
- paper:Gupta A , Johnson J , Fei-Fei L , et al. Social GAN: Socially Acceptable Trajectories with Generative Adversarial Networks[J]. 2018.
- code:https://github.com/agrimgupta92/sgan
概览
文章提出了一种采用GAN架构进行训练的轨迹预测模型,Generator由Encoder-Decoder结构组成,Discriminator由Decoder组成,旨在从合理性、多样性和预测速度等多方面对现有模型进行提升。
解决问题点
- 符合社会规范的轨迹:关注了预测生成轨迹在社会规则上的可行性,在定性评估上相交其他模型生成路径更合理。
- 多样化的轨迹:传统评估模型时采用ADE和FDE指标,优化模型的量化评估虽好,但其往往导致温和单一的预测轨迹,这与现实场景中轨迹的多样化情况不符。
- 预测速度提升:Vanilla LSTM vs SGAN vs Soicla LSTM :56x vs 16x vs 1x,速度有了明显提升。
模型创新点
- 提出新的损失函数-Variety Loss:借鉴于Minimum Over N损失函数,该损失函数鼓励Generator生成多条可行的路径。- 多样化轨迹
- 提出新的池化模型:模型中的池化用于LSTMs交换信息,SGAN将Social LSTM模型每步池化变为已知轨迹变化阶段仅一次池化(预测阶段默认每步都进行池化),同时将池化范围由固定局部范围拓展至全局所有行人。- 符合社会规范的轨迹,预测速度提升。
- 将GAN模型应用在轨迹预测的序列生成任务上:GAN在视觉处理上已有大量使用,但对于自然语言处理等序列模型涉及较少,主要是因为生成器向判别器传递输出的操作是不可微的。
阅读疑问
- 文中提到影响GAN在序列模型领域的应用原因是生成器向判别器的操作是不可微的,为何?
- SGAN生成器的最终输出是Decoder的隐藏状态经MLP(多层感知机)得到的二维坐标轨迹,但Social LSTM中预测二维坐标是基于隐藏状态满足二维高斯分布,SGAN没有采用这样的假设是因为该方法在反向传播时不可微,为何?
2019.8.22 更新
经过阅读一些知乎上的文章,对于上述两个问题有了初步的解答:
- GAN作者早起就已有提及,GAN只适用于连续型数据的生成,对于离散型数据效果不佳。
- GAN网络在训练生成器(Generator)时,损失函数是在判别器处计算的,从数据流向上是(数据) -> (生成器权重) -> (判别器权重) -> (Loss),只是生成器权重可训练而判别器权重不可训练。若有使用反向传播更新权重,则整个运算过程必须是可导的。
- 对于问题一:序列问题如NLP,常常在生成结果时有采样(sample)的行为,例如经过softmax得到词向量的概率,再将概率最大的置位1其余为0表示最终预测的单词,这个概率离散化的过程就是采样,是不可以从数学上求导的。
- 对于问题二:Social LSTM训练阶段直接基于二维高斯分布使用neg log-likehood计算损失,在生成阶段是基于二维高斯分布随机多次采样求均值得到最终位置。如要用到GAN网络上,传递给判别器(Discriminator)的数据须使用生成阶段的采样方法,但这种方法是不可导的。
link:https://zhuanlan.zhihu.com/p/29168803
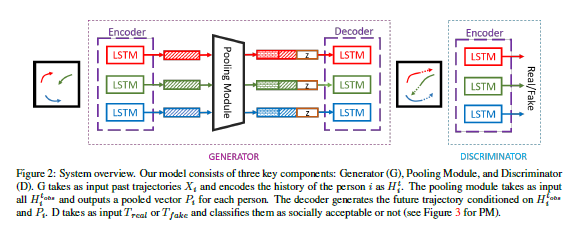
SGAN模型整体架构
GAN与cGAN
GAN中文又称生成对抗式网络,是Goodfellow等人提出的一种方式,旨在最大化训练数据的可能性下界,其中包含较多的数学原理与推导,笔者在此不具体叙述,只在实现层面简述GAN的几个特征:
GAN的组成部分:GAN由生成器和判别器组成,但并不要求生成器与判别器要由神经网络组成,也可以是其他的数学模型。因此GAN实际为一个训练的框架,其中实体因实际情况而异,例如在具体的Social GAN模型中,生成器和判别器均为神经网络,并在生成时采用Encoder-Decoder结构,判别时采用Encoder结构,核心属于序列模型。
\[\min_{G}\max_{D}V(G,D) = E_{x \sim p_{data}}[logD(x)]+E_{x \sim p(z)}[log(1- D(G(z)))]\]
