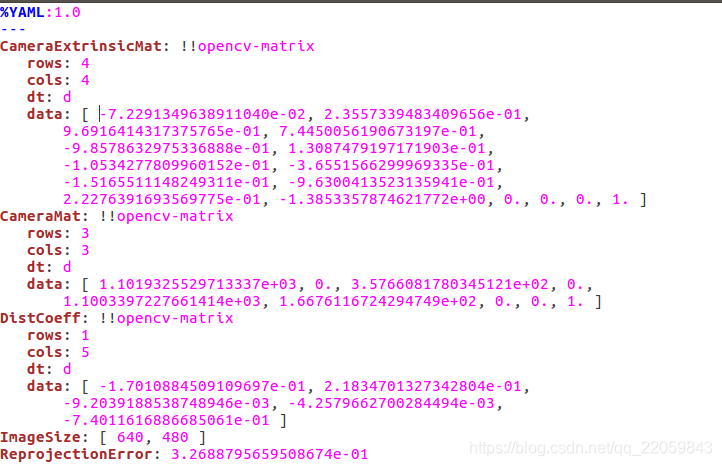
本人采用的是autoware的标定工具实现的标定,标定文件如下所示。此处应注意autoware的标定文件与其他一般性的标定文件相比的不同之处,autoware的标定文件的特殊性及其使用可参见我的其他博客。
2、利用openc的projectpoints函数实现坐标转换。
查询opencv文档中关于ProjectPoints2函数的说明,相关参数的解释部分展示如下
void cvProjectPoints2( const CvMat* object_points, const CvMat* rotation_vector,const CvMat* translation_vector, const CvMat* intrinsic_matrix,const CvMat* distortion_coeffs, CvMat* image_points,CvMat* dpdrot=NULL, CvMat* dpdt=NULL, CvMat* dpdf=NULL,CvMat* dpdc=NULL, CvMat* dpddist=NULL );
*object_points:*物体点的坐标,为3xN或者Nx3的矩阵,这儿N是视图中的所有所有点的数目。
*rotation_vector:*旋转向量,1x3或者3x1。由旋转向量通过罗德里格斯变换得到。
*translation_vector:*平移向量,1x3或者3x1。
[ f x 0 c x 0 f x c y 0 0 1 ] \left[ \begin{matrix} fx & 0 & cx \\ 0 & fx & cy \\ 0 & 0 & 1 \end{matrix} \right] ⎣⎡fx000fx0cxcy1⎦⎤
*intrinsic_matrix:*摄像机内参数矩阵A
*distortion_coeffs:*形变参数向量,4x1或者1x4,为[k1,k2,p1,p2]。如果是NULL,所有形变系数都设为0。
*image_points:*输出数组,存储图像点坐标。大小为2xN或者Nx2,这儿N是视图中的所有点的数目。
*dpdrot、dpdt、dpdf、dpdc、dpddist:*都为可选参数。
在python中调用该函数如下,注意代码各参数与上述说明的对应关系:
cv.ProjectPoints2(objectPoints, rvec, tvec, cameraMatrix, distCoeffs, imagePoints, dpdrot=None, dpdt=None, dpdf=None, dpdc=None, dpddist=None) → None
实例如下:
#-*- coding:utf-8 -*-
import pcl
import cv2 as cv
from pylab import *cloud = pcl.load('/home/song/pcl_test/test.pcd')
points_3d = []for i in range(0, cloud.size):x_raw = float(cloud[i][0])y_raw = float(cloud[i][1])z_raw = float(cloud[i][2])point_3d = []point_3d.append(x_raw)point_3d.append(y_raw)point_3d.append(z_raw)points_3d.append(point_3d)#输入projectpoints函数的各项参数数值。
cube = np.float64(points_3d)
rvec = np.float64([1.15230820843793, -1.268126207316489, 1.238632946715113])
tvec = np.float64([-1.6263959455325000e-01, -1.6604515286304664e-02, -9.2349015818599600e-01])camera_matrix = np.float64([[1.0251232727914867e+03, 0, 2.6218085751008294e+02],[0, 1.0180807639500672e+03, 2.0907527955373126e+02],[0, 0, 1]])distCoeffs = np.float64([-4.6155288063657413e-01, 2.2493781629153636e-01,2.5584176644194096e-03, 7.5604590879245655e-04, 3.1795661983727808e-01])point_2d, _ = cv.projectPoints(cube, rvec, tvec, camera_matrix, distCoeffs)
print(point_2d)
结果如下:
3、将二维坐标投影到图片上
这一步主要是对上一步得到的所有二维坐标进行过滤去除相机后方的点和超出图像尺寸外的点。再者就是利用scatter函数借助colormap对投影的点进行着色。完整代码如下:
#-*- coding:utf-8 -*-
import pcl
import numpy as np
import cv2 as cv
from PIL import Image
from pylab import imshow
from pylab import array
from pylab import plot
from pylab import title
from pylab import *
import matplotlib.pyplot as pltx=[]
y=[]
distance=[] #存放需要投影点转换成二维前的雷达坐标的x坐标(距离信息),以此为依据对投影点进行染色。
distance_3d=[] #存放转换前雷达坐标的x坐标(距离信息)。cloud = pcl.load('/home/song/pcl_test/test.pcd')
im = Image.open('/home/song/pcl_test/test.jpg')pix = im.load()
points_3d = []
# print('Loaded ' + str(cloud.width * cloud.height) +
# ' data points from test_pcd.pcd with the following fields: ')
for i in range(0, cloud.size):x_raw = float(cloud[i][0])y_raw = float(cloud[i][1])z_raw = float(cloud[i][2])point_3d = []point_3d.append(x_raw)point_3d.append(y_raw)point_3d.append(z_raw)if x_raw>0:points_3d.append(point_3d)distance_3d.append(x_raw)cube = np.float64(points_3d)rvec = np.float64([1.15230820843793, -1.268126207316489, 1.238632946715113])
tvec = np.float64([-1.6263959455325000e-01, -1.6604515286304664e-02, -9.2349015818599600e-01])camera_matrix = np.float64([[1.0251232727914867e+03, 0, 2.6218085751008294e+02],[0, 1.0180807639500672e+03, 2.0907527955373126e+02],[0, 0, 1]])distCoeffs = np.float64([-4.6155288063657413e-01, 2.2493781629153636e-01,2.5584176644194096e-03, 7.5604590879245655e-04, 3.1795661983727808e-01])point_2d, _ = cv.projectPoints(cube, rvec, tvec, camera_matrix, distCoeffs)m=-1
for point in point_2d:m=m+1x_2d = point[0][0]y_2d = point[0][1]if 0<=x_2d<=640 and 0<=y_2d<=480:x.append(x_2d)y.append(y_2d)distance.append(-distance_3d[m]*100)#数值取反是为了让colormap颜色由红到蓝显示而非由蓝到红RGB=pix[x_2d,y_2d]print('x,y,z,(r,g,b):',([x_2d,y_2d,distance_3d[m]],RGB))x=np.array(x)
y=np.array(y)
plt.scatter(x, y, c=distance, cmap='jet',s=4,marker='.')
plt.imshow(im)
plt.show()
结果如下:上面的为autoware投影的效果图,下面的为自己手动投影的效果图。

由于本次实验标定时抽取帧数较少,标定效果较差,本文重点在于功能的实现。另外对于点云的染色,采用目前的染色方案,效果不是很好,仍在研究,可自己设计。
这篇关于.pcd格式的3维点云到图像平面的投影的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