cGAN:基础的GAN网络中,生成器生成的结果是基于随机初始化的输入向量(例如LSTM模型中,输入因为随机初始化的Hidden State),但是该网络的目标是基于已知的轨迹生成预测轨迹,因此生成器的输入还需根据已有信息合成。
下面的SGAN结构图中,在Generator中若要再细致一些的话,真正的生成器是由LSTN组成的Decoder部分,前段和中段的Encoder和Pooling Module实为为Decoder准备其初始化Hidden State的预处理部件。
- GAN的训练过程:GAN训练时的对象生成器和判别器,而测试时对象仅有生成器。
- 一次迭代(epoch/iteration)中,生成器和判别器将分别经过
g_steps和d_steps步训练,每次迭代中,先单独训练判别器的d_steps次,再单独训练生成器。 - 训练判别器:每步训练中,对于同一段已知路径,判别器将接受来自数据库和生成器的真轨迹与假轨迹,并对两个轨迹真假性做出评估,对抗损失函数将基于判别器对于两个轨迹的判断。
- 训练生成器:每步训练中,生成器将根据一段已知路径生成假轨迹,并交由判断器判断真假,对抗损失函数将基于判别器对假轨迹的判断。
- 一次迭代(epoch/iteration)中,生成器和判别器将分别经过
SGAN结构
Social GAN分为Generator和Discriminator:
Generator:生成器由Encoder、Pooling Module和Decoder组成。
Encoder使用LSTM序列模型实现,用于将行人的历史轨迹信息编码。最终输出的隐藏状态\(h_{ei}^{t_{obs}}\),将包含整个轨迹的信息。
\[e_i^t = \phi (x_i^t, y_i^t, W_{ee})\]
\[h_{ei}^t = LSTM(h_{ei}^{t-1}, e_i^t;W_{encoder})\]
Pooling Module使用max pooling实现,用于共享行人间信息。最终输出的是\(c_i^t\),作为Decoder输入的一部分。
\[P_i = PM(h_{e1}^{t_{obs}},h_{e2}^{t_{obs}},h_{e3}^{t_{obs}}...)\]
\[c_i^t = \gamma (P_i, h_{ei}^{t_{obs}};W_c)\]
*\(\gamma(.)\)是使用Relu的多层感知机(含有多个隐藏层的全连接层)
Decoder使用LSTM序列模型实现,用于生成预测的轨迹。不同于其他LSTM,其Hidden State初始值并不随机,而是由\(h_{di}^t = [c_i^t, z]\)拼接而成,前者为PM生成的结果,后者是加入的随机噪音以便生成多种轨迹。Decoder实际可被看做是带输入条件的生成器。
这其中需要:注意实验默认的Pooling Module在Decode阶段每步运行都会进行池化。
\[e_i^t = \phi(x_i^{t-1}, y_i^{t-1}, W_{ed})\]
\[P_i = PM(h_{d1}^{t-1},...,h_{dn}^{t-1})\]
\[h_{di}^t = LSTM(\gamma(P_i,h_{di}^{t-1}),e_i^t,W_{decoder})\]
\[(\hat{x_i^t},\hat{y_i^t}) = \gamma(h_{di}^t)\]
*\(\gamma(.)\)是使用Relu的多层感知机
Discriminator:判别器结构相对简单,由一个LSTM实现的Decoder和对[Decoder输出, 已知轨迹部分]进行多层感知的全连接层组成,最终输出对于路径真假性的评分。
模型特点与创新
损失函数
SGAN模型训练是分别针对生成器和判别器的,因而两部分的损失函数也需要分别定义,SGAN的损失函数基础量是Adversarial Loss,除此之外还附加了Variety Loss增加路径生成的多样性。
生成器
\[L_G = L_{adversarial}+L_{variety}\]
- \(L_{adversarial}\):惩罚“生成的轨迹被判别器判为假”:判别器对轨迹的scores与[0]向量的交叉熵。
- \(L_{variety} = \min_k||Y_i - \hat Y_i^{(k)}||_2\):这是基于\(L_2\)损失改进的,k指代Generator中在生成Decoder的初始隐藏状态时,\(z\)的随机取样次数。按原文来讲,该函数只惩罚\(L_2\)误差最小的预测路径,鼓励“hedge its bets”(多下注,留退路),生成多种可行的路径。(与MoN损失函数类似,但并未在此领域使用过)。
判别器
\[L_D = L_{adversarial}\]
- 惩罚“生成的轨迹被判别器判为真”:判别器对轨迹的scores与[0.7-1.2]向量的交叉熵。
- 惩罚“真实的轨迹被判别器判为假”:判别器对轨迹的scores与[0]向量的交叉熵。
池化模块
SGAN提出了异于Social Pooling的新型池化模型,这种池化模型将全局行人的信息纳入考量,并且源信息在LSTMs的Hidden States基础上增加了行人间的位置信息。后续的实验结果表明新的池化模型在量化指标上稍逊Social Pooing,但生成轨迹更符合社会规则。
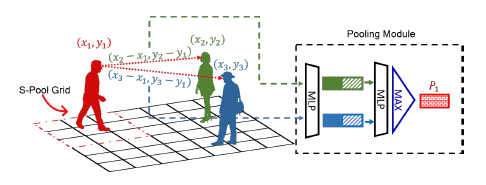
此处有几点需要注意:
- Pooing Module的输入由[Hidden States, Relative Location]两部分组成——每个LSTMs的隐藏状态和其他行人对目标行人的相对位置x,原文中在两处分别提到了这两个数据源,但并没有统一结合说明。
- 由于不同场景的人数不相同,模型为保证对池化结果维数相同,使用的是max pooling,对于每个行人(num_ped,N)的张量变为(1, N)。
- 实现代码中有关相对位置的计算和批量矩阵化运算的实现细节比较巧妙,如有需求请参考代码
model.py - PoolHiddenNet部分和实验代码解析。
其他
路径数据相对VS绝对:虽然文章中仅在Pooling Module部分重点提出过使用相对位置(不同人在同一时刻之间),但经过通过阅读实验代码,生成器从输入到最终的输出,都是相对位置(同一人某时刻相较于前一时刻的位置变化),而绝对位置虽传入模型但仅作为计算相对位置、合成绝对位置、计算grid等功能。
生成器输出:在Social LSTM中,作者基于LSTM最终输出的隐藏状态呈现位置信息的二维高斯分布,并以此预测位置和计算损失;但在SGAN中,文章以该方法在反向传播时不可微的原因使用多层感知机直接预测二维目标,并用\(L_2\)计算损失。
模型评估与实验
实验数据库:ETH和UCY,4种场景,1536条行人轨迹,未经归一化处理。
评价指标:ADE - Average Displacement Error,FDE - Final Displacement Error。鉴于SGAN生成路径的多样性,评价时将对一条路径的多种预测取最小误差作为结果。
无关变量控制
- 预测时间:输入3.2秒,预测3.2秒或4.8秒。
- SGAN实验模型的编号为SGAN-kVP-N:kV表示训练时使用Variety Loss的生成次数(1表示没有使用Variety Loss);有无P表示是否使用新型池化结构;N表示计算Error前,对于一条已知路径生成了多少条备选路径。
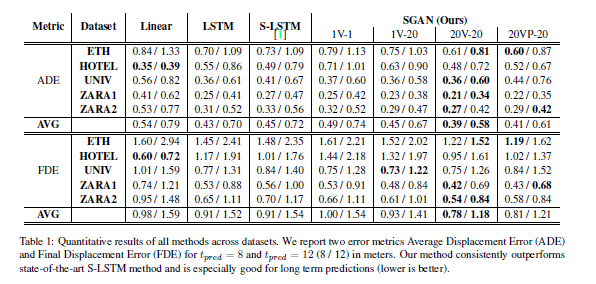
定量实验结论
全场最佳:SGAN模型编号SGAN-20V-20整体表现最佳,SGAN-20VP-20在量化结果上稍逊前者(后文解释)。
多样化输出显著,模型对噪音敏感:若在评估时只取模型随机生成的一个轨迹,那么量化指标结果差于Social LSTM,这表示模型对噪音\(\alpha\)是敏感的。同时,随着评估参考轨迹的数量上升,评估结果也显著提高,最高在\(k=100\)(100条轨迹中选误差最小的)时能够降低33%的错误率。
速度提升显著:得益于池化结构简化,SGAN生成速度可达Social LSTM的16倍。
注:Social LSTM整体表现比Vanilla LSTM差,原文章的实验结果使用真实数据训练+加强数据测试的策略无法复现。
定性实验结论
虽然具有新型池化结构的模型比原池化的模型的数据表现略逊一筹,但将轨迹数据可视化后,新型池化的预测要比原模型更符合社会规则性。文中特别提取几种常见社交场景进行对比,具体请参见原文:
- 冲突场景:一对一相遇、一对多相遇、追尾式相遇、带有角度的侧面相遇。

- 人群聚合场景、人群回避场景(人人间互相回避)、人群跟随场景









